核心内容
- 本研究提出了一个利用知识图谱构建证据链来对检索得到的文档进行筛选,从而改善大模型回答多步推理问题的表现的RAG系统TRACE(consTructing knowledge grounded ReAsoning Chains to identify and integrate supporting Evidence)
- TRACE使用自回归推理链构造器来将知识图谱转化为证据链;其通过利用大模型不断地从筛选过的三元组中挑选证据链的新结点,自回归地构造出整个证据链来支持大模型对问题做出回答
- 在三个多步推理 QA 数据集上的实验结果表明,与使用所有检索到的文档相比,TRACE 的平均性能提高了 14.03%。结果表明,使用推理链取代完整文档作为上下文通常足以支持大模型完成许多多步推理任务。
背景
- 增强检索生成(RAG)是一种通过从文档(retrieve)中抽取有效片段并将其加入到提示词中来增强生成模型(一般是大模型)的生成效果的技术。RAG很擅长完成问题回答这类任务,但是由于RAG经常抽取到和需要回答的问题无关的片段,而这会对生成模型回答问题起到干扰作用。
- 由于大模型的生成效果对提示词极度敏感,因此无关片段被加入到提示词中之后会起到显著的误导作用[^1],严重影响大模型在多步推理问题回答这类任务上的性能。
- 为了更好地辨别出无关片段并且降低其影响,这篇文章主张将大段非结构化的文本转化为用一组三元组表示的知识图谱。这个做法相当于减小了颗粒度,判断三元组是不是和题干有关比较容易。
方法论
TRACE由以下组件组成:
- KG Generator(知识图谱生成器)
- 自回归推理链构造器
- Triple Ranker(三元组排序器)
- Triple Selector(三元组选择器)
设问题和标准答案为 $q,a$,针对问题 $q$ 抽取的一组文档为 $\mathcal{D}q={ d{1},d_{2},\dots,d_{N} }$ 。TRACE的运行步骤:
- KG Generation:用大模型将检索得到的文档转化为用一组三元组表示的知识图谱($\mathcal{D_{q}\to \mathcal{G}_{q}}$)
- 使用大模型对每个文档分别构造知识图谱,之后再合并相同的顶点形成完整知识图谱,这样可以避免大模型处理过长的文本造成性能下降($d_{i}\to g_{i},\mathcal{G}{q}=g{1},\cup g_{2}\cup\dots \cup g_{N}$)
- 由于本文使用Wiki页面作为检索源,其提供的文档都有标题。因此可以把标题作为一个实体,并且用大模型去推断标题和文档内各个实体的关系。这样可以让知识图谱的知识更加全面,可以提升整体性能
- Reasoning Chain Construction:将一组三元组用自回归+集束搜索的方式转化为一组推理链
- 要生成的推理链是也一组首尾相连的三元组 $z=z_{1},z_{2},\dots,z_{L}$,通过自回归的方式逐个生成结点;假定当前生成 $z_{i}$
- 用Triple Selector从候选三元组中挑选一个,作为推理链的下一个结点 $\hat{\mathcal{G}}{q},z{
