来源:CVPR
时间:2023
单位:University of California, Berkeley
作者:Tim Brooks* Aleksander Holynski* Alexei A. Efros
一、研究背景以及意义
GPT捕获关于语言的知识,Stable Diffusion捕获关于图像的知识,两者结合用于生成跨越两模态的成对训练集。InstructPix2Pix在前向过程直接进行图像编辑,无需额外样例图、对输入/输出图的描述或逐样本finetune。尽管InstructPix2Pix利用生成数据进行训练,但可零样本泛化到真实图片中。可进行各种编辑任务:替换目标、改变图片风格、改变背景、艺术风格等等。
二、研究思路及方法
本文提出一种根据人类引导编辑图像的方法InstructPix2Pix:输入一张图片及告诉模型做什么的引导语,本文的模型将会跟随引导语编辑图像。为获得解决该问题的训练集,作者结合两个大预训练模型的知识:GPT-3、Stable Diffusion,用于生成图像编辑数据集。InstructPix2Pix在生成数据集上训练,但是可泛化到真实数据并且实现用户引导。因为该方案在前向过程进行编辑,无需finetune或转换,可在秒级完成图像编辑。作者展示了令人信服的编辑结果。
本文将基于引导的图像编辑任务看作有监督学习问题
①生成成对训练集,包括图像编辑指令及编辑前后的图像

②在生成数据集训练图像编辑扩散模型

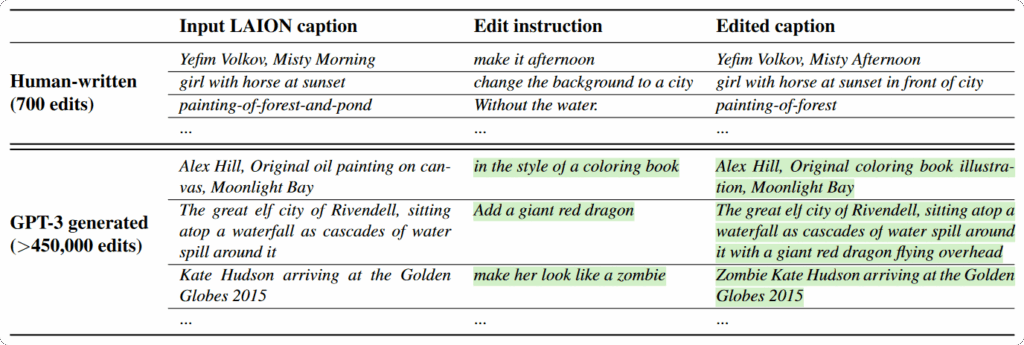
生成指令及成对caption
使用LLM利用输入图和caption生成编辑指令及编辑后图片caption,上述过程用到的语言模型通过在小批量人工编写的数据集上finetune GPT-3获得的。
依据成对的caption生成成对的图像
将一对caption转换为对应图像的挑战在于当prompt发生变化时,不能保证图像一致性。比如:“a picture ofa cat”及“a picture ofa black cat”可能会生成非常不同的猫,不利于训练模型进行图像编辑。因此作者使用Prompt-to-Prompt,使得生成图像尽量相似,如图3展示使用Prompt-to-Prompt前后结果。Prompt-to-Prompt中参数p可控制两张图相似性,作者对每个caption对生成100个样本对,并通过CLIP进行过滤样本。

三、结果
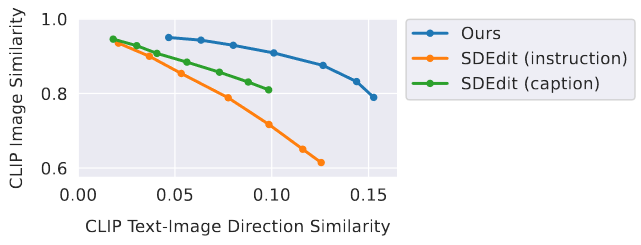
作者与Text2Live、SDEdit进行定性比较。尽管SDEdit能够保证内容一致,同时风格变化,但是它需要目标图的description而不是instruction。

与SDEdit定量比较,纵轴表示CLIP图像相似性,通过计算CLIP image embedding余弦相似性实现,用于表示编辑后的图像与编辑前图像一致性;横轴表示CLIP图文相似性,用于表示编辑后图像与caption一致性。与SDEdit相比,作者所提方法在相同图文一致性时,具有更高的图像一致性。
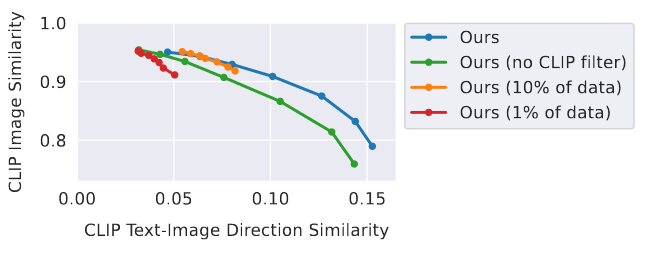
消融实验
消融实验量化结果,降低数据集大小将导致降低更大图像编辑能力,仅保证图像一致性,但无法保证图文一致性;移除数据集CLIP过滤,导致与输入图的一致性降低。
四、总结
作者证明大语言模型与文生图模型结合生成数据集,用于根据instruction训练扩撒模型。虽然能够进行令人信服的图像编辑,但是仍存在一些限制。
①受限于生成数据集图像质量
②受限于模型泛化到新编辑instruction的能力
③视觉变化与instruction做出正确关联度受限于finetune GPT-3人工编写的instruction、GPT-3的能力、Prompt-to-Prompt能力
④在目标数量计数及空间推理方面存在问题。
五、思考
本文结合了两个大型预训练模型,一个大型语言模型和一个文本到图像模型,生成了根据人类指令进行图像编辑的数据集,并在此基础上训练了扩散模型InstructPix2Pix,能够遵循人类指令进行编辑,取得了很不错的效率。根据人类反馈来改进模型,应用强化学习策略来改善模型与人类意图之间的一致性,能否像LLM中的InstructGPT一样成为AIGC以文生图的方向,值得期待!
鉴于InstructPix2Pix在指令编辑图像上的优秀表现,因此此模型可以作为多视角一致性编辑模型的基础生成模型来使用。