作者:Ronghua Shang;Jingyu Zhong;Weitong Zhang;Songhua Xu;Yangyang Li
单位:Key Laboratory of Intelligent Perception and Image Understanding of Ministry of Education, School of Artificial Intelligence, Xidian University, Xi’an, Shaanxi 710071, China
来源:IEEE
发表日期:2024.4
一、背景动机
1.随着信息技术的发展,数据易得但多标签数据的标签概念需在高维空间中描述,高维度已成为多标签学习的关键挑战
2.多标签数据中存在大量无关或噪声特征与标签,严重削弱模型的准确性与泛化能力,甚至导致过拟合
3.现有标签空间降维方法往往无法消除潜在子标签间的冗余信息,阻碍真实标签关联的捕捉,从而制约特征选择效果
研究目标:该研究的主要目标是设计一种能自动发现并剔除多标签数据中冗余与噪声信息的特征选择方法,从而在保留标签内部关联结构的前提下,挑出最具判别力的特征子集。通过构建共享的正交潜在子标签空间,不仅能够更精确地捕捉标签间的真实关系,还能大幅降低数据维度,提升后续模型训练与预测的效率与准确性。
二、核心内容
SLOFS整体架构:
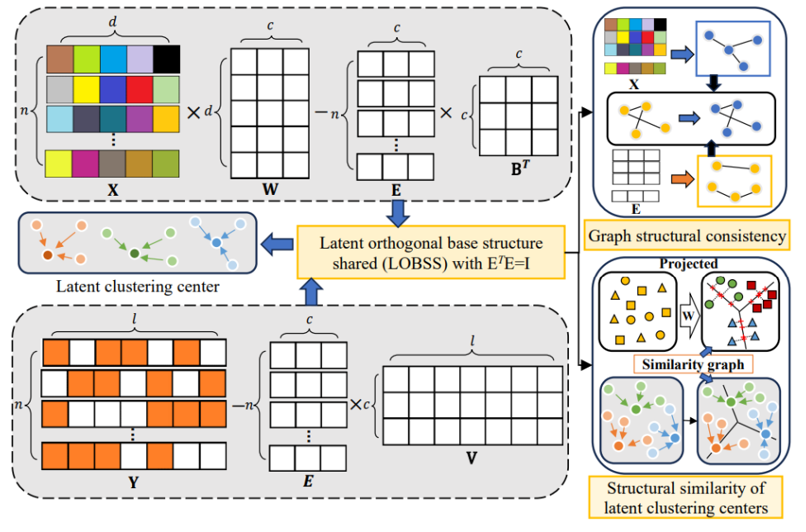
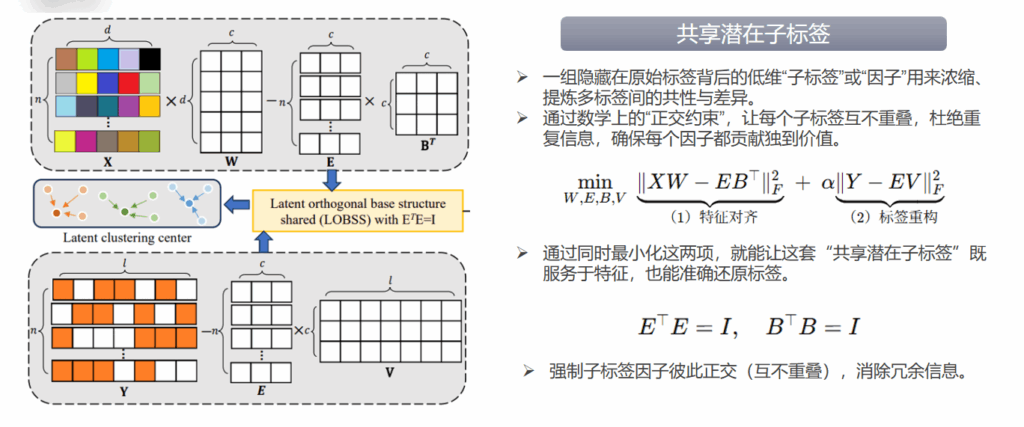
1.共享潜在子标签结构
2.双图一致性正则化

3.动态子标签图重构 & 交替优化算法

三、实验评估
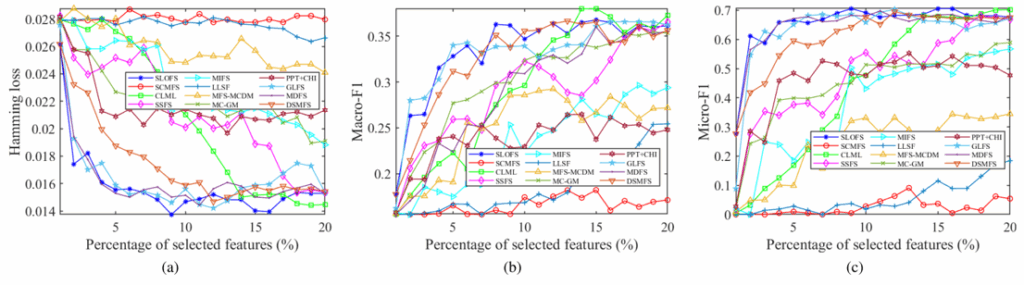
