作者:Meserret Karaca, Michelle M. Alvarado, Mostafa Reisi Gahrooei, Azra Bihorac, Panos M. Pardalos
单位:美国佛罗里达大学工业与系统工程系,佛罗里达大学肾脏学、高血压和肾移植科
来源:Expert Systems With Applications 194 (2022) 116435
发表时间:2022年
一、背景
多变量时序数据挑战
数据结构复杂:多维性、时序性、不规律采样、大规模
时间关系复杂:存在同步/异步测量、共现关系、先后关系等多种时间依赖
维度灾难:传统方法难以处理多变量间的复杂时空关系
现有算法技术局限
基于Apriori的频繁模式挖掘算法存在严重内存消耗问题
需要多次数据库扫描和大量候选模式生成,计算效率低下
无法处理大规模多变量时间序列数据,特别是当最小支持度较低时算法失效
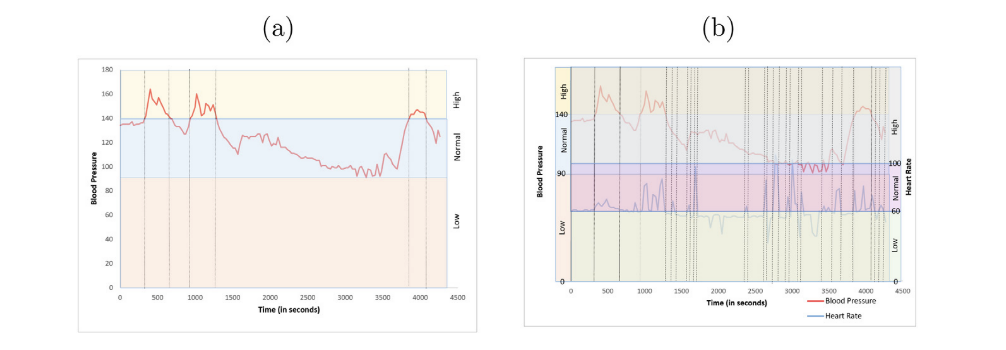
二、创新点
1、理论贡献
算法创新:证明了多变量时间序列可以转换为序列数据集,从而应用序列频繁模式挖掘技术
计算效率:显著降低内存使用量,使大规模数据挖掘成为可能
2、性能优势
内存效率:MTS-FPM的内存使用量比现有方法显著减少,最大减少超过690倍
可扩展性:能够处理包含数百万条记录的大型数据集
适用性广泛:在31个UCR时间序列分类数据集上验证了效果
三、MTS-FPM算法
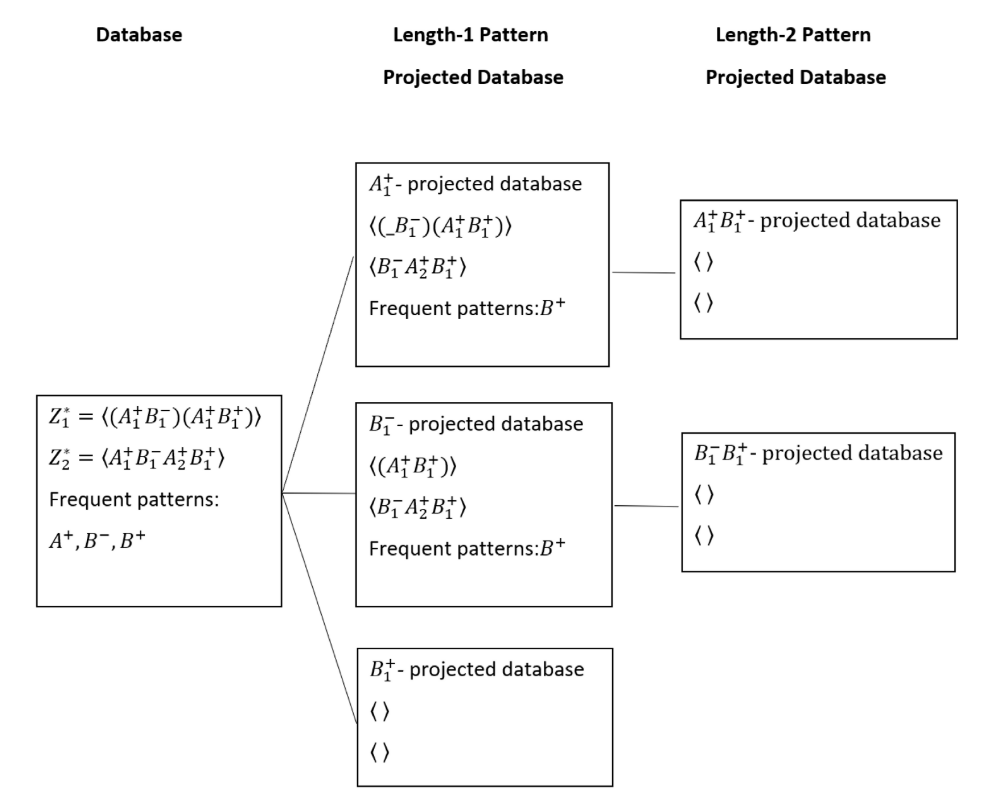
