作者:王光宇团队,宋纯理,杨简.
单位:北京邮电大学,北京大学第三医院,宜昌市中心人民医院/三峡大学第一临床医学院.
来源:nature medicine
时间:2025.1
一、论文介绍
该文提出了MedFound,一款拥有 1760 亿参数的通用医学语言模型,其在来自不同医学文本和真实世界临床记录的大规模语料库上进行了预训练。研究团队进一步对 MedFound 进行了微调,采用基于自引导策略的链式思维方法来学习医生的推理诊断,并引入了一个统一的偏好对齐框架,使其与标准临床实践保持一致。
此外,该文提出了一种两阶段的方法,将 MedFound 调整为诊断通才,从而产生一个改进的版本,称为 MedFound-DX-PA。首先引入了一种基于自我引导策略的思维链微调,使 LLM 能够像医生专家一样自动生成诊断理由和推理。随后,为了使 LLM 的输出与临床要求保持一致,该文提出了一个统一的偏好对齐框架。该框架包括由国际疾病分类(ICD)-10树的分层诊断结构指导的诊断层次结构偏好,以及(2)由专家注释指导的有用性偏好。
二、主要内容
在第一阶段,作者对LLM BLOOM-176B 进行预训练,从而训练出MedFound。为了开发 MedFound,该文构建了一个大规模医学语料库数据集 MedCorpus,其中包含来自四个数据集的总共 63 亿个文本标记:MedText、PubMed Central Case Report (PMC-CR)、MIMIC-III-Note 和 MedDX-Note。这些数据集来自医学教科书和临床指南、文献中的患者病例报告、开放访问的临床记录以及来自医院系统的电子健康记录。MedCorpus 的预训练使 MedFound 能够编码广泛的医学知识和实践经验,使其成为医疗领域广泛应用的基础工具。
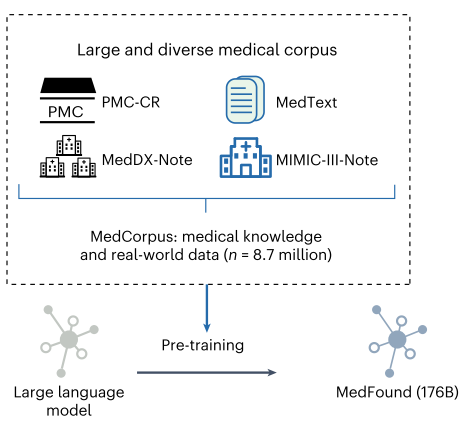
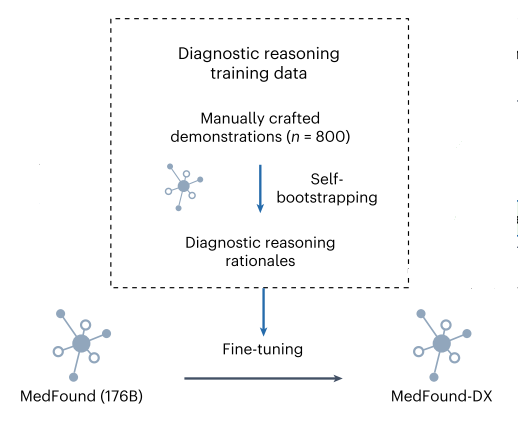
