作者:Davide Borsatti,Walter Cerroni,Luca Foschini,Genady Ya Grabarnik,Lorenzo Manca
发表期刊:IEEE TRANSACTIONS ON NETWORK AND SERVICE MANAGEMENT
发表日期:2024年8月
一、背景
1. Kubernetes 应用的复杂性:Kubernetes 是云计算中常用的编排平台,但其配置管理复杂且庞大。
2. 配置优化难度:多种配置参数和控制循环使得在实际部署前优化 Kubernetes 配置变得困难。
3. 数字孪生的引入:数字孪生技术可以通过虚拟模拟物理系统,帮助进行配置优化和性能评估。
4. Kubernetes 数字孪生的需求:创建 Kubernetes 的数字孪生可在不影响真实系统的情况下进行虚拟测试和优化。
5. 多层级计算环境的价值:在边缘和云环境中使用数字孪生有助于资源分配和延迟优化。
二、创新点
1. Kubernetes 专用数字孪生框架:首次提出专门为 Kubernetes 设计的数字孪生框架 KubeTwin,用于配置优化和性能预测。
2. 多层级资源建模:支持对边缘和云的多层级计算环境进行精细化仿真。
3. 细粒度应用仿真:能够模拟服务请求路径、网络延迟等细节,进行多种配置的“假设”分析。
4. 自动扩展与调度优化:支持动态调整副本数和自定义调度策略,优化资源分配。
5. 高效的离散事件仿真:采用离散事件仿真技术,实现对 Kubernetes 控制逻辑的高效模拟。
三、KubeTwin框架设计
KubeTwin 通过模拟 Kubernetes 的编排和网络行为,使服务提供商能够在更小的资源开销下,准确评估复杂大规模的 Kubernetes 部署场景。该框架支持声明式的应用定义,允许用户指定与 Kubernetes 语义等效的应用描述,以便于重新模拟和评估服务。

主要组件:
• KTService:表示 Kubernetes 服务,支持通过负载均衡策略将请求分配到不同的 pods 上。
• KTDNS:提供命名解析功能,帮助在模拟环境中定位服务。
• KTReplicaSet:控制 pod 的副本数量,监控 pod 状态并在需要时增加或减少副本。