基于PrefixSpan的树形结构算法:
使用模式增长方法而非候选生成-测试方法
递归构建投影数据库
通过后缀树避免冗余的候选模式生成
四个关键剪枝规则:
变量标签规则:如果两个状态间隔属于同一变量,跳过共现计数
重复状态规则:避免重复计数已共现的状态间隔
等价状态规则:避免计数等价的状态间隔关系
历史信息规则:利用之前子树的信息加速计算
四、实验以及实验结果
硬件平台:
服务器:HiperGator 2.0虚拟Linux服务器
内存:70 GB
处理器:20个虚拟核心,2.2 GHz
时间限制:24小时
对比基准:
FTPM:Batal等人(2016)提出的基于Apriori的方法
FTPMwEVL:Kocheturov等人(2019)提出的扩展垂直列表方法
评估维度:
内存使用量:算法运行所需的最大内存
计算时间:完成频繁模式挖掘所需的时间
模式质量:发现的频繁模式的长度和数量
可处理数据规模:算法能够处理的最大数据集大小
UCR标准数据集验证
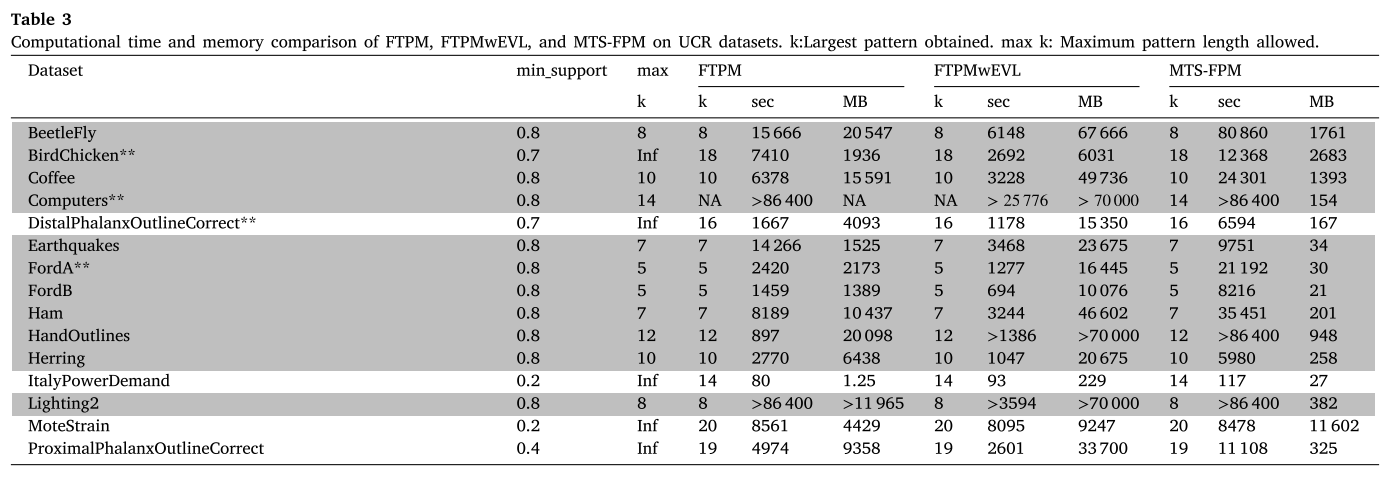
MTS-FPM在内存使用上具有压倒性优势——最大内存使用量不超过11GB,而其他方法经常因内存限制(>70GB)而无法完成任务,特别是在长序列数据集(如Computers、Earthquakes)上。
MTS-FPM的内存效率比FTPMwEVL高出数百倍,虽然计算时间相对较长,但这种时间-内存的权衡使得大规模数据处理成为可能。
AKI医疗数据应用
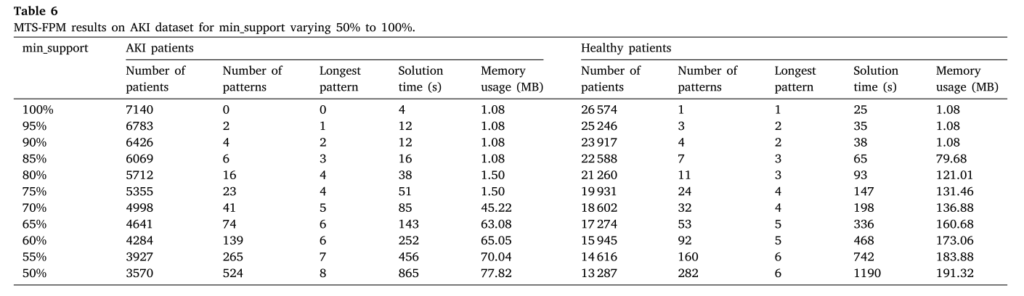
