作者:Xintong Li, Jinya Jiang, Ria Dharmani, Jayanth Srinivasa, Gaowen Liu, Jingbo Shang
来源:arXiv
单位:UC San Diego, Cisco
发表日期:2024.7
一、研究背景
研究背景:
现实挑战:多标签文本分类中,通常缺乏完整的标签空间,实际应用中难以提前定义所有类目。
弱监督设定:仅提供简要分类描述,缺少人工标签和真实标签空间的监督极为有限。
任务需求:如商品自动分类等实际场景中,要求高效发现潜在标签并实现分类。
研究目标:
旨在探索“开放世界”下的多标签文本分类问题,提出一个新的框架——X-MLClass,在没有标签和标签空间的前提下,通过LLM引导标签空间构建与分类器训练,尤其着力于识别“长尾标签”,解决现有方法无法适应多标签弱监督问题的挑战
二、核心内容

标签空间构建
关键短语提取:将文档分块,用LLM生成每块的核心短语。
短语聚类:利用语义嵌入与聚类模型(如GMM)构建初始标签空间。
冗余剔除:结合句向量与GPT辅助判断,清洗相似标签。
基于文本蕴含的分类器

使用零样本文本蕴含模型,对每个文档块与标签进行匹配。
高分块被认为属于主标签,低分块则提示可能缺失标签。
将块结果与文档级预测结合,提高标签覆盖和精度。
长尾标签发现机制
🔍 识别潜在遗漏区域:
首先定位文本块中置信度较低的部分,初步判断当前标签空间中可能缺失标签。
🔁 回溯关键短语生成源:
提取这些低置信块中LLM生成的关键短语,挖掘潜在长尾标签候选。
➕ 丰富标签空间:
将出现频率达到阈值、但尚未被收录的关键短语纳入当前标签空间。
🔄 迭代优化标签集合:
通过多轮迭代,逐步增强标签空间的覆盖广度,尤其提升对长尾标签的识别能力。
三、实验评估
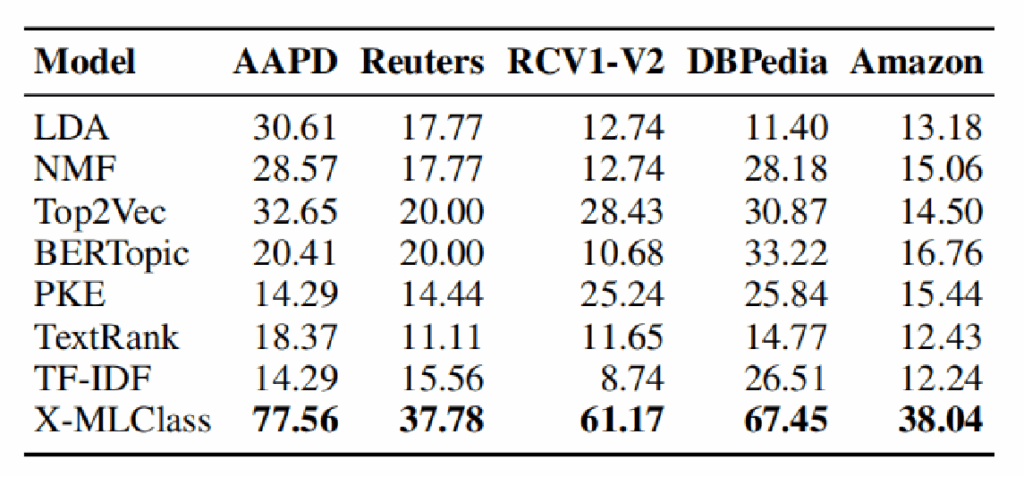
X-MLClass在五个数据集上的标签空间覆盖率显著优于所有对比方法,展示了其在发现真实标签方面的强大能力
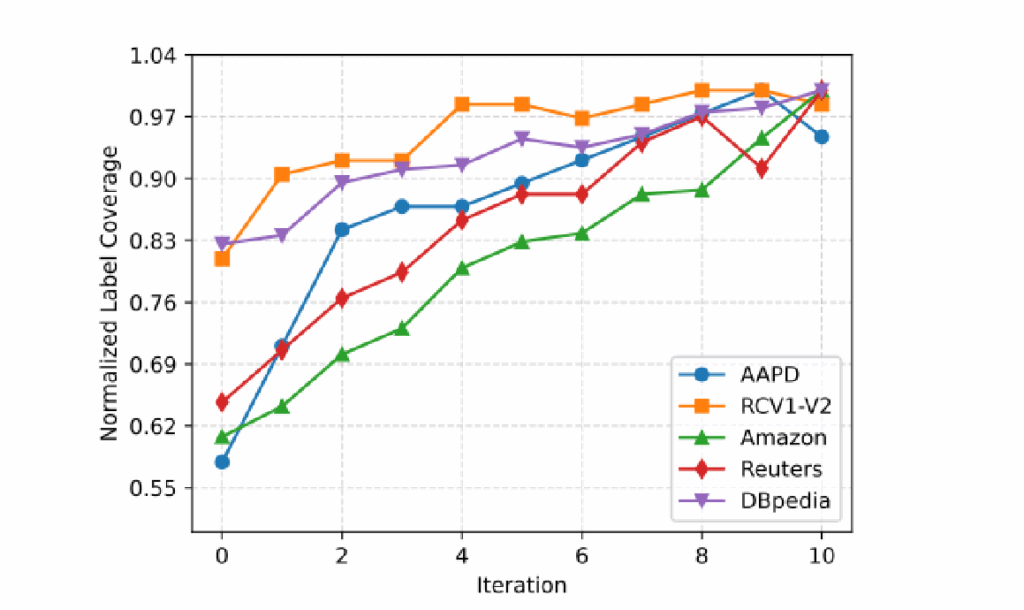
随着迭代次数增加,X-MLClass在不同数据集上的标签空间覆盖率持续提升,验证了迭代机制在发现长尾标签方面的有效性。
四、总结思考
论文总结
核心方法:本文提出X-MLClass框架,在极弱监督(XWS)和开放世界(Open-world)设定下,通过大语言模型引导生成标签空间,结合零样本文本蕴含方法进行多标签分类,并引入迭代机制补全长尾标签,在无标签输入条件下实现高效分类。
实验结果:在五个公开数据集上,X-MLClass在标签空间覆盖率与多标签分类准确率两方面均显著优于7个现有主流方法。
优势总结:
1.无需人工标签,仅基于任务描述即可运行;
2.能有效发现并利用“长尾标签”,提升真实标签覆盖度;
3.框架结构通用,适配多种零样本分类器,具备较强扩展性;
4.支持人类参与精细化调整,兼顾自动化与可控性。
启发思考
1.软标签生成中的“标签空间构建”问题:可以借助LLM先自动构建“候选标签空间”,再通过目标约束(如领域描述、历史知识)加以筛选,提升软标签的可控性与覆盖率。
2.从“主导短语识别”联想到软标签的权重分配机制:标签可以参考该机制——基于LLM生成短语与候选标签之间的蕴含置信度,构建带权重的标签分布,实现更贴近语义强度的软标注。
3.“长尾标签”挖掘策略对难识别类别建模具有借鉴意义:可以引入类似的增量式标签精化策略,针对软标签中置信度低、分布扁平的情况,重点补充潜在标签,从而提高尾部标签质量。