作者单位:国防科技大学,IDEA Research, 牛津大学
来源:arxiv
发表时间:2025
背景
RAG模型:RAG结合了信息检索和文本生成的优势,通过从大规模文档库中检索相关信息来增强生成模型的表现。
检索阶段:现有的RAG方法主要依赖于词级别的匹配,无法保证召回的信息总是与查询相关。在检索推理所需的语句时能力不足
生成阶段:生成器在利用检索到的内容时,缺乏明确的指导,导致生成的答案难以解释和验证。因为在LLM的预训练语料库中很少明确地“指出”和“监督”各种事实之间的关系。即使正确回答,因此,当前的RAG既没有被内在地训练成沿着合理的检索方向进行检索,也没有将检索到的内容有机地归因于答案。
规则引导:作者提出通过引入规则来指导检索和生成过程,以提高模型的性能。该文中选择知识图谱作为规则,用于逻辑推理和关系推导。
RuleRAG框架
两个主要部分——检索器(retriever)和生成器(generator)。
检索器负责从文档库中找到相关的上下文,而生成器则基于这些上下文生成最终的回答。
规则引入:通过在输入侧引入规则,指导检索器召回相关文档,并帮助生成器进行逻辑推理。
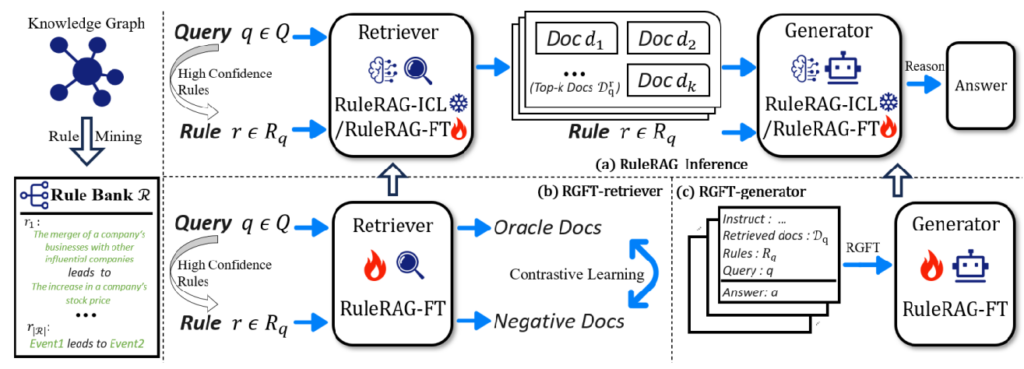
规则库:
使用知识图谱挖掘算法(如AMIE3或TLogic)生成规则库R。
规则的形式化表达:[Entity 1, r1, Entity 2] leads to [Entity 1, r2, Entity 2]。
利用经典的规则挖掘算法AMIE3来处理静态KG,以及TLogic来处理时序KG。
训练策略
RuleRAG-ICL(In-Context Learning):通过上下文学习的方式引入规则,直接指导生成过程。
RuleRAG-FT(Fine-Tuning):通过对比学习更新检索器,并通过设计的规则指导微调(RGFT)更新生成器。
实验设置
数据集
自建数据集:作者构建了五个基于知识图谱的问答基准数据集(RuleQA),以评估RuleRAG的效果。
现有数据集:在四个现有的RAG数据集(ASQA, PopQA, HotpotQA, NQ)上进行了对比实验。
评估指标
Recall@10:衡量检索到的相关文档的比例。
Exact Match (EM):衡量生成的答案是否完全正确。
F1 Score:衡量生成答案与标准答案之间的重叠度。

实验结果
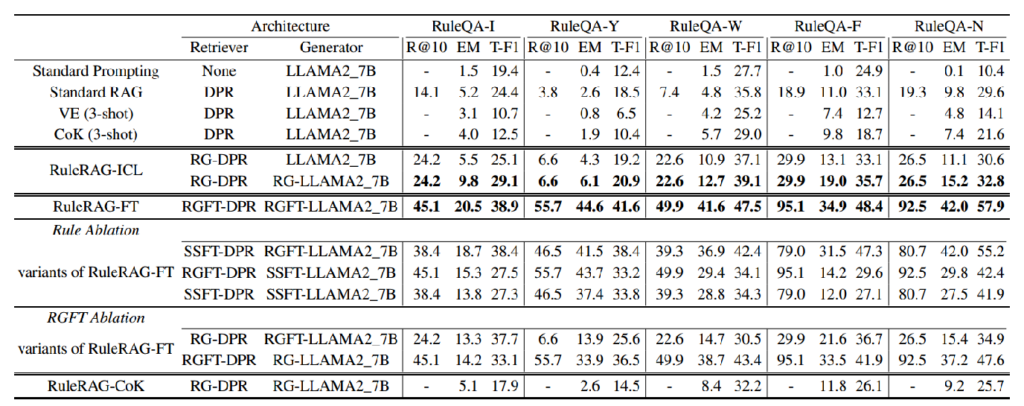
核心内容
RuleRAG通过引入规则指导检索和生成过程,显著提升了RAG模型在知识密集型问答任务中的表现。
在需要高精度和高相关性的场景下,如医疗问答、法律咨询等领域是具有很高的实际应用潜力。
使用知识图谱的规则挖掘算法,是一种RAG与知识图谱结合的应用