- 时间:2024
- 发表单位:中国科学院软件研究所、中国科学院大学、阿里巴巴集团
- 发表在:aXiv
核心内容
- 目前来说,RAG 是大模型应对知识型任务的首选方案。但是对于知识密集型推理任务来说,解决问题的有效信息往往非常分散,RAG 往往不能有效识别并且检索这些信息;
- 本文提出了 StructRAG,其通过动态选择知识结构类型并且构建相应的结构化数据来克服传统 RAG 的缺陷;大模型可以在构建出来的结构化数据上面进行推理以更好地得出答案;为了实现动态选择知识结构,作者用强化学习训练了一个分类器。实验证明这样做是有必要的;
- 本文进行了大量实验来验证 StructRAG 的表现以及探索各个组件的作用。实验表明 StructRAG 在很多问答任务上达到了 SOTA 水平。
背景
- 大语言模型因为其出色的自然语言能力被广泛应用于各种复杂场景之中,但是大语言模型的知识很难实时更新,而且也对单独领域缺乏深度了解;在这种背景下,我们用 RAG 来克服这些缺陷,使得大模型可以生成可靠的回答;
- 然而 RAG 在面对知识密集且推理要求高的任务也无能为力。作者认为,这类完成这类任务所需要的信息往往非常分散,这导致 RAG 面对这类任务的时候总是遇见这样的情况:
- 检索不完全,缺失了推理所必需的信息;
- 检索完全,但是无关内容太多,噪声大。
- 缺失了必要的信息无疑会影响表现,然而相当多的研究表明,噪声对 LLMs 的影响也是非常巨大的。两难之下,一个思想就诞生了,将检索数据结构化。
- 本文提出了 StructRAG,其核心思想在于模拟人类将阅读的信息整理为结构化信息进而减小认知负荷(cognitive load)。其通过一个分类器,识别出问题所最适合的数据结构,再将检索的文档结构化,最终在分步推理过程中逐步从结构化的文档中抽取出最有用的信息。
- 为了得到这个分类器,作者构建了一个人造数据集,并且用强化学习手段训练了一个 LLM 来充当分类器。
- 实验表明,StructRAG 达到了 SOTA 水平,并且比 GraphRAG 要快。
方法论
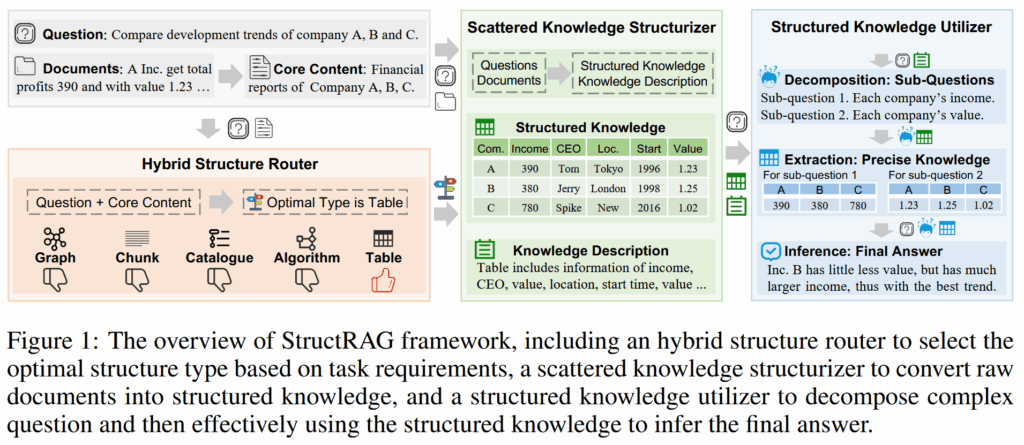
