作者:Luo Ling, Bai Qianqian
单位:西南财经大学
来源:arxiv Artificial Intelligence
时间:2025.04.09
一、研究背景
研究方向为视觉-语言导航(Vision-and-Language Navigation, VLN),即智能体通过视觉输入和自然语言指令在复杂环境中完成导航。虽然在模拟环境中已有显著进展,但迁移到现实环境时,常出现空间幻觉(spatial hallucination)——智能体对环境的感知与真实不符,导致路径选择错误、碰撞或迷失方向。现有方法依赖单一提示系统或单一地图建模,缺乏多层次环境建模和动态更新能力,难以应对连续空间和动态障碍。
二、核心内容
论文提出 BrainNav 框架,一种基于生物认知理论的空间导航方法:
- 借鉴生物的 认知地图理论 与大脑多区域协作机制。
- 设计了 双地图(坐标图 + 拓扑图) 与 双方向(绝对方向 + 相对方向) 策略。
- 引入五大类“仿生模块”:海马体记忆、视觉皮层感知、顶叶空间建构、前额叶决策、中小脑运动执行。
- 框架与大语言模型(如 GPT-4)兼容,支持零样本(zero-shot)在现实环境中导航。
三、核心框架贡献
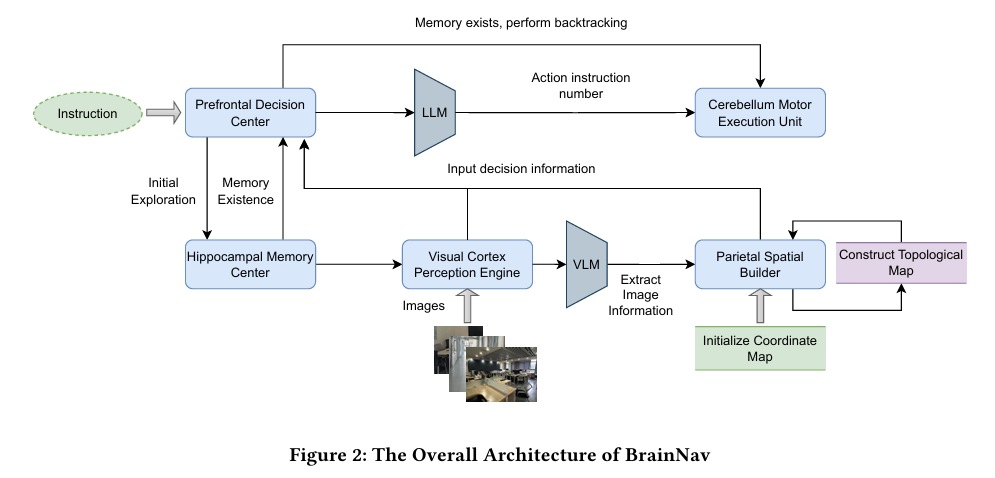
BrainNav 的五大模块对应大脑功能:
- Hippocampal Memory Center(海马体记忆中心):历史轨迹存储与回溯,支持记忆召回。
- Visual Cortex Perception Engine(视觉皮层感知引擎):基于 LLM 分析场景图像,识别障碍物、可行走路径、地标。
- Parietal Spatial Builder(顶叶空间建构器):构建双地图(精确位置的坐标图 + 空间连通性的拓扑图)。
- Prefrontal Decision Center(前额叶决策中心):高层规划与决策,整合感知、地图和记忆信息,输出下一步动作。
- Cerebellum Motor Execution Unit(小脑运动执行单元):将高层指令转化为具体机器人动作,结合相对与绝对方向减少幻觉。
四、实验部分
实验设置:
- 使用 AgileX Limo PRO 移动机器人,仅依赖 RGB 摄像头(不使用深度相机、LiDAR 等)。
- 在现实室内场景(走廊、会议室、实验室、开放空间)进行测试。
- 对比基线:MapGPT(基于模拟环境的方法)。
评估指标:轨迹长度 (TL)、导航误差 (NE)、成功率 (SR)、路径效率 (SPL)。

结果:
- 简单指令任务(目标搜索、路径导航):BrainNav 成功率远高于 MapGPT(如目标搜索 SR = 88% vs. 0%)。
- 复杂任务(多步导航、多目标搜索、动态障碍规避):BrainNav 在动态障碍规避中成功率达到 87.5%,整体显著优于基线。
- 回溯率:BrainNav 的回溯率仅 10%(MapGPT 为 75%),且成功修正率高达 73.3%。
- 案例研究显示,BrainNav 能在真实场景中顺利完成多阶段导航。
五、总结
- 贡献:
- 提出了首个基于生物认知理论的分层决策导航框架 BrainNav。
- 设计了双地图 + 双方向机制,有效缓解空间幻觉问题。
- 在现实零样本环境下实现了超越现有 SOTA 的性能。
- 局限性:
- 多目标 (>3) 的复杂指令成功率下降明显。
- 在动态障碍场景中的长期稳定性仍需改进。
- 未来方向:增强多模态语义理解,优化动态环境下的路径规划与目标跟踪。