作者:Yurong Wu1、 Yan Gao、 Bin Benjamin Zhu 等
单位:中国科学院软件研究所、中国科学院大学、Microsoft
来源:ArXiv
时间:202410
研究背景与动机
模型能力天花板由 prompt 决定;工业界(Copilot、New Bing)每天上亿次调用,prompt 质量 = 用户体验 = 收入
手工调 prompt :
依赖“提示词工程师”,成本高、不可复制;复杂任务(医疗、法律)需要领域知识,对“稳”和“可解释”更敏感,普通人难写出专家级 prompt

设计一种同时具备三项特性的优化器:
低漂移 – 修正错误的同时,守住已正确样本
可解释 – 人类能读懂“为什么改、怎么改”
快收敛 – 用尽可能少的 API 调用找到好 prompt
评估场景
覆盖推理、NLU、医学、工业搜索共 6 个任务
全部零样本,不允许任何训练或梯度更新
量化漂移指标
为了在迭代提示优化期间,评估新提示如何影响以前成功和失败的案例,入了两个额外的指标:
不良校正率 (ACR) 和有益校正率 (BCR)
ACR = 原本对→错 / 原本对
BCR = 原本错→对 / 原本错
目标:max BCR − min ACR
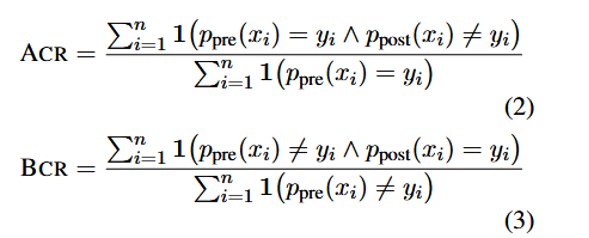
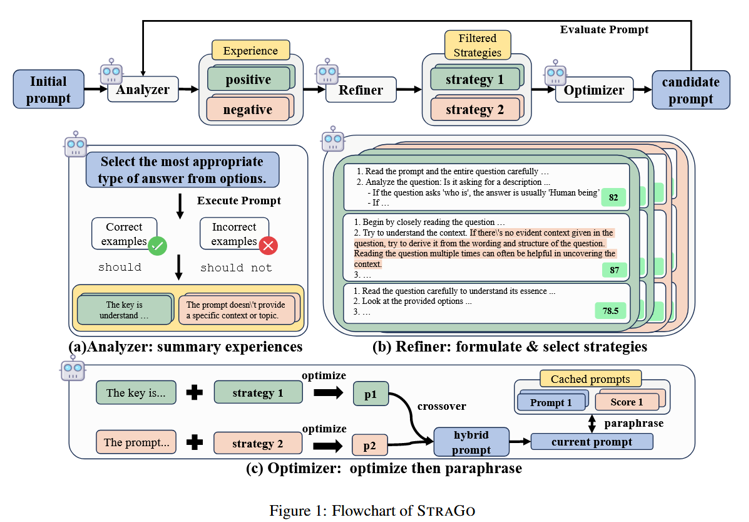
StraGo
- Analyzer(分析器)
从当前验证集中分出“答对”和“答错”的样本。
各采样 3 个,分析其成功/失败原因,分别生成 3条“经验”(正/负)。 - Refiner(策略生成器)
针对每条经验,用 LLM 生成 3条“改进策略”。
用另一个 LLM 打分,选最优正负策略各一条。 - Optimizer(优化器)
用策略分别改写 prompt:正经验 → 保留优点的 prompt,负经验 → 修复错误的 prompt。
交叉融合两组 prompt(类似遗传算法),生成候选 prompt 5条。
用验证集评估,选一条最优 prompt 进入下一轮。
达到预设轮数或验证集准确率不再提升。
实验
•baseline:CoT, APO, OPRO, EvoPrompt
• 数据集:13 个任务,含 GSM8K, MMLU, BBH, Yelp, WebNLG 等
•温度=0,top-5 候选取最佳
| 任务 | 类型 | 样本量 | 初始 prompt |
| BBH-5子集 | 推理 | 50 val / 200 test | Let’s think step by step |
| SST-5 | 情感 | 400 / 1450 | 选最准确情感 |
| TREC | 问答类型 | 300 / 1384 | 选最适当答案类型 |
| MedQA | 医学单选 | 300 / 1173 | 用医学知识… |
| MedMCQA | 医学多选 | 400 / 1500 | 同上 |
| Personal-Intent | 工业搜索 | 50 / 231 | 内部模板 |
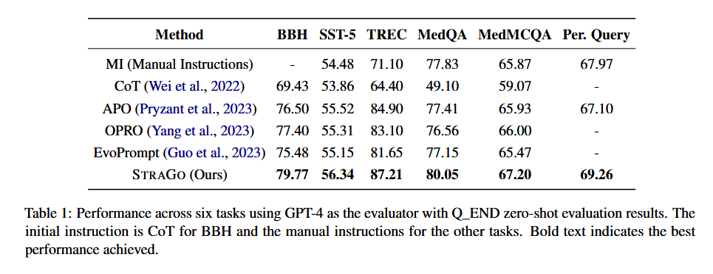
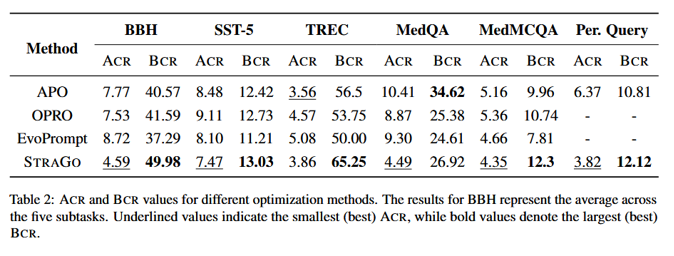
strago在所有任务中准确率都有所提升,在4/6 任务同时拿到 最低 ACR + 最高 BCR
成本分析
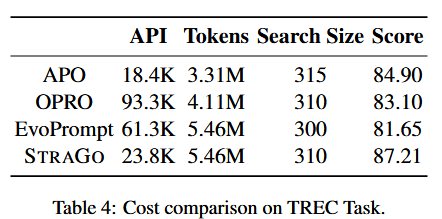
· API 次数 < APO/OPRO
· token 高(策略+经验长)
· 性价比:每 1% 提升 ≈ 2.8 K 次调用
核心内容总结:
现有的提示优化方法存在提示漂移,即指在优化过程中,新提示可能在解决某些失败案例的同时,无意中破坏了之前成功的案例。为解决此问题提出StraGo。
通过分析成功和失败的案例来识别实现优化目标的关键因素,并利用这些洞察来制定具体的、可执行的策略,为提示优化提供详细的、分步骤的指导。
三个主要步骤:分析器(Analyzer)、精炼器(Refiner)和优化器(Optimizer)。分析器同等重视正确和错误案例的分析,精炼器基于这些分析生成可执行的策略,优化器则将这些策略应用于提示的优化。利用prompt在实际使用中的结果同时守门+修错,保留正面经验,收集负面影响,同时形成正负两种策略,实现更低漂移,更快收敛,少盲目探索。
思考:
根据实验结果,strago依赖强指令模型,使用能力较低的模型时提升准确率不如能力强的模型。
可使纯文本prompt向多模态扩展,图像+文本,利用这种策略方法优化对多模态大模型的指导。