- $\hat{\mathcal{G}}{q},z{<i},q$ 被出成一个选择题来对大模型进行提问;$z_{<i},q$ 组成题干;候选三元组 $\hat{\mathcal{G}}{q}$ 看作若干个选项,并且附加上一个选项「不需要额外的三元组」(相当于结束符);大模型选择的选项会被作为推理链的下一个结点 $z{i}$
- 重复 2,3 直到抵达推理链长度抵达L或大模型选择了「不需要额外的三元组」
- 本文希望生成多个候选推理链供选择,于是在自回归流程上使用了集束搜索来生成特定数量的一系列推理链
- 生成一个结点的过程就是大模型选择一个选项的过程,具体来说,是大模型生成选项对应的标号(比如A, B,…)。由大模型的结构可知,大模型会通过为每个token计算一个概率来决定最终生成哪个token,那么所有选项标号对应token的概率就可以作为集束搜索的评分依据
- Answer Generation:生成的推理链供生成器参考用于回答问题
- TRACE-Triple:构成推理链的三元组直接按顺序加入到提示词中
- TRACE-Doc:构成推理链的三元组一人一票,投票给自己的来源文档,来源文档按得票数降序排序加入到提示词中;其中没有获得投票的文档被看作是和问题无关,不加入到提示词中
实验
大模型配置:
- KG Generator:LLaMA3-8B-Instruct
- 自回归推理链构造器
- Triple Ranker:e5-mistral-7b-instruct
- Triple Selector:LLaMA3-8B-Instruct(同上)
- 生成器:多个大模型进行比较
数据集配置(每个问题都需要 2~4 步推理,并且给出了标准回答和 10~20 个参考文档,所有参考文档都来自于Wiki):
- HotPotQA
- 2WikiMultiHopQA
- MuSiQue
实验结果:
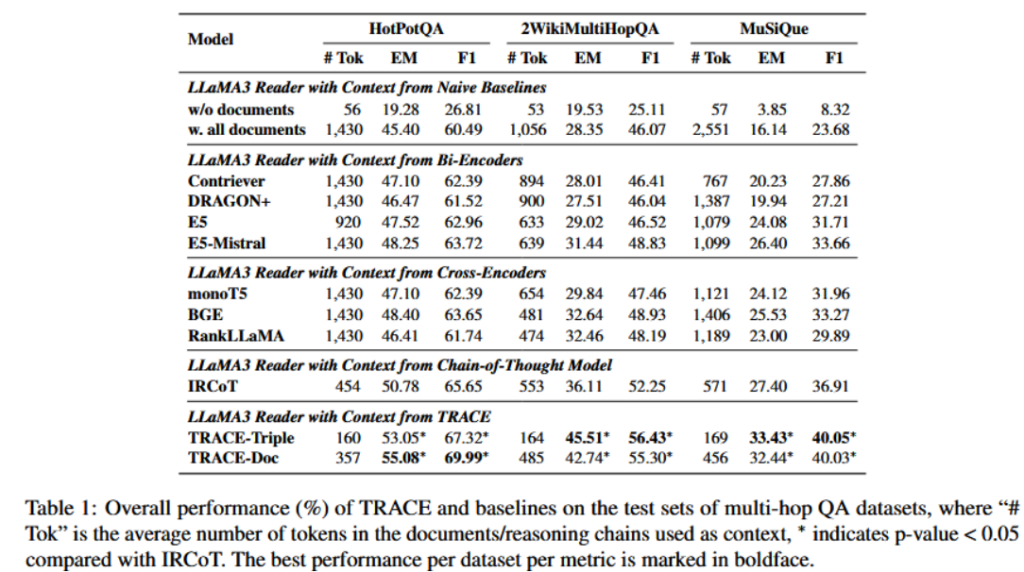

结果分析:
- TRACE在三个数据集上都获得了最优结果,而且置信度较高,说明TRACE有能力应对多步推理任务
- TRACE尤其是TRACE-doc,只是在原有的基础上对检索得到的文档进行了筛选,这证明了提示词中的无关信息对大模型推理性能的影响
结论
- 本文提出了TRACE,一个擅长于多步推理问题的RAG框架,其使用知识图谱生成器将检索得到的文档转化为知识图谱,并且构建出几条推理链;最终这些推理链被直接插入到上下文中或者用于识别有效的文档,辅助大模型生成更有逻辑性的回答
- 在多个多步推理数据集上的实验表明,TRACE比一般的RAG模型在这类问题上的表现提升了约 14%,并且可以用在不同的reader模型上面
启发与评价
- 大模型的自回归架构决定了其推理性能对提示词极度敏感,因此要提高RAG模型回答问题的能力,就需要尽量减少检索结果中的无关信息
- 大段非结构化文本不利于判定相关性,可以抽取为知识图谱三元组之后再做筛选
- 使用一组三元组,通过集束搜索自回归地生成一组推理链,这是一个证据链生成思路
[^1]: Mirzadeh I, Alizadeh K, Shahrokhi H, et al. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models[J]. arXiv preprint arXiv:2410.05229, 2024.