问题定义
一个经典的 RAG 问答流程可以看作如下过程:
$$
a=F(q,D)
$$
其中,$q,a$ 分别是问题和答案,而 $D={ d^{(i)} }$ 是文档集合,其中 $|D|=m$;我们的任务就是构建一个模型 $F$,实现基于文档的问答。
Hybrid Structure Router
由于 $D$ 中的文档往往包含许多无关内容,所以需要将其转换为噪声小的结构化数据。在这种思路下,选择一个合适的结构就很重要了。Hybrid Structure Router ($R$) 就是实现这一目的的分类器。在作者的设计中, $R$ 只依据问题 $q$ 和所有文档的标题以及前几个句子($C={ c^{(i)} }={ \text{Title-First-Sentences}(d^{(i)}) }$)来做判断。
$$
t=R(q,C)
$$
作者在本文中使用的结构类型包括:
- 表格(markdown 表格)
- 图(三元组)
- 文本段(字符串)
- 算法(伪代码)
- 目录(分层次的有序列表)
这样的分类模型不是凭空就有的,需要专门去训练一个。首先作者构造了一个人造训练数据集。
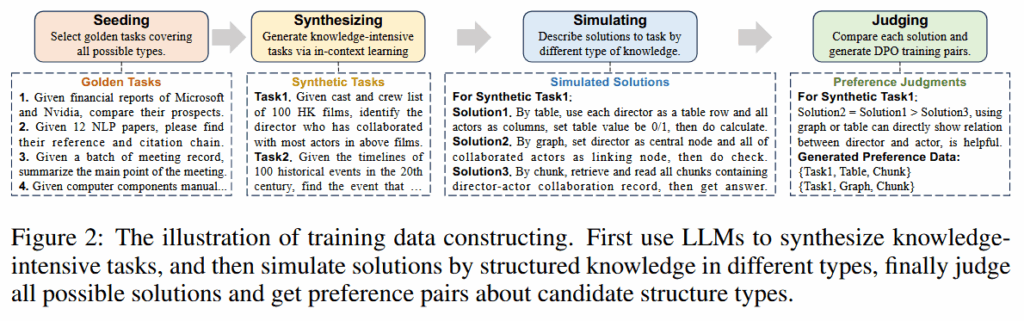
具体来说,就是挑选一些任务样本作为种子,然后要求 LLM 根据文档模仿这些种子构造新的任务;对于每个任务,作者都要求大模型分别给出 5 种结构的方案,最后让大模型评估给出的方案哪种最好,并进行排序。就这样,作者构造了这样一个数据集:
$$
D_{\text{synthetic}}={ q^{(k)},C^{(k)},t_{w}^{(k)},t_{l}^{(k)} }
$$
其中 $t_{w}$ 代表偏好的类型;$t_{l}$ 代表拒绝的类型。这都是最后一部大模型评估出来的。
使用 DPO 微调现有的 LLM。损失函数如下:
$$
