来源: IEEE Transactions on Intelligent Vehicles
作者:Yukai Hou, Jin Zhao, Rongqing Zhang, Xiang Cheng, Liuqing Yang
单位:同济大学
时间:2023
一、背景
随着无人机(UAV)技术的发展,其在未知区域搜索任务中的应用越来越广泛,如搜救、农业监测和城市规划等。然而,随着搜索场景的复杂性增加,现有的无人机群体搜索方法在可扩展性和高效协作方面面临挑战。特别是在大规模搜索任务中,依赖全局信息的准确性和实时性变得难以保证,因为全局信息收集受到空间和时间分辨率有限、通信延迟和数据质量不可靠等问题的影响。此外,复杂环境中障碍物众多、不确定性高、条件变化迅速,这些都加剧了搜索任务的难度。因此,需要一种能够适应这些挑战的新型搜索方法,以提高无人机群体在复杂和大规模场景中的搜索效率。
二、贡献
随着场景规模的扩大和任务数量的增加,现有无人机集群搜索算法在可扩展性和效率方面仍可能面临挑战,为了应对这些挑战,作者拆分了大规模搜索场景以整合本地信息,并提出了一种新颖的基于 MARL 的无人机集群搜索方法,以在无人机集群搜索场景中实现良好的可扩展性和效率。
1.提出了一种将大规模搜索场景分割为多个局部搜索区域的方法,以分布式方式提高无人机群体的搜索效率。
2.将搜索优化问题建模为马尔可夫决策过程(MDP),提出了一种基于MARL的无人机群体搜索方法,该方法在大规模顺序搜索场景中表现出低时间复杂度和高协作效率。
3.通过结合CNN,改进了MADDPG算法的网络模型,有效地处理了高维地图信息。
三、方法
1.系统模型和问题表述
实验环境是一个需要探索的混合大小的搜索区域,该区域有一队无人机和多个目标。无人机的任务是在尽可能短的时间内搜索该区域并找到所有目标。
