作者与单位:Eshaan Agarwal, Joykirat Singh, Vivek Dani;Microsoft
来源:arxiv
发表时间:2024
背景
过去的自动提示工程方法主要集中在枚举不同的提示或改进现有的提示来优化黑盒LLM的指令。这些策略可以大致分为两种类型:连续和离散即时优化。

PromptWizard
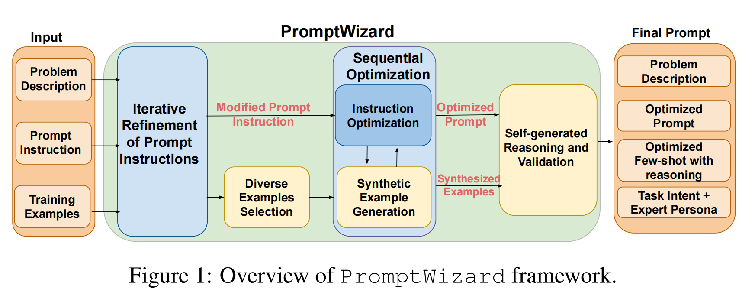
从问题描述和初始提示指令开始,PW通过提示LLM对其进行变异来生成指令的变体,然后基于性能,选择最佳。
与现有方法中的不受控制的演变不同,PW结合了一个提供反馈的评价组件,从而在多次迭代中指导和改进提示。
优化上下文中的示例。PW从训练数据中选择了一组不同的示例,根据它们在修改后的提示中的表现来识别正面和负面示例。
PW将依次优化示例和指令。
使用评价来生成针对当前提示的弱点的合成示例。这些示例被集成以进一步细化提示。
PW通过思想链(CoT)生成详细的推理链,丰富提示的解决问题的能力。通过整合任务意图和专家角色,使提示与人类推理保持一致,从而增强模型性能和可解释性。
迭代细化提示指令
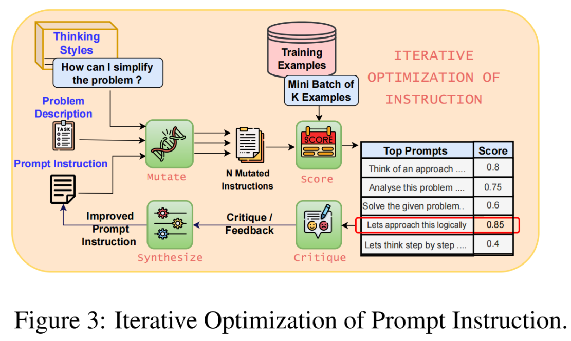
变异组件:从初始问题描述开始,使用预定义的认知启发式或思考风格生成提示变体。
从不同角度创建问题,确保提示指令的多样性和丰富性。
例如,思考风格可能鼓励提出问题,如“我如何简化这个问题?”或“还存在哪些替代视角?”。
评分组件:使用评分机制来评估生成的变异提示的性能。
评分基于每个提示在一个小批量的5个训练示例上的表现,这些示例具有真实答案。
这有助于系统地识别最有效的提示,同时过滤掉表现不佳的提示。
使用多个小批量确保评估的稳健性。
批判组件:一旦选择了表现最好的变异提示,PW通过其批评组件引入独特的反馈机制。
批评通过分析LLM在哪些情况下遇到困难(例如,在解释关系或时间转换时)来回顾提示的成功和失败。
这种有针对性的反馈对于细化提示至关重要,因为它提供了特定弱点的见解,允许进行有针对性的改进,而不是进行一般性的更改
合成组件:最后,合成组件使用批评的反馈来细化最佳提示。
它根据批评重新措辞和增强指令,产生更具体于任务的优化提示。
例如,反馈指出在解释特定关系时存在问题,合成的提示将直接解决这一点,导致更清晰、更有效的指令。
通过结合——变异、评分、批评和合成——这些步骤PW确保提示不仅多样化和创造性,而且高度针对特定任务,超越了缺乏这种指导性细化过程的先前方法。
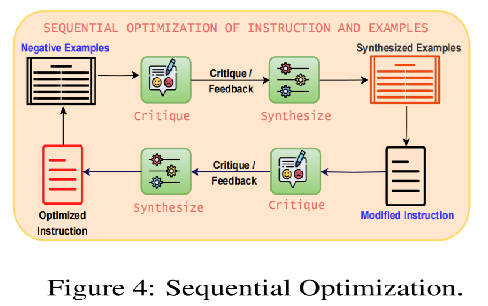
示例优化遵循批评和合成过程:
(i)批判组件:PW分析以前选择的例子,利用批评提供详细的反馈。这种反馈是基于错误驱动的自我反思,决定了例子应该如何发展,以更加多样化和任务相关。
(ii)合成组件:结合了来自批判性的反馈,以生成更多样化、更强大、更有活力的新的合成示例,
提示优化遵循批判与合成过程:
(i)批判组件:新生成的合成示例与当前提示一起进行评估。批判组件识别需要解决的弱点和差距,以进一步完善提示指令。
(ii)合成组件:利用了来自批判评论的反馈来合成和完善提示指令。提示和合成的示例,确保它们与特定任务的细微差别保持一致。
实验结果
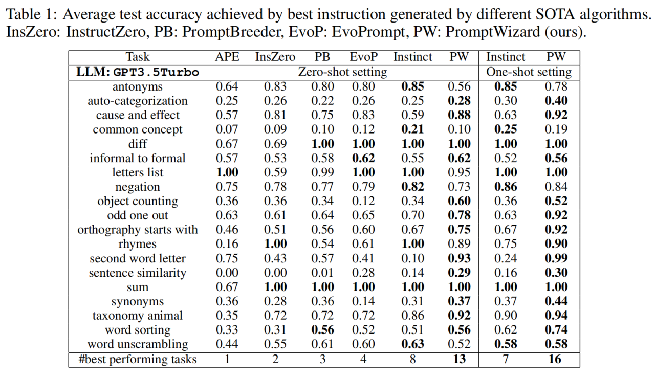
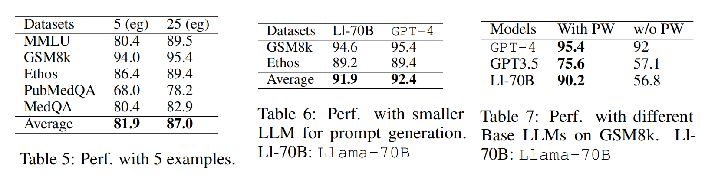
核心内容总结
- 提出一个离散提示优化框架,利用自进化机制,LLM生成、批判和改进自己的提示和示例,通过迭代反馈不断改进提示。
- 不是单一优化提示或生成示例,而是二者结合并动态地、迭代地按顺序优化提示指令和上下文示例,对于复杂任务,这种提示与少量示例结合非常有效。