来源:arXiv
作者:Jinfeng Zhou、 Zhuang Chen等
单位:清华大学、聆心智能等
发表时间:2023 年 11 月
一、背景
- 大语言模型:已经在多个领域展现出其强大的能力,然而,现有的LLMs在实现社交目标方面仍然存在不足,例如与人类建立长期社交联系或提供有效的情感支持。
- 提出CharacterGLM:为对话AI系统提供角色定制功能,以满足人们内在的社交欲望和情感需求。通过配置AI角色的属性(身份、兴趣、观点、经历、成就、社交关系等)和行为(语言特征、情感表达、互动模式等),可以定制各种AI角色或社交代理。
二、CharacterGLM实现
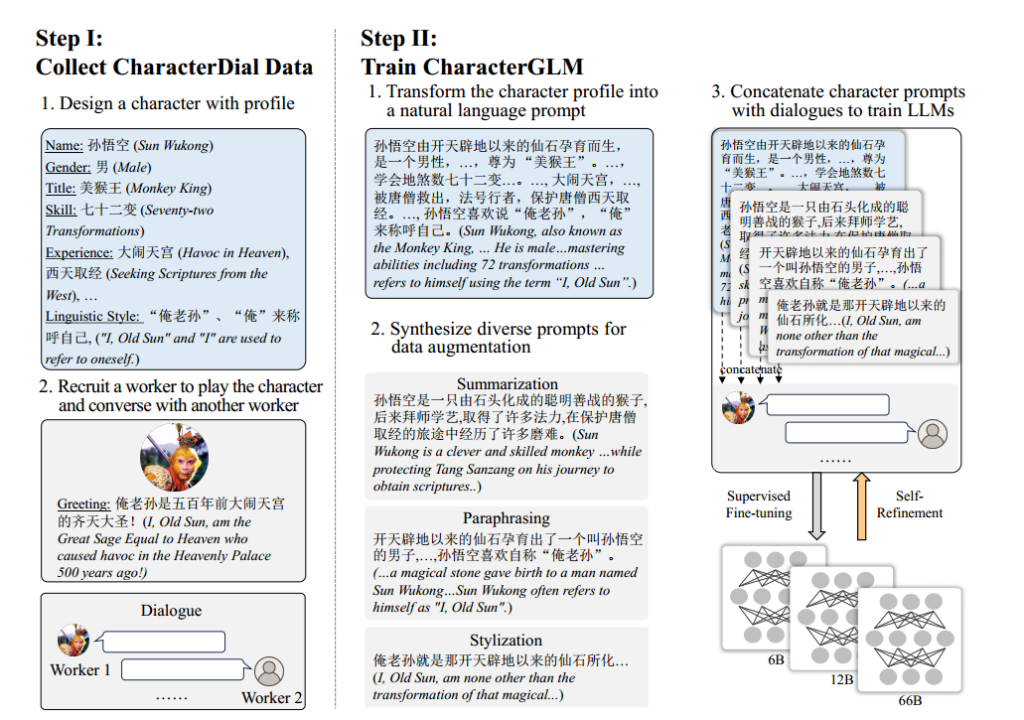
- 数据收集与角色对话
人类角色扮演(Human Role-Playing)
描述:招募众包工作者进行角色扮演,模拟真实对话。
过程:一个工作者扮演特定角色,另一个工作者扮演用户或其他角色。
大语言模型合成(Synthesis via Large Language Models)
描述:使用GPT-4等模型生成合成数据,以扩展数据规模和多样性。
过程:通过提示生成角色配置文件、对话主题和多轮对话。
文学资源提取(Extraction from Literary Resources)
描述:从剧本、小说等文学作品中提取角色对话。
方法:手动提取双方面对面的对话,并总结角色档案。
2. 训练大语言模型
角色提示设计(Character Prompt Design)
描述:将角色配置文件转化为自然语言提示,作为模型训练的基础。