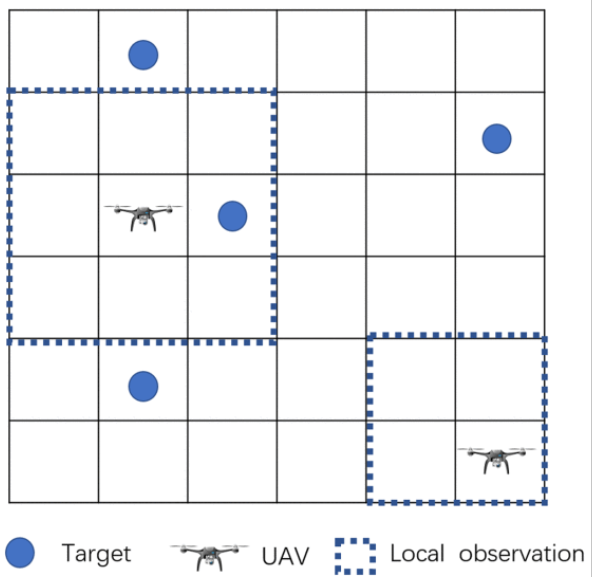
如图将搜索区域 E 划分为大小 DX×DY的网格图,每个网格代表一个搜索区,图中蓝点表示搜索目标G,无人机(表示为 u )的任务是探索未知环境并尽快定位所有目标。每个搜索区中只能包含一个目标或无人机。每个搜索区(x,y)的状态为Sx,y,值为1或0表示当前搜索区是否存在目标。搜素周期为T,分为多个时间步长t。
为了对目标的位置信息进行建模,使用概率分布函数来处理搜索问题,在搜索环境中,将概率函数转换为基于网格的目标概率图(TPM),其中每个网格即搜索区都有其存在目标的概率bx,y。bx,y通过贝叶斯以概率方式更新:
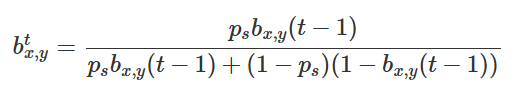
此外,ux,y(t)表示当前区域的不确定性,随着无人机搜索时间变化,即搜索区的不确定性会随无人机搜索而降低,同时目标概率也会更新。
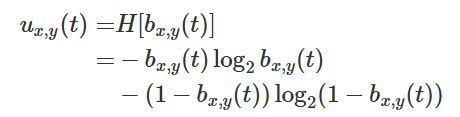
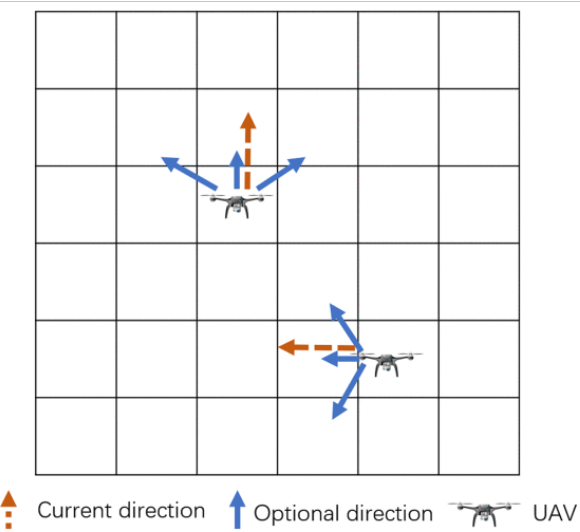
UAV移动:由于固定机翼,UAV每次只能移动到当前对准方向的三个相邻单元格。
无人机搜索优化函数:
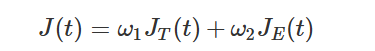
JT(t) 表示目标搜索的效用,JE(t) 表示环境搜索的效用,加权系数 ω1 和 ω2 用于平衡这两部分。
2.基于 MARL 的搜索优化
MARL 是一种强化学习算法,涉及多个代理与环境交互以及相互交互。代理学习根据来自环境的奖励信号和其他代理的行为做出决策。这允许协作决策和代理之间协调行为的出现。
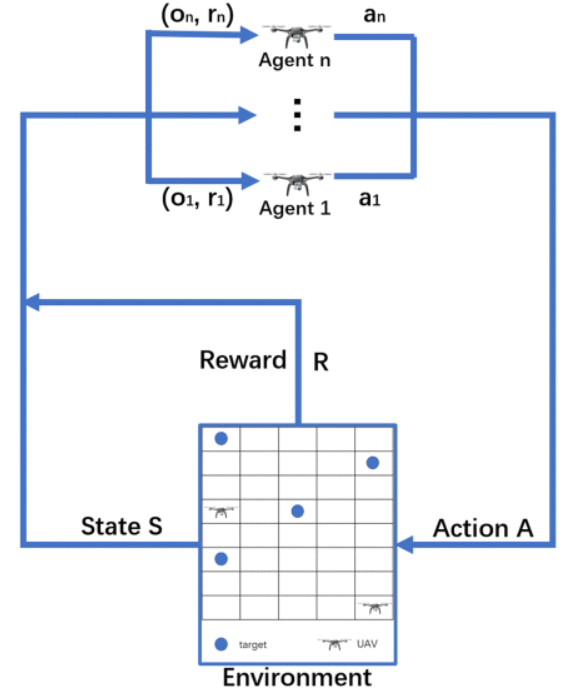