随着最小支持度从100%降低到50%,算法能够发现更多、更长的频繁模式(从0个模式增长到524个模式,最长模式从0增长到8),同时内存使用量保持在合理范围内(最大77.82MB),计算时间呈可接受的增长趋势(最长865秒),证明了算法在真实大规模医疗数据上的实用性和可扩展性。
内存使用量对比
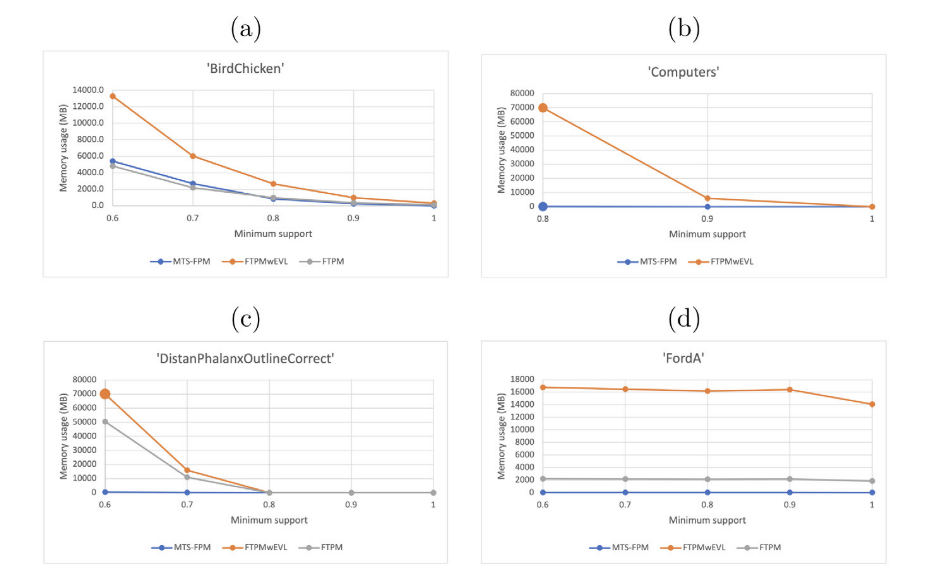
在四个不同特征的数据集上,随着最小支持度的降低,MTS-FPM始终保持线性增长的内存使用模式,而FTPM和FTPMwEVL呈现指数级增长,经常因内存限制而无法完成任务。
计算时间对比
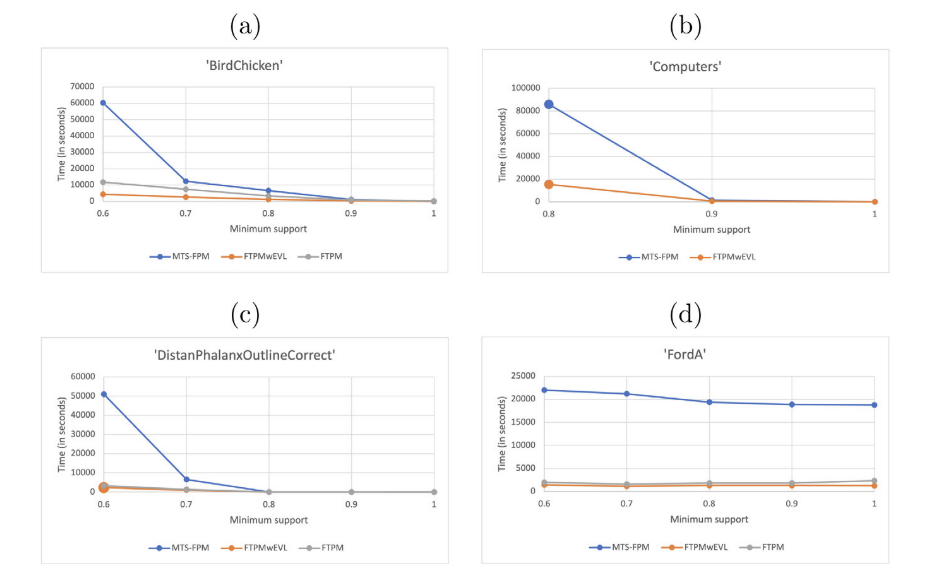
在所有数据集上,MTS-FPM的计算时间都明显长于FTPM和FTPMwEVL,特别是在低支持度情况下差距更加明显。MTS-FPM比其他方法慢8.5-22.3倍,虽然时间较长,但仍在实际应用的可接受范围内。
五、总结
论文提出了MTS-FPM(Multivariate Time Series Frequent Pattern Miner)算法,核心创新包括三个方面:
首先,设计了多变量状态序列(MSS)到序列数据的转换方法,将复杂的多变量时间序列转换为可用于序列模式挖掘的数据结构;
其次,基于PrefixSpan算法构建树形结构,采用模式增长方法替代候选生成-测试策略,通过递归投影数据库实现高效挖掘;
最后,设计了四个针对多变量时序数据的剪枝规则,包括变量标签剪枝、重复状态剪枝、等价关系剪枝和历史信息剪枝,显著提高了算法效率。