L_{DPO}(\pi_{\theta};\pi_{\text{ref}})=-\mathbb E_{(q,C,t_{w},t_{l})\sim D_{\text{synthetic}}}\left[ \log\sigma \beta\left( \log \frac{\pi_{\theta}(t_{w}|q,C)}{\pi_{\text{ref}}(t_{w}|q,C)}-\log \frac{\pi_{\theta}(t_{l}|q,C)}{\pi_{\text{ref}}(t_{l}|q,C)} \right) \right]
$$
从这里可以发现,最小化这个损失函数会导致 $\pi_{\theta}$ 倾向于增大输出 $t_{w}$ 的概率,并且减小 $t_{l}$ 的概率。这是符合 DPO 精神的。
Scattered Knowledge Structurizer
得知了针对此问题最合适的知识结构类型之后,就需要将所有的文档都逐个转换为这样的结构化数据。
$$
k_{t}^{(i)},b_{t}^{(i)}=S(q,t,d^{(i)})
$$
其中,$k_{t}^{(i)}$ 是第 i 个文档 $d^{(i)}$ 转换为结构类型 t 的结果;而 $b_{t}^{(i)}$ 是一小段描述,用于后面做一些判断。转换后的数据和描述合起来成为两个集合 $K_{t},B_{t}$。
Structured Knowledge Utilizer
有了结构化数据之后,就可以进行推理解答问题了。考虑到多步推理问题处理起来十分麻烦,所以作者用大模型将其切分为多个子问题(参考子问题分割)分开处理。具体来说,这一部分有三个模型:
- $U_{\text{decompose}}(q,B_{t})$:根据前文生成的结构化数据的描述,将原问题拆分为一组子问题 $\hat{Q}={ \hat{q}^{(j)} }, |\hat{Q}|=n$
- $U_{\text{extract}}(\hat{q}^{(j)},K_{t})$:从 $K_{t}$ 中抽取出精确的知识,用于回答问题,抽取出的知识记为 $\hat{K}{t}={ \hat{k}{t}^{(i)} }$
- $U_{\text{infer}}(q,\hat{Q},\hat{K}_{t})$:联合所有分解出的子问题以及抽取的知识,推理解出答案 $a$
这三个看似复杂的过程都是直接提示 LLM 生成的。