在搜索过程中,每架无人机在 TPM 及其传感器的帮助下探索搜索环境。此外,每架无人机都可以相互通信,以便获得其他人的位置和最新的 TPM。无人机 u 在时间段 t 的观测 Otu 定义如下:
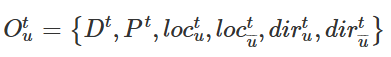
其中Dt是当前t时刻的本地信息,Pt表示当前最新的 TPM,loctu是无人机 u 在t时刻的位置 ,u¯代表除无人机之外的所有无人机 u,dirtu是无人机的飞行方向 u 。根据观察,每个 UAV 选择要执行的操作。
选择 MADDPG 算法来确定每个 UAV 的动作:
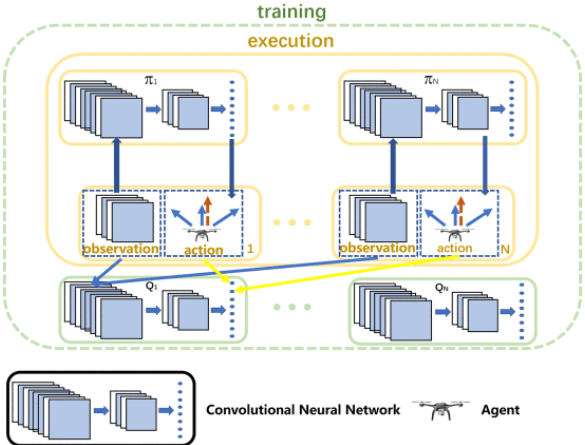
传统 MARL 中使用的网络模型通常是多层感知 (MLP),它包含三个层:输入层、隐藏层和输出层。MLP 中的每一层都是完全连接和线性的。然而,在搜索环境中,网格图是代理中观察的一部分,是一个二维矩阵。如果将其直接扩展到一个维度,则相邻层之间的关系可能会减弱。为了尽可能保留原始观测信息,采用卷积神经网络在MADDPG中构建网络模型。如图,MADDPG 的网络模型包含两种输入。CNN 模型接收网格地图信息,并使用三个卷积层和一个扁平化层处理数据。然后,一维输出与其他数据拼接在一起。最后,拼接后的数据由两个全连接层处理,并输出 one-hot 的 action 向量。
四、结果
参数设置:
在模拟场景中,网格图的大小设置为 50×50 单元格,其中先验信息为 none 。三架无人机在网格图中随机分布。目标的数量设置为不同的值 10,20,30,40 ,以指示所建议算法的泛化。此外,无人机不知道目标的位置。无人机经过 5000 步训练,然后在没有其他信息的情况下开始探索新环境。为了减少偶然性,显示的数据是 100 个实验结果的平均值。
效果评估:
为了验证所提出的基于 MADDPG 的搜索方法的性能,作者应用了两种方法与其进行比较。
DQN:基于 DQN 的无人机集群搜索方法。每个 UAV 都被视为一个部署 Q 网络模型的代理。观察和奖励设置与 MADDPG 相同。DQN 模型的结构类似于 MADDPG 中的价值网络模型。区别在于,DQN 中值网络的输入是代理的局部观察值,而 MADDPG 中值网络的输入是所有代理的全局状态。
ACO:基于 ACO 的无人机集群搜索方法。在搜索环境中,无人机通过信息素表选择其操作,该表具有 size 3×(DX×DY)×U 的三维矩阵,其中这些维度表示为操作数、网格图和 UAV 数。
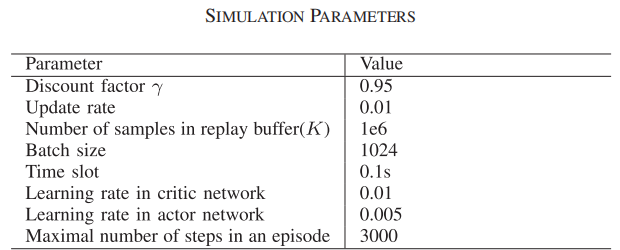
MADDPG与DQN 总体奖励的收敛性:
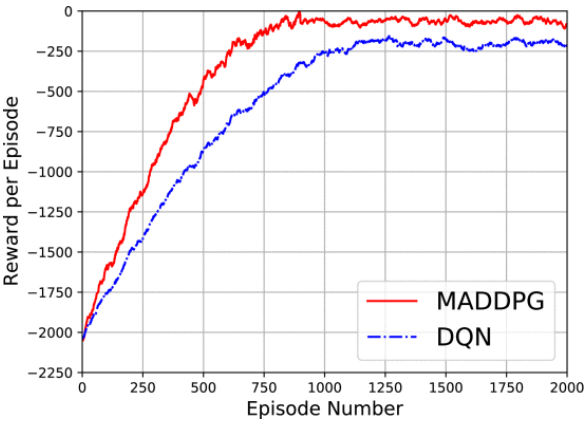
三种方法在不同步骤数下实现的覆盖率:
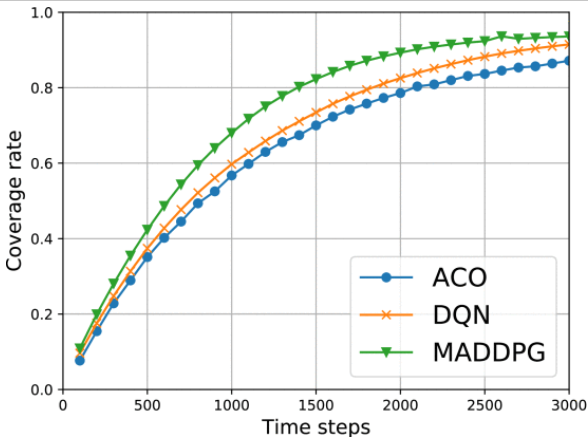
重复率(在探索过程中对先前搜索区域重复访问的百分比,是衡量搜索算法效率的重要指标):
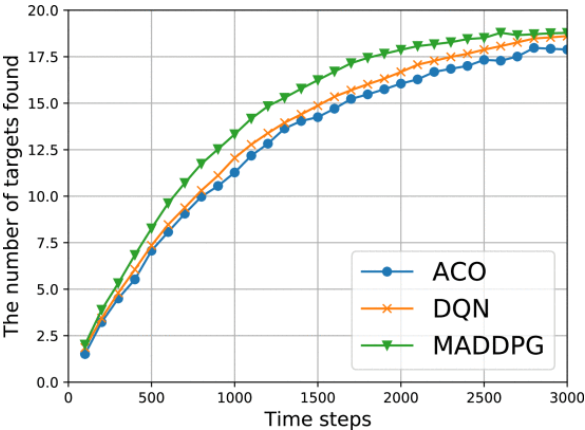
找到目标数:
使用不同数量的Agent找到的目标数:
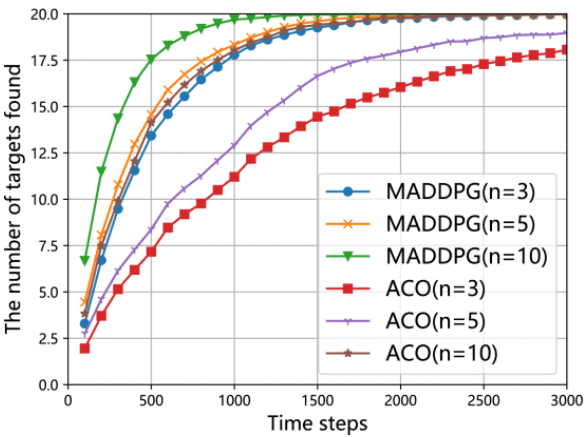
总体而言,实验结果表明,在协同多无人机搜索场景中,文章所提方法的性能优于基于 DQN 和基于 ACO 的方法。具体来说,与其他两种方法相比,基于 MADDPG 的方法可实现更高的覆盖率,每 100 个时间步长发现的目标更多,并找到探索步骤更少的所有目标。基于 MADDPG 的方法的优势主要归功于其协作机制,该机制允许无人机共享信息并协调行动以避免碰撞并提高效率。