• KTScheduler:管理资源的调度,根据配置策略选择合适的计算节点。
• KTPodScaler:实现自动扩展功能,基于当前的负载动态调整副本数量。
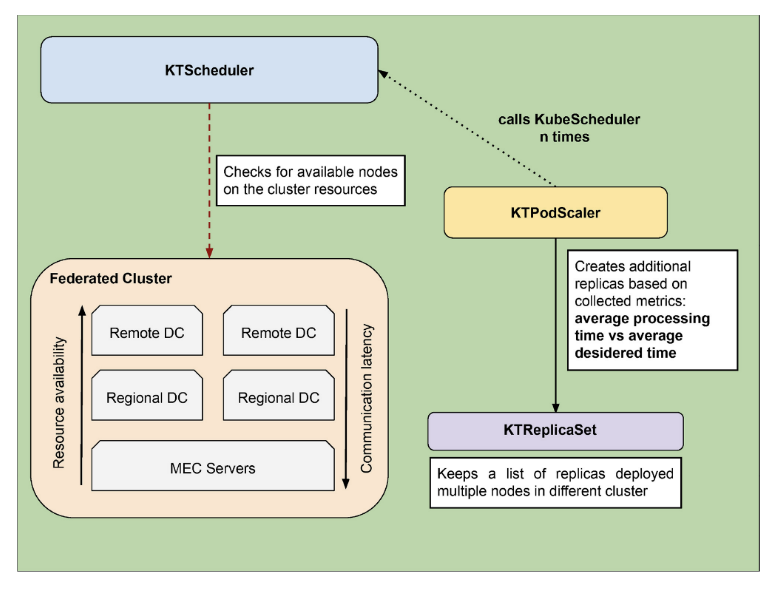
上图流程展示了 KubeTwin 如何利用 KTScheduler 和 KTPodScaler 的协作来实现 Kubernetes 的资源管理和自动扩展,从而在不同负载情况下高效地分配资源,同时考虑了资源可用性和通信延迟等因素。
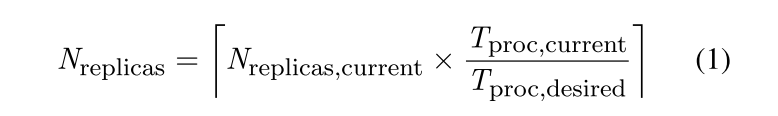
此公式的作用是根据当前的负载动态调整副本数量。调整时也会考虑预设的副本数上限和下限,以避免资源过载或不足的情况。
四、实验及结果
1. 部署配置优化实验
• 实验设计:在包含边缘数据中心(MEC)、区域数据中心(Tier 1、Tier 2)、和远程云的数据中心环境中,部署了一个图像识别应用。实验通过改变微服务副本数量,测量了不同配置下的响应时间(TTR)。
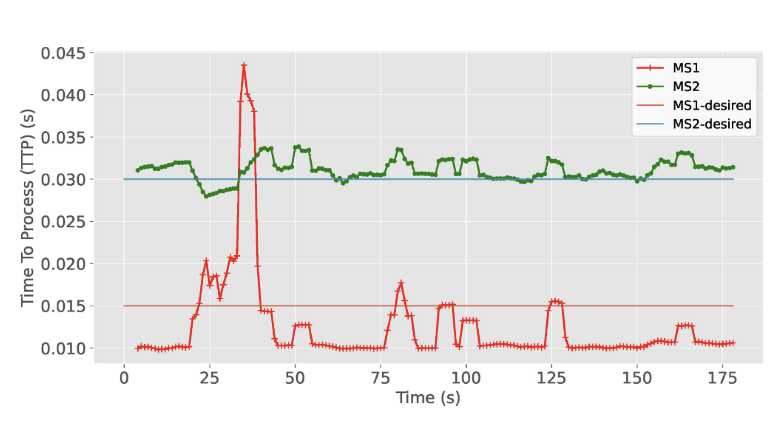
• 结果:实验表明,配置 9 个副本可满足目标 99% 请求的 TTR 小于 60ms。进一步增加副本数量的效果不明显。实验帮助确定了最佳的部署配置。
2. 自动扩展功能验证实验
• 实验设计:通过设置动态变化的负载,测试 KubeTwin 自动扩展组件(KTPodScaler)在负载增加时的响应。实验在负载增加后自动调整副本数量,以避免响应时间超出预期。
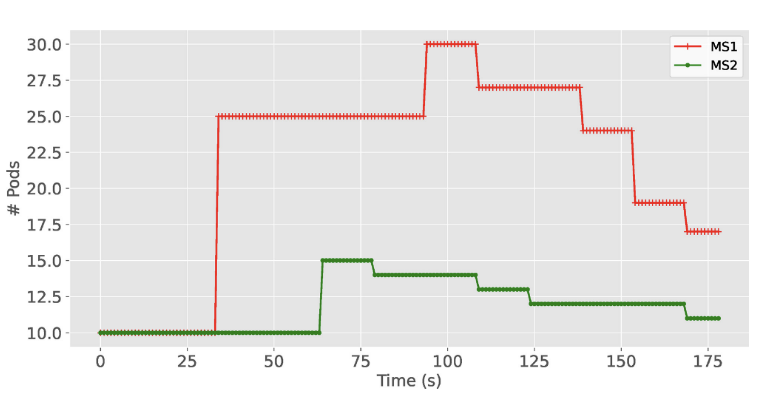
• 结果:KTPodScaler 在负载增加时成功扩展了副本数量,将 MS1 微服务的副本数增加至 30,MS2 增加至 15,以适应峰值工作负载。同时,在负载下降时,自动缩减副本数。这验证了 KubeTwin 在高负载下的自动扩展能力。
五、总结
KubeTwin 作为一个数字孪生框架,可以有效模拟 Kubernetes 部署的复杂场景,帮助服务提供商在真实部署前找到最佳配置。此外,KubeTwin 提供了灵活的网络和负载模型,适用于边缘计算和云计算的多层级环境。