来源:CVPR 2025
作者:Yuncong Yang, Han Yang, Jiachen Zhou, Peihao Chen, Hongxin Zhang, Yilun Du, Chuang Gan
单位:UMass Amherst
一、背景
具身智能体在三维环境中执行任务(如导航、问答、操作)时,需要长期、稳健的场景记忆来支持探索与推理。而现有方法主要有两类:
- 对象中心的三维场景图:以对象和文本化关系建模,结构紧凑,但过度简化空间关系,难以回答涉及方位或空间细节的问题。
- 稠密三维表示(点云/神经场):信息全面,但计算代价高、难以扩展,也缺乏对未探索区域的建模能力。
因此,如何兼顾表达力、效率与可扩展性,并支持主动探索,是亟需解决的问题。
二、贡献
本文提出了3D-Mem,一种新型三维场景记忆框架,主要贡献包括:
- 记忆快照(Memory Snapshots):
- 将多视角图像作为记忆单元,直接包含对象及其背景环境信息。
- 相比场景图文本描述,更直观、信息更完整。
- 前沿快照(Frontier Snapshots):
- 对未探索区域进行快照表示,引导智能体基于“前沿”进行主动探索。
- 增量构建机制:
- 支持在长期探索中实时更新记忆,保持系统可扩展性。
- 记忆预筛选:
- 在推理前过滤无关快照,仅保留与任务相关的图像,提升效率。
- 全面验证:在主动问答、情景问答和终身导航三大任务上,均显著优于现有方法。
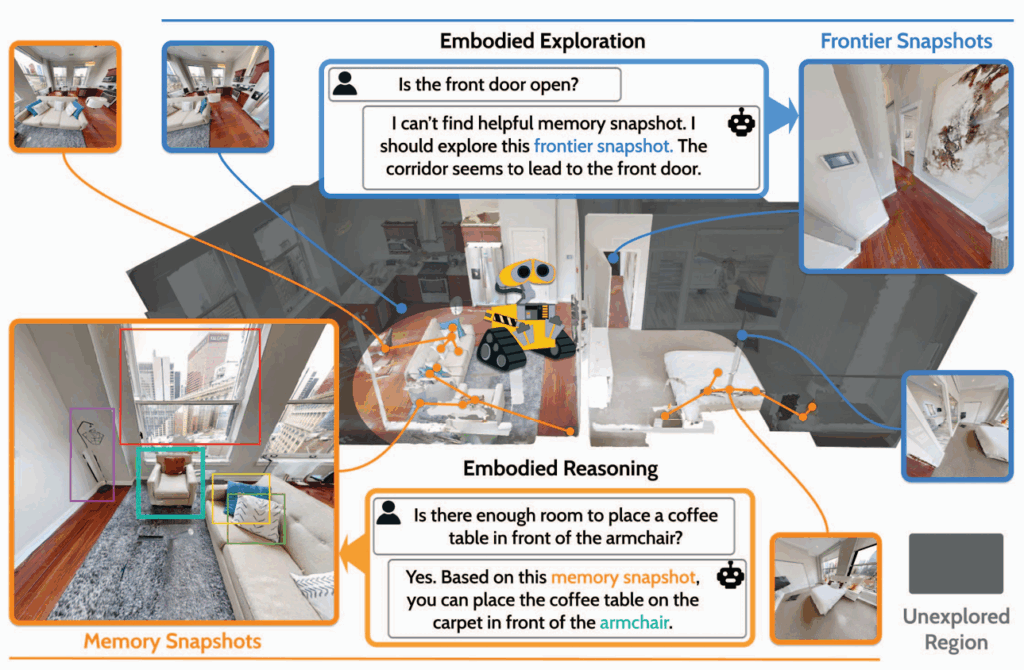
三、方法
