作者:Md Mahadi Hasan Nahid,Sadid Bin Hasan;
来源:arxiv
单位:University of Alberta
时间:2024年12月
背景
随着机器学习(ML)在各领域的广泛应用,数据隐私问题日益突出。尤其是在处理包含个人敏感信息的数据时,如医疗记录、金融数据等,必须遵守GDPR、CCPA等隐私保护法规。传统的匿名化方法往往无法在保护隐私的同时保持数据的实用性。差分隐私提供了一种严格的数学框架,通过在数据中注入噪声来防止个体记录被推断出来。另一方面,大语言模型在生成高质量合成数据方面展现出强大能力,但其在隐私保护方面的应用尚未充分探索。
论文核心贡献
论文研究了将LLM用于指导具有DP特性的合成数据生成,以在隐私和效用之间取得平衡
1.提出SafeSynthDP框架:首次将差分隐私机制(拉普拉斯和高斯噪声)集成到LLM驱动的合成数据生成流程中,无需训练LLM,降低计算成本。
2.系统评估隐私–效用权衡:通过大量实验量化不同ε值(隐私预算)对合成数据效用(如分类准确率)的影响。
3.多模型架构验证:在传统ML模型(如MNB、SVM)和深度学习模型(如GRU、LSTM)以及LLM的上下文学习(ICL)任务上全面评估合成数据的实用性。
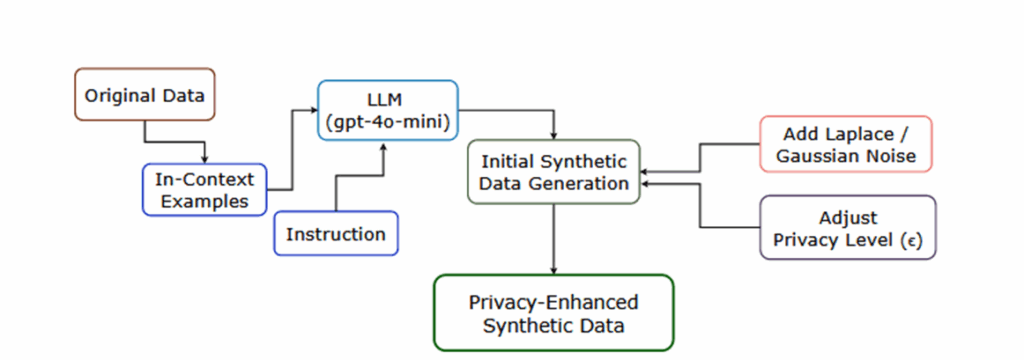
方法框架
论文提出的合成数据生成方法,主要分为四个模块
1.数据示例抽取:从原始数据集中抽取少量示例,包含文本和类别标签。
2.基于提示的合成数据:构造 prompt,将示例放入输入,引导 LLM 生成新的样本;
3.生成差分隐私噪声:在生成数据的统计特征层面(如词频、嵌入、标签比例)注入 Laplace 或 Gaussian 噪声
4.注入超参数调优:使用多种分类模型(Naive Bayes、SVM、GRU、LSTM)在合成数据上训练并测试
实验
实验设置:
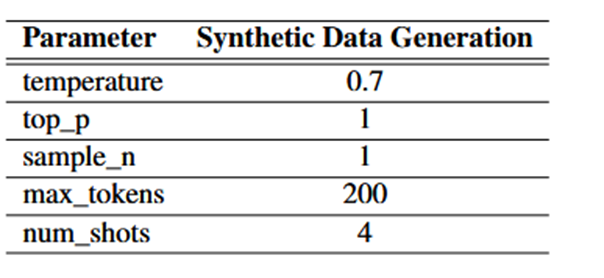
论文实验旨在评估差分隐私增强合成数据在传统ML任务的效用,同时需要考虑数据隐私,同时论文实验考虑了对于上下文学习ICL任务中的效用问题,同时在附录中讨论了超参数的设置问题
数据集:AGNews的子集
模型选择:用于比较合成数据在各个方面的表现程度(统计特征、时间模式、上下文关系)
MNB:一个依赖于单词频率计数的简单模型。如果MNB在合成数据上表现合理,则表明核心统计特性得以保留
SVM:SVM可以有效地处理高维特征空间。它在合成数据上的表现表明了基本的判别特征是否保持完整。
GRU/LSTM:这些循环神经网络利用顺序和上下文信息。如果这些模型显示出合理的性能,这意味着合成数据保留了更复杂的模式,而不仅仅是基本的词频。
