来源:ACM SIGIR
作者:Zhu Sun, Hongyang Liu等
单位:A*STAR Centre for Frontier AI Research, Singapore、新加坡科技设计大学等.
发表时间:2024 年 6 月
研究背景
- 意图感知推荐系统(ISR)的需求
会话推荐系统的目标是根据用户在一个短暂的匿名会话中的行为来预测用户可能感兴趣的下一个项目。
实际场景中,用户在同一会话内可能有多个并行的意图。
ISR即通过识别和建模用户在单次会话中可能的多重意图来提高推荐的准确性和多样性。
- LLM的应用
在会话推荐系统中,LLM可以提供以下优势:
推理能力:LLM具备强大的推理能力,可以帮助理解和建模用户在每个会话中的多重意图。例如,它们能够从用户的多个行为中推测出背后的不同目标。
语义理解:LLM不仅仅依赖于单一的意图标签,而是能够在语义层面上推断用户的真实需求。这使得它们能更好地理解用户复杂的购买决策过程。
这篇文章提出:LLM4ISR(Large Language Models for Intent-Driven Session Recommendations)
结合了LLMs的推理能力和优化机制,从而能够更好地捕捉和理解用户的多重意图。
LLM4ISR方法
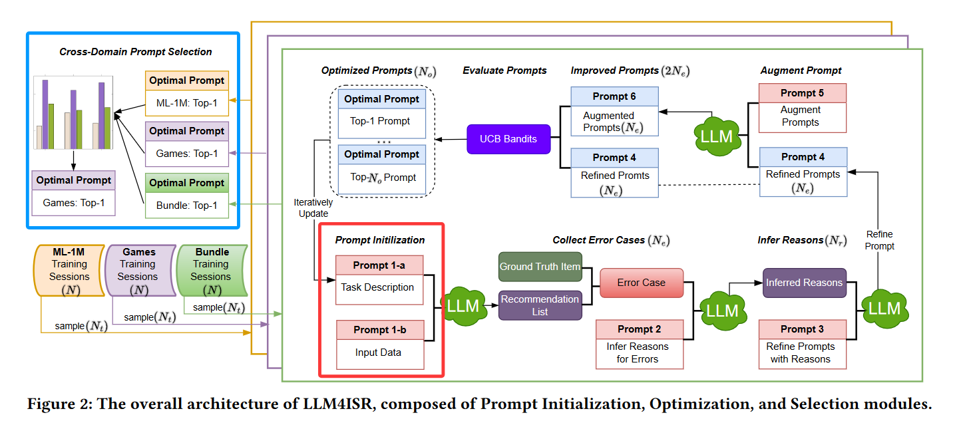
LLM4ISR:通过精细的提示设计和优化机制,有效地解决多重意图识别和推荐透明度不足的问题。
- Prompt Initialization


提示初始化是LLM4ISR的第一个模块,旨在为LLM生成一个初始的任务描述提示,帮助模型理解用户会话中的意图。
通过设计精确的任务描述,模型能够在初步阶段推测出用户的行为模式和意图。
识别会话中的不同项组合
推测每个组合的用户意图
选择最符合用户当前偏好的意图
根据选定的意图重新排序候选项目
通过这种方式,LLM4ISR为后续的推荐过程奠定了基础,使LLM能够理解并推理用户会话中的意图。
- Prompt Optimization
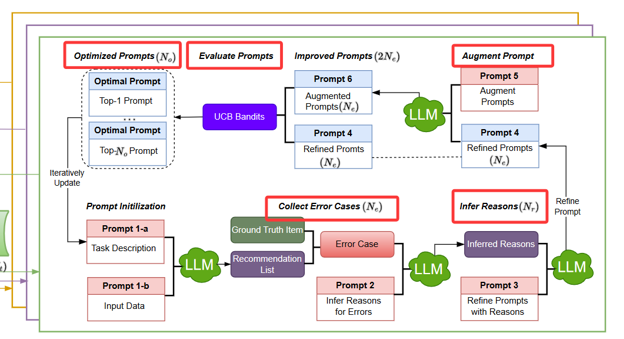
关键步骤包括:错误案例收集、推理错误原因、改进提示、并通过UCB(Upper Confidence Bound)Bandits策略进行性能评估。
具体流程如下:
错误案例收集(Collecting Error Cases)
推理错误原因(Inferring Reasons for Errors)
优化提示(Refining Prompts)
增强提示(Augmenting Prompts)
UCB Bandits策略
提示优化模块通过不断地收集错误案例、分析错误原因、优化和增强提示,以及利用UCB Bandits策略进行性能评估,最终实现了对LLM提示的不断改进和优化。