在不同特征选择比例(1%–20%)下,SLOFS 与 11 种主流多标签特征选择方法在(a)Hamming Loss、(b)Macro-F1、(c)Micro-F1 三项指标上的性能对比。
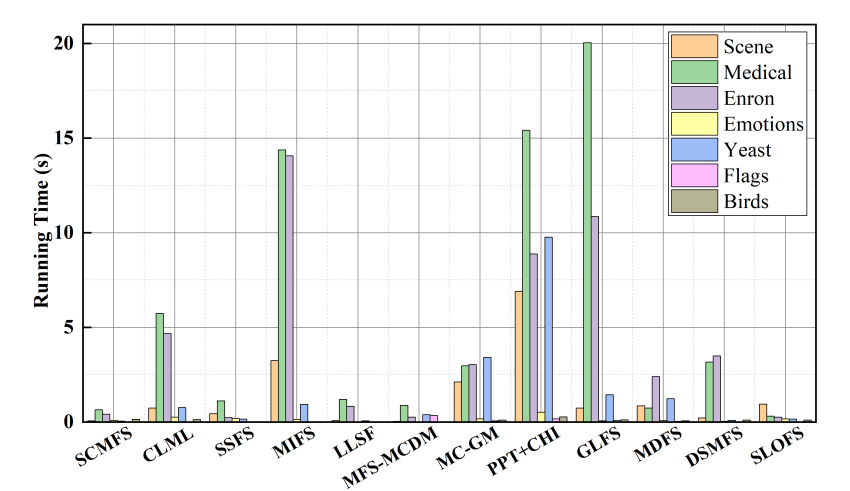
各方法在 Scene、Medical、Enron、Emotions、Yeast、Flags 与 Birds 七个数据集上的平均运行时间(秒)对比。
四、总结思考
论文总结:
1.本论文针对高维多标签数据中标签噪声、冗余与标签关联难以挖掘的问题,提出了一种名为 SLOFS(Shared Latent Orthogonal Feature Selection)的方法。
2.该方法通过构建一个共享潜在子标签结构(LOBSS)和双图一致性正则化,并辅以动态子标签图重构,实现了特征与标签在同一低维潜在空间中的协同优化。
3.作者在此基础上设计了一个基于辅助函数与 Stiefel 流形的交替优化算法,证明了算法的单调下降与收敛性,并在 18 个多标签数据集上与 11 种主流方法对比验证了 SLOFS 在 Hamming Loss、Macro-F1 和 Micro-F1 上的显著性能提升。
启发思考:
1.图结构辅助校正:构建标签之间的相似度图(基于共现、语义嵌入等),用来发现标签库里的“盲区”或“冲突点”。标注新数据时,按照它与已有标签的相似关系,提示标注员参考上下文,减少漏标和错标。
2.动态迭代与反馈:像“动态子标签图重构”那样,不断根据新标注的数据重新挖掘标签间关系,适时合并或拆分子标签。建立持续监测机制,对标注一致性和标签使用频次进行指标监控,定期优化标签库结构。