ICL:通过在上下文学习中使用合成数据作为演示示例进行测试,我们评估合成数据是否可以指导LLM进行正确的分类,反映更高层次的语义连贯性。



实验分析
论文的实验分析主要分为三部分:机器学习模型效用比较、LLM上下文学习效用表现、隐私和效用权衡评估。
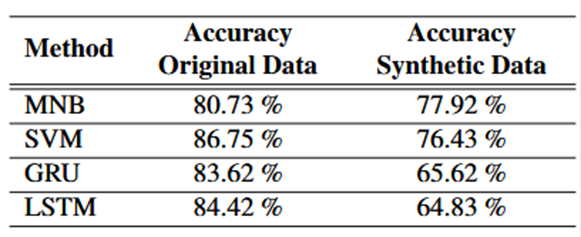
机器学习模型评估效用比较,在原始AGNews数据集或基于DP的合成数据上训练的每个模型的准确性。论文表格显示传统模型如MNB和SVM性能下降较小(3%-10%),但GRU/LSTM下降显著(约19%)。说明方法能保留基础统计特征,但复杂语义模式受损。可以用“实用但复杂模型有损”来概括。
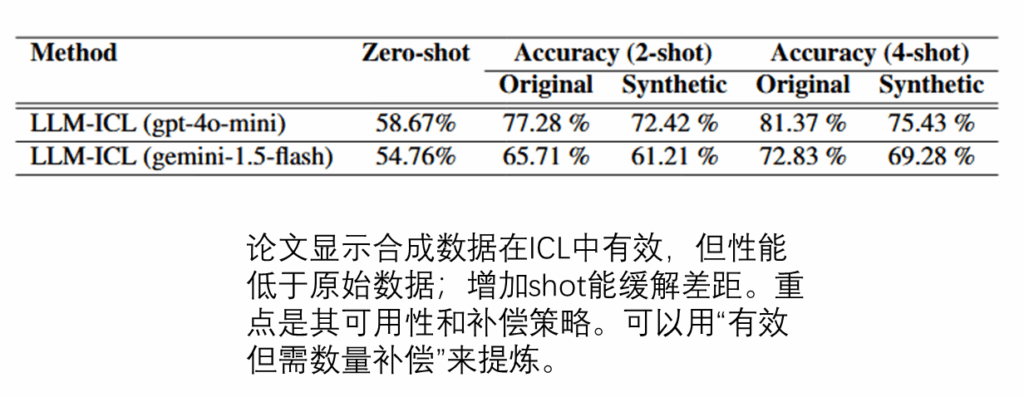
LLM上下文学习表现,实验比较不同大模型架构中合成数据的表现情况,主要是gpt4o-mini和gemini-1.5-flash,采用zero-shot,two-shot和four-shot场景区分。论文显示合成数据在ICL中有效,但性能低于原始数据;增加shot能缓解差距。重点是其可用性和补偿策略。可以用“有效但需数量补偿”来提炼。
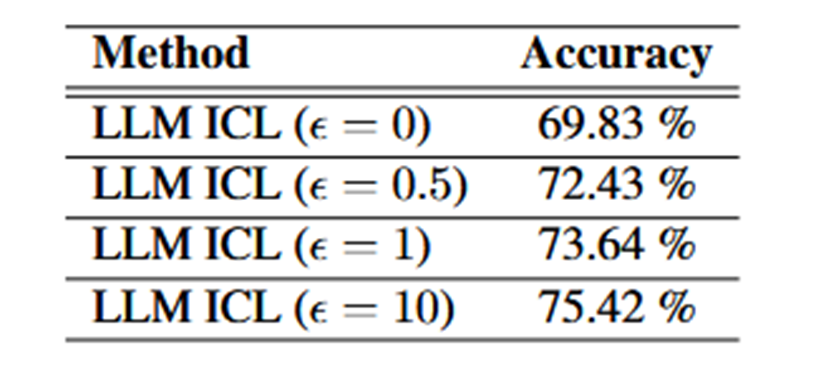
效用和隐私权衡显示,ε 越小(更强隐私),准确率越低;ε 越大(弱隐私),准确率上升。论文给出了 ε 在 {0,0.5,1,10} 时的典型准确率点
总结
本论文提出了SafeSynthDP框架,通过将差分隐私(DP)噪声机制与大语言模型(LLM)的上下文学习能力相结合,成功生成了兼具实用性与隐私保护的合成文本数据;实验表明,该合成数据能有效支持传统机器学习模型并适用于LLM的上下文学习场景,虽在保留复杂语义模式上存在不足且性能随隐私增强而下降,但通过调整隐私预算ε和示例数量能在隐私与效用间实现灵活权衡,为在严格合规要求下进行数据驱动研究提供了可行的解决方案。
启发
1.论文提出的方法框架是针对于LLM来合成具有DP特性的数据集,通过提示的方式来获取具有统计特性的合成数据捕获语言模式和主题分布。同时论文在合成数据的模块上面添加了隐私保护,用于平衡效用和隐私保护,对于研究方向可以参考采用LLM来生成数据后添加一个隐私层来隐藏原始数据的隐私信息
2.论文中主要提到的llm是gpt4mini和gemini-1.5-flash,在模型的选择上可以添加多个模型进行比较实验,同时论文采用的数据集数据量大概2000条,对于dp特性的保证不够严谨,可以通过更大的数据集进行比较,同时不同的ML任务也可以纳入讨论