- Prompt Selection
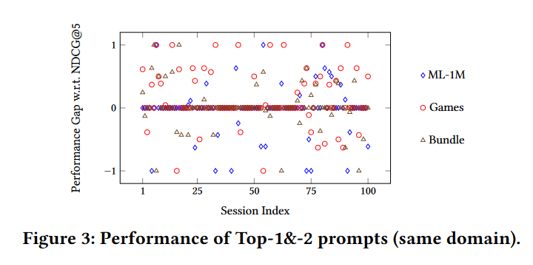
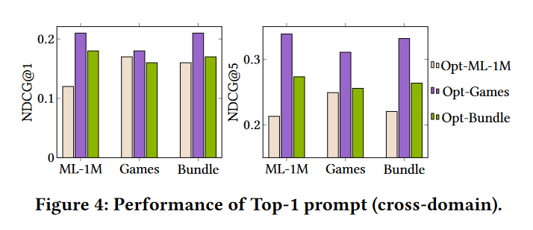
提示选择是LLM4ISR的第三个模块,它通过评估和选择最优的提示来进一步提升推荐效果。
其主要目的是从多个优化后的提示中选择最优的提示,以确保推荐系统在不同数据集上的表现达到最佳。
最优提示选择:Games数据集的Top-1提示在所有数据集上的表现最优。因此,Games数据集的Top-1提示被选为最终的最优提示,用于跨领域推荐任务。
实验

基线方法 (Baselines)—11种基线方法:
传统方法 (Conventional Methods):
MostPop:推荐最受欢迎的商品。
SKNN:基于会话级别的物品相似度进行推荐。
FPMC:使用基于马尔可夫链的矩阵分解方法。
深度学习方法 (Deep Learning Methods):
包括基于单一意图和多意图的推荐方法,如NARM(基于RNN的模型)、STAMP(通过注意力机制学习用户的主要意图)、MCPRN(多通道目的路由网络)、HIDE(通过分割嵌入表示多个意图)等。
跨领域方法 (Cross-domain Methods):
UniSRec:跨域学习模型,使用项描述来学习可转移的表示。
基于LLM的方法 (LLM-based Methods):
NIR:通过零-shot提示进行推荐。
- 整体对比
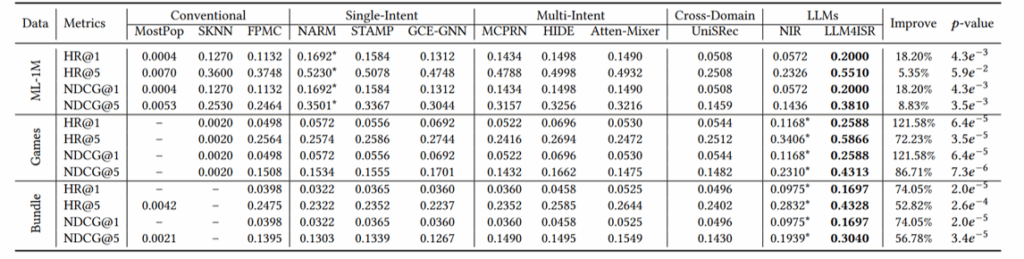
结论:
论文首先对LLM4ISR与各基线方法在三个数据集上的表现进行了对比。结果表明,LLM4ISR在所有三个数据集上都优于其他基线方法,尤其是在稀疏数据和短会话的场景中表现出色。
- 消融实验

Initial:仅使用初始提示。
Top-1:仅使用Top-1提示。
EnSame:将Top-1和Top-2提示的结果进行集成。
EnCross:将来自所有数据集的Top-1提示结果进行集成。
使用Top-1提示显著优于Initial(即没有优化的提示),证明提示优化过程对于提高推荐效果至关重要。
Ensemble方法(EnSame和EnCross)未能显著提升性能,反而稍微降低了效果,表明简单的提示集成可能并不能有效改善结果,且可能会引入噪声。
总结与综合对其思考
(一)论文核心内容
多重意图建模:提出了利用LLM处理用户在同一会话中的多个意图,打破了传统会话推荐系统仅处理单一意图的限制。
精细设计提示机制:通过提示初始化、优化和选择,设计了一种动态调整提示的方式,帮助LLM更好地理解和推理用户的多重意图。采用了UCB Bandits算法来高效优化和评估提示,使得系统能够平衡“探索”和“利用”,不断选择最优的提示。
(二)综合对其思考
动态多意图建模:LLM4ISR 通过LLM在语义层面动态识别用户意图,无需预设固定意图数量。同理,可以替换原有的图谱推理思路,将框架中的“类别图谱辅助推理”转换为 LLM语义意图解析器,比如直接给定用户历史行为序列推测出潜在的新意图。
自动化对比对筛选:LLM4ISR的迭代式Prompt优化通过自我反思(Self-Reflection)自动修正错误。同理,当推荐失败时(如目标商品未进Top-K),触发LLM分析原因,使用错误案例反馈循环。