方法:使用众包工作者将角色属性和行为转化为详细的自然语言描述。
监督式微调(Supervised Fine-tuning)
描述:使用不同规模的ChatGLM模型(6B到66B参数)作为基础模型。
过程:将角色提示与对话数据结合,进行微调训练。
自我完善(Self-Refinement)
描述:在模型部署后,通过收集人类-原型交互数据来进一步训练模型。
方法:将交互数据纳入监督式微调过程中,实现模型的持续自我完善。
三、CharacterGLM实验
- 点评估
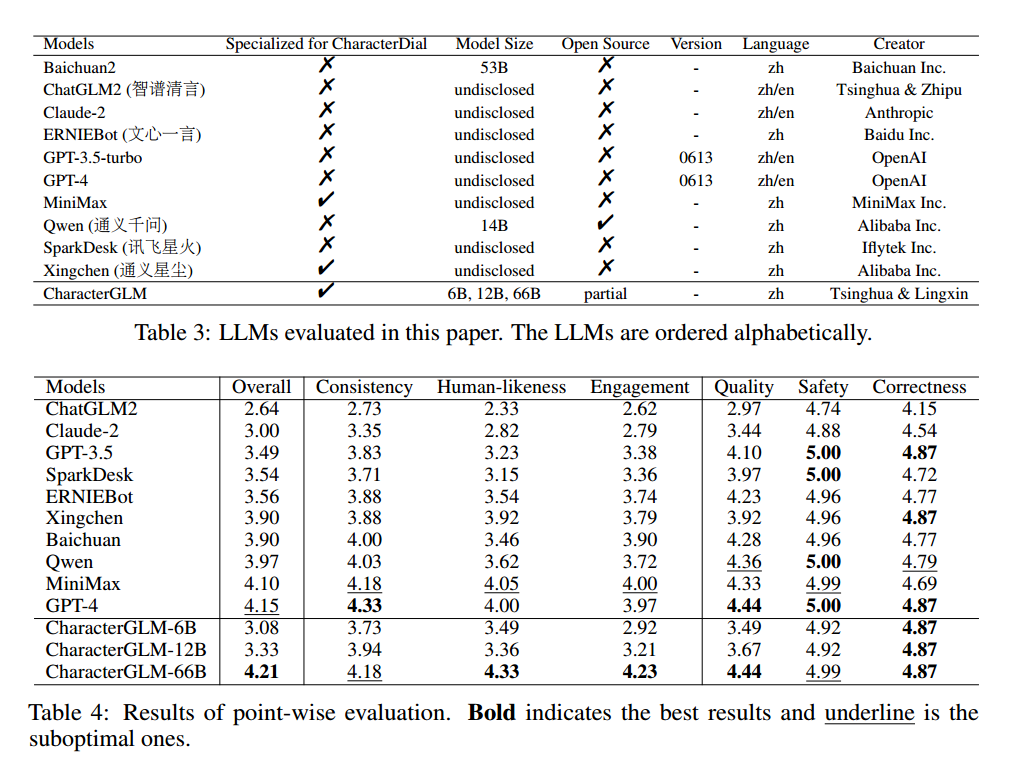
上述评估了11个精通中文任务主流LLMs,使用从1到5的评分范围,结果如表所示。
2. 细粒度误差分析
六个关键维度:
Out-of-character (OOC):与角色属性或行为不一致的响应。
Contradiction:与对话上下文或角色档案相矛盾的响应。
Repetition:重复对话上下文或角色档案内容的响应。
Less-quality:缺乏与对话上下文连贯性或质量较差的响应。
Less-informativeness (Less-info.):未能提供新或有信息量内容的响应。
Proactivity:主动引导对话主题并推动对话继续进行的响应。
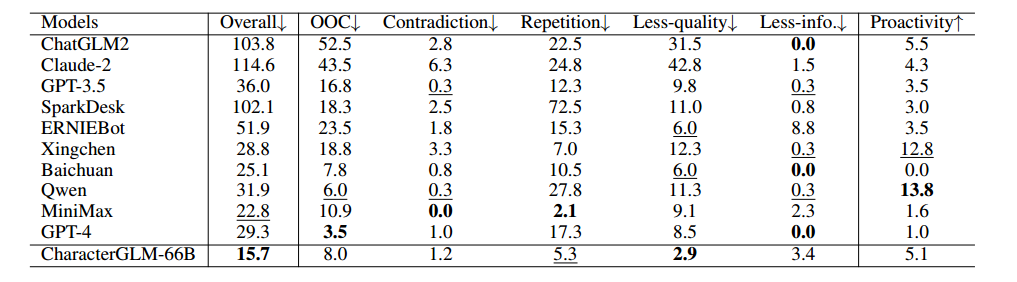
上述图片表明CharacterGLM-66B在会话级和回合级评估中产生的响应的总体质量都更好
3. 成对评估