3D-Mem 的核心思想是:用信息丰富的多视角图像快照来表示场景的已探索和未探索区域,并通过增量更新与高效检索支持长期探索与推理。
方法分为三个核心模块:记忆构建,前沿探索,记忆检索
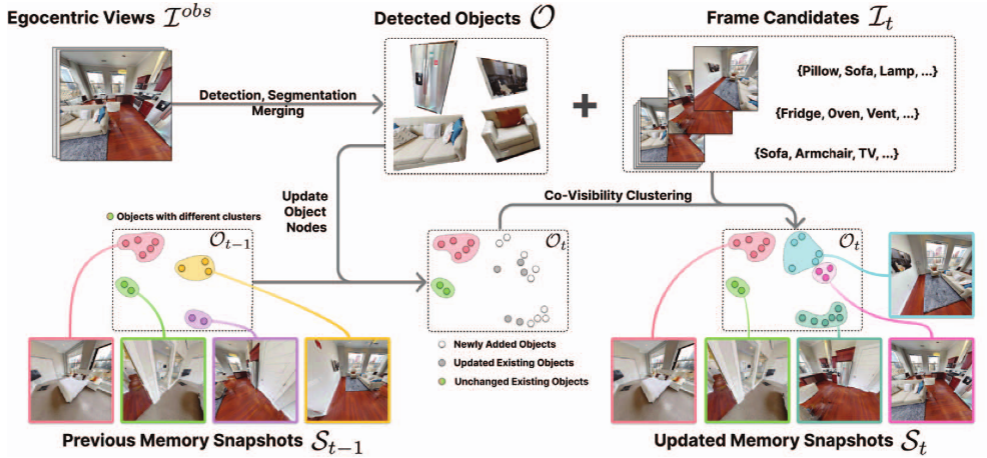
1.记忆构建
输入RGB-D图像流和相机位姿,从原始观测中生成紧凑而完整的记忆快照集合
- 对象检测与集合构建
- 使用检测器提取可见对象,并通过相机位姿将其映射到统一的三维空间。
- 将所有对象加入一个对象集合。
- 共视聚类
- 不同观测中,同一组对象往往会共同出现。
- 通过对象集合的共视关系对观测进行聚类,每个簇代表一组具有空间相关性的对象。
- 快照选择
- 对每个簇,从观测图像中选择最能代表该簇的图像作为记忆快照。
- 每个快照不仅包含目标对象,还保留其周边环境信息,提供房间尺度的空间线索。
2.前沿探索
现有记忆方法往往忽视未探索区域,3D-Mem 引入前沿快照来解决这一问题。
- 前沿检测
- 在场景占据图中,找到已探索区域边界处的“前沿区域”。
- 前沿快照构建
- 为每个前沿点分配一个候选观测位姿。
- 从该位姿生成一张“预览式”的图像 → 前沿快照。
- 表示潜在的未知区域。
- 增量更新机制
- 随着探索推进:
- 更新对象集合(加入新检测对象)。
- 更新记忆快照(新增或替换更优视角)。
- 更新前沿快照(移除已探索的,加入新的前沿)。
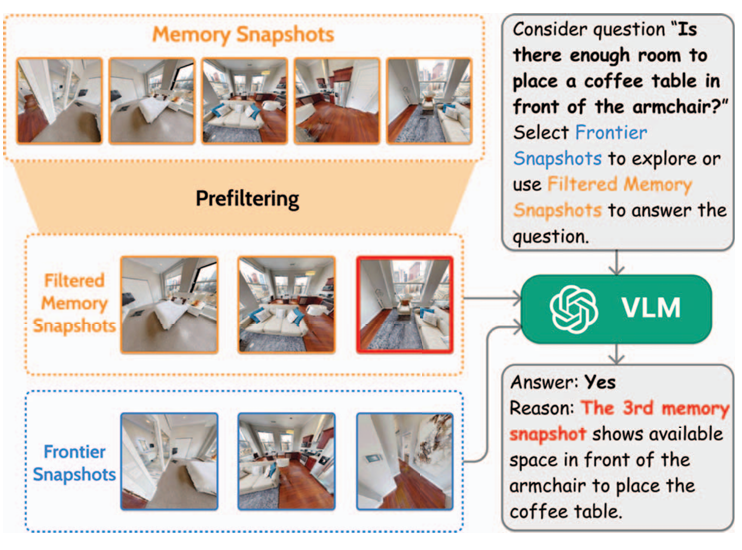
3.记忆检索
长期探索会产生大量快照,文章中通过预筛选机制高效利用快照。
- 预筛选
- 针对任务目标(如问题关键词、导航目标类别),筛选相关快照。