在第二阶段,作者对MedFound进行了微调,模仿医生的诊断推理过程,微调出MedFound-DX。为了微调MedFound-DX,该文整理了一个名为MedDX-FT的数据集,其中包含医疗记录和相关的诊断原理演示,以进行微调。医生被要求根据实际的医疗记录诊断给定的患者病例手工制作临床推理过程的演示。基于人工演示的种子集和109,364个电子健康记录,采用自引导策略来增强LLM的能力,以便在不需要大量专家劳动的情况下为每个电子健康记录自动生成高质量的诊断原理(中间推理步骤)。
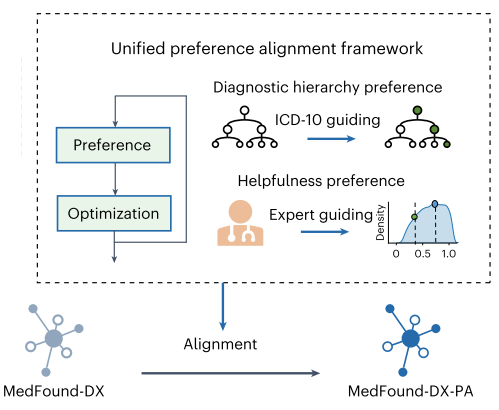
在第三阶段,坐着通过采用统一的偏好对齐框架框架进一步优化了模型的实际临床效用,该框架集成了“诊断层次结构偏好”和“有用性偏好”。诊断层次结构偏好以 ICD 代码定义的疾病分类的层次结构为指导,旨在使模型的生成与疾病分类标准保持一致。通过对专家注释进行训练的有用性评分模型来完善有用性偏好,旨在使模型的生成在诊断目的上更具信息性、有用性和可信度,同时最大限度地降低伤害或误导性信息的风险。
三、实验评估
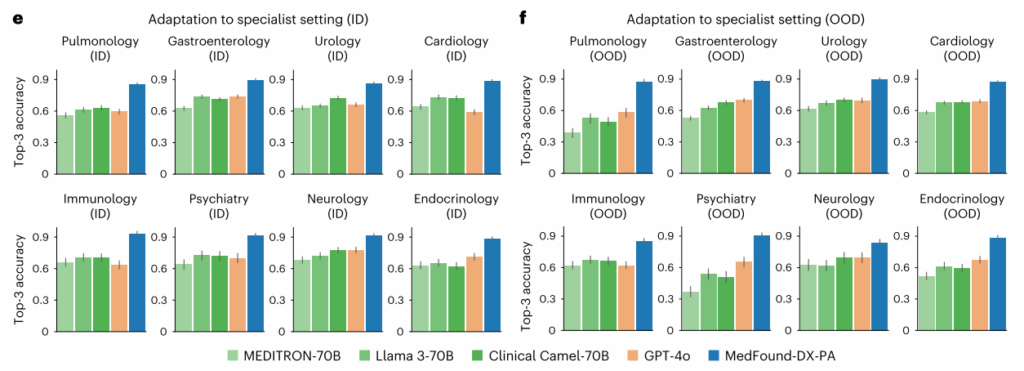
四、论文总结
- 提出MedFound模型:
1760亿参数医疗大语言模型(LLM),基于BLOOM-176B继续预训练。
预训练数据:融合医学教材(MedText)、病例报告(PMC-CR)、公开临床记录(MIMIC-III)及870万真实电子病历(EHR)。
微调与对齐:
采用自举链式思维(Self-Bootstrapping CoT),仅需800条人工标注即可生成10万+诊断推理链。
统一偏好对齐框架(PA):结合ICD-10疾病层级偏好与医生标注的”有用性”偏好,确保诊断符合临床标准。 - 临床验证:
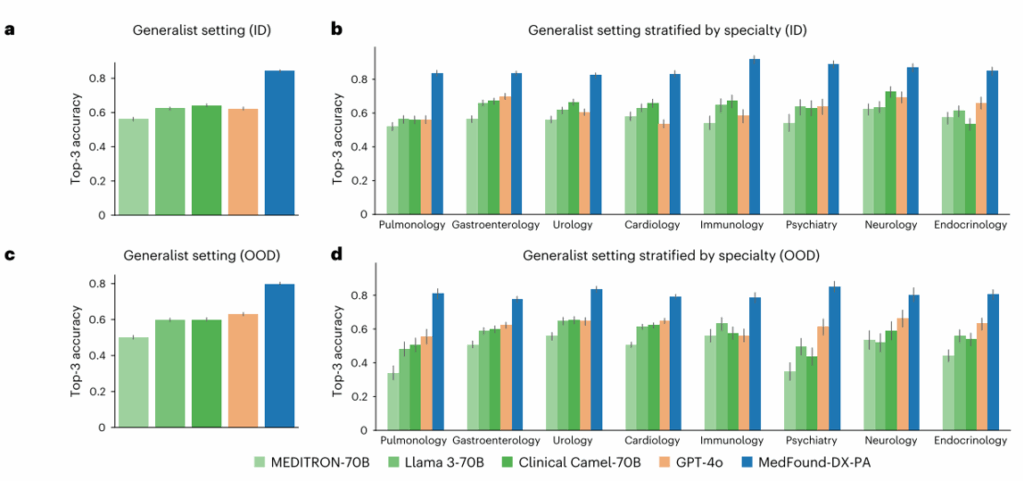
AI vs 医生:在呼吸科/内分泌科诊断中,模型优于初级和中级医生,接近高级医生水平(如内分泌科:AI 74.7% vs 高级医生75.2%)。
AI辅助效果:初级医生诊断准确率提升11.9%,中级医生提升6.3%,部分案例中辅助后诊断超过高级医生。
评估框架CLEVER:提出8项临床指标(如病例理解、鉴别诊断相关性、偏见控制),模型在所有维度显著优于未对齐版本。