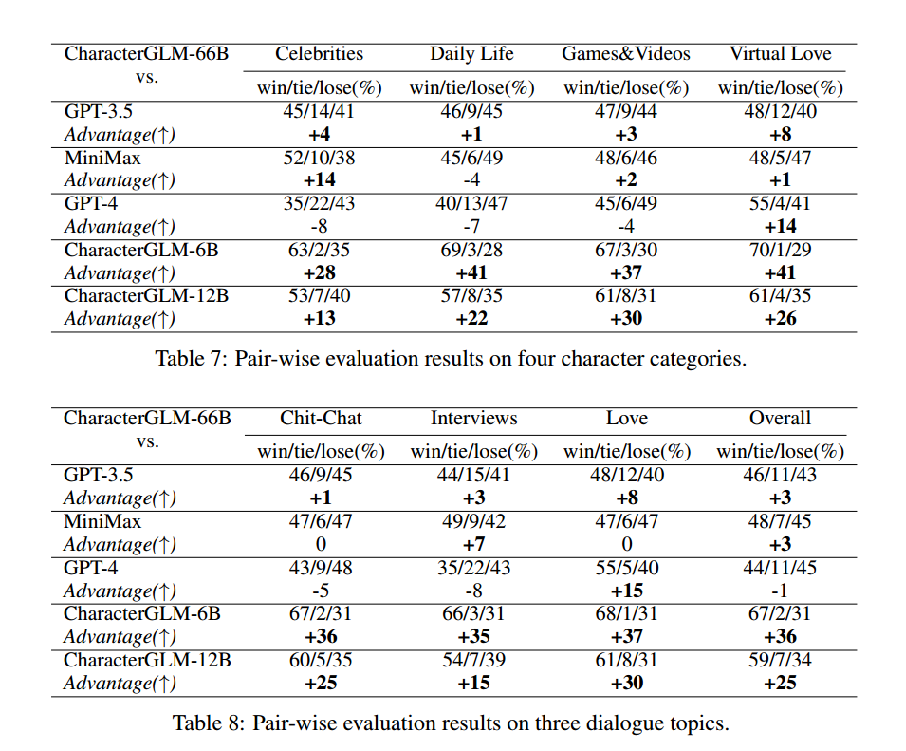
比较了CharacterGLM模型与其他模型(如MiniMax、GPT-3.5和GPT-4)在特定任务中的表现。具体指角色类别和对话主题
四、总结
- 论文核心内容
这篇论文介绍了一个名为CharacterGLM的系统,它是一系列基于LLM构建的模型,旨在生成以角色为基础的对话(CharacterDial)。
1. CharacterGLM模型的大小从6B到66B参数不等,目的是为对话式AI系统提供角色定制功能,以满足人们在社交和情感需求上的内在欲望。
2. CharacterGLM的实现包括基于角色的对话收集和训练LLM进行基于角色的对话生成。作者采用了多种数据收集方法,包括人工角色扮演、通过大型语言模型合成数据和从文学资源中提取对话。
- 综合对其思考
- 可以收获的地方:
CharacterDial任务:首次提出CharacterDial任务,设计了一个大规模的中文对话数据集,包含真实和虚拟角色的多种场景和话题,为角色个性化对话提供了丰富的资源。
深度角色定制:CharacterGLM实现了全面的角色个性化设定,覆盖了身份、兴趣、观点、经历、社会关系等属性,并支持定制角色的行为特征,不同于传统的“人格化对话”。
2.可以改进的地方:
多模态交互:该文CharacterGLM专注于文本对话,但现实世界的社交互动往往是多模态的,包括视觉、听觉和触觉线索,为增强用户体验后期应考虑扩展系统。
社交互动:该系统主要关注AI角色与用户之间的互动,后期可以探索AI角色之间的社交互动,形成一个“角色社会”。