- 避免向 VLM 输入过多无关或冗余图像。
- 快照输入 VLM
- 具身问答:快照直接作为 VLM 输入,推理空间关系与语义信息。
- 导航任务:裁剪快照中目标对象的图像,用作匹配目标的线索。
四、实验
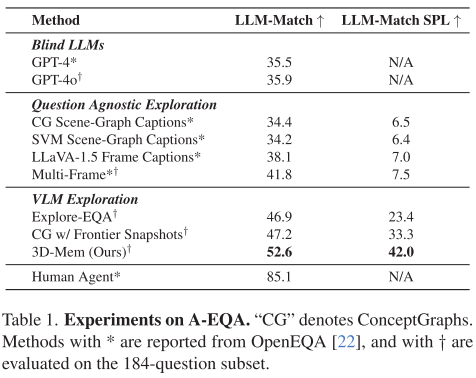
作者在三个任务中评估 3D-Mem:
1.主动具身问答
- 要求智能体探索未知场景并回答问题。
- 结果:3D-Mem 在准确率与效率上均显著优于 Explore-EQA 与 ConceptGraph。
- 优势来源:快照包含更灵活的信息,避免了对象裁剪和文本描述的局限。
2.情景记忆问答
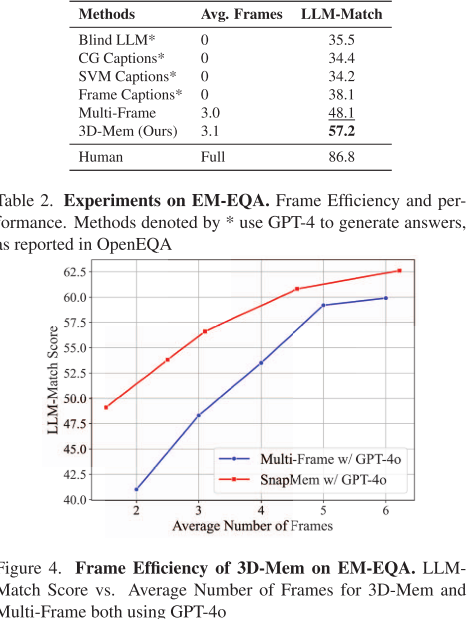
- 给定完整轨迹,无需探索,仅基于记忆回答问题。
- 结果:3D-Mem 与 Multi-Frame 都优于基于文本的场景表示;同时,3D-Mem 在帧效率上更优,证明其紧凑性。
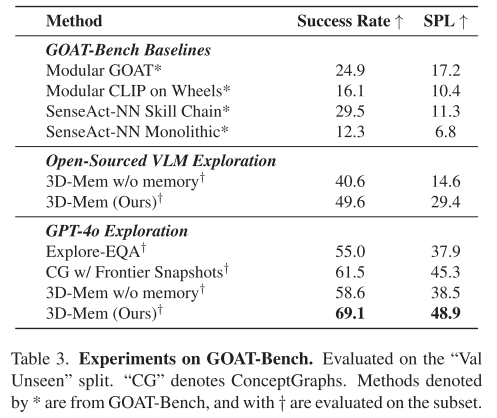
3.GOAT-Bench(终身导航基准)
- 要求智能体在长期任务中依次导航到不同目标。
- 结果:3D-Mem 在成功率和 SPL(路径效率)上均领先。
- 消融实验:移除记忆后性能明显下降,验证了长期记忆的重要性。
五、结论
本文提出的3D-Mem框架通过多视角快照统一表示已探索与未探索区域,结合增量构建与预筛选机制,在效率与表达力之间取得平衡。
- 它能支持智能体进行主动探索与推理;
- 在多种任务中显著优于现有场景表示方法;
- 为具身智能体的终身学习与自主探索提供了新思路。