 实验
实验
构造数据以及推理使用的 LLM:Qwen2-72B-Instruct(vLLM)
实验数据集:Loong,Podcast Transcript
metric:LLM,EM
训练分类器用的 LLM:Qwen2-7B-Instruct
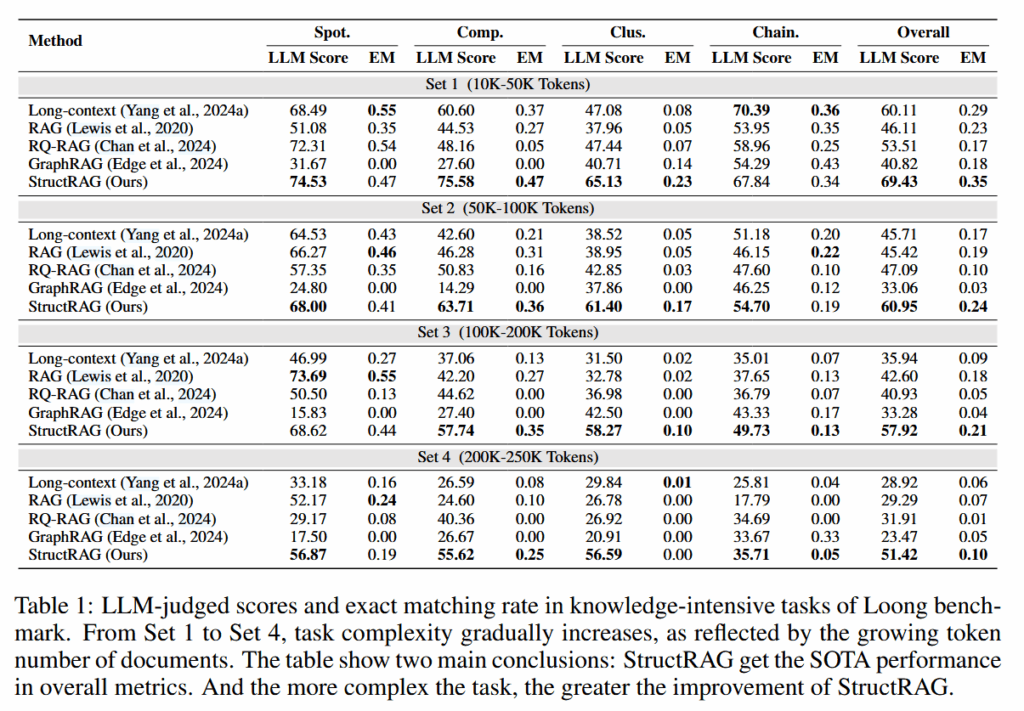
回答质量评估:
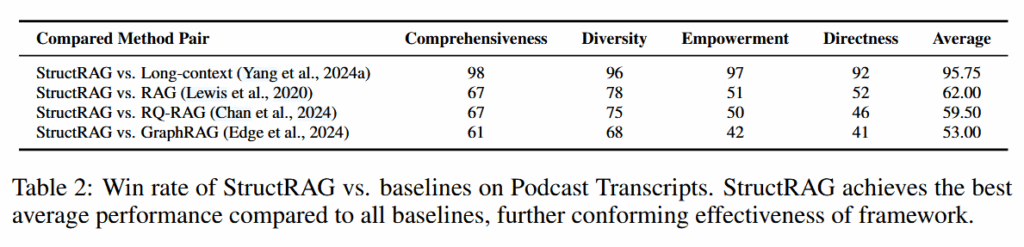
消融实验
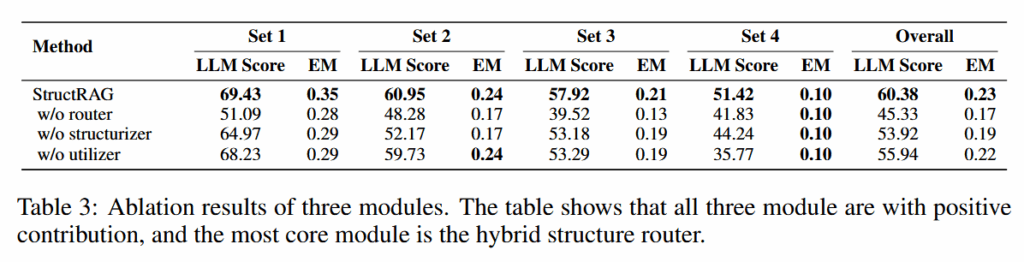
- w/o router:随机挑选一种结构
- w/o structurizer:直接用文本 chunks 代替结构化数据
- w/o utilizer:直接将结构化数据和问题输入给 LM 获取答案
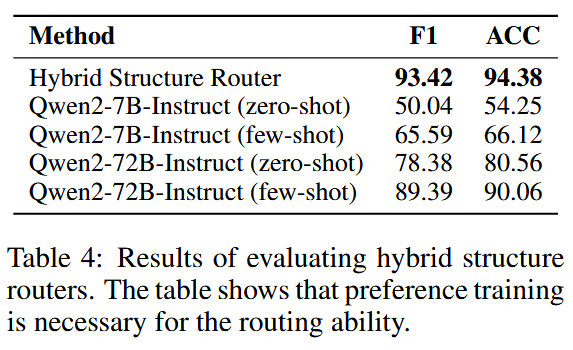
事实证明,强化训练分类器是必要的。直接使用 LLM 无法达到强化分类器的精度:
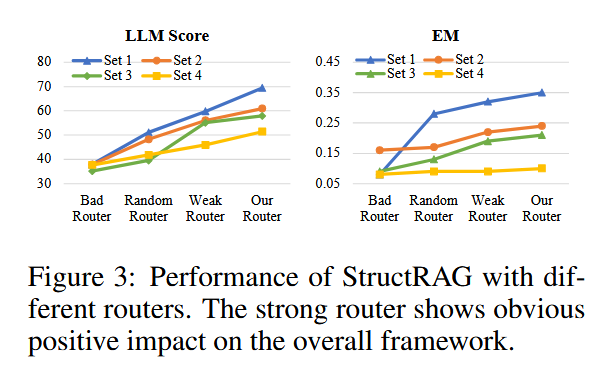
Router 质量的好坏对效果的影响:
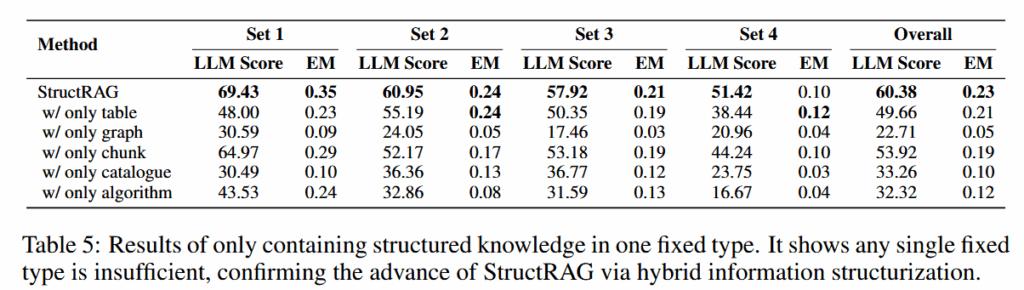
单独一种结构类型也不能达到原本的效果:
结论
- 受到认知科学的启发,作者设计了一个可以根据情况选择最合适结构类型的管线,可以根据问题和文档类型动态选择并且生成结构化数据,最后在结构化数据的基础上提取出解决问题最有用的信息,增强大语言模型的生成能力;
- 为了实现动态选择类型,作者构造了一个数据集并且通过强化学习训练了一个大模型分类器。事实证明这样的分类器效果要好于直接使用大模型;
- 实验表明,StructRAG 表现比较好,而且各个组件都不可或缺。
对齐思考
- 结构化数据能够有效提高大模型生成能力,但是不同的问题需要不同的结构化数据;因此挑选场景是个很重要的问题;
- 在复杂推理问题上,完整、精炼的信息比复杂的推理机制效果更加立竿见影;
- 如果是完成特定的任务而不是通用问答,那么强化学习后的大模型效果会好于直接使用通用模型。