作者:Wang Yuancheng等
单位:香港中文大学(深圳),广州趣玩网络
来源:arXiv 2024
一、主要内容
大规模文本到语音(TTS)系统常被分为自回归和非自回归两种,自回归隐式建模持续时间但鲁棒性和持续时间可控性方面存在缺陷,非自回归需要训练文本和语音之间明确对齐信息,可能会损害自然性。这篇文章介绍MaskGCT,完全非自回归TTS模型,消除文本和语音之间显式对齐以及音素级持续时间预测。MaskGCT分从文本预测语义标记和基于语义标记预测声学标记两个阶段。实验表明MaskGCT在质量、相似性和可理解性方面优于目前sota的零镜头TTS系统。
二、方法
MaskGCT和现有系统的比较:

MaskGCT是一个两阶段TTS系统,第一阶段使用文本预测语音语义表示标记,包含了大部分的内容信息和部分韵律信息,第二阶段模型被训练来学习更多的声学信息。

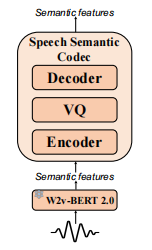
语音语义表示标记
语义标记一般是通过从语音自监督学习中离散特征获得的,语义标记与文本或音素之间有更强的相关性。以往工作使用K-Means聚类来离散语义特征,可能会丢失信息,特别是对于普通话这种声调丰富的语言。这篇文章先训练了一个VQ-VAE来学习一个码本,从语音自监督学习模型中重构语音语义表示。总损失为:
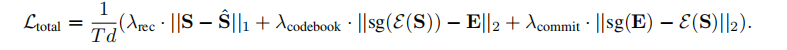
其中sg表示停止梯度。
对于VQ-VAE训练,使用W2v-BERT 2.0的第17层隐藏特征来训练,结合因子分解codec技术,码本大小8192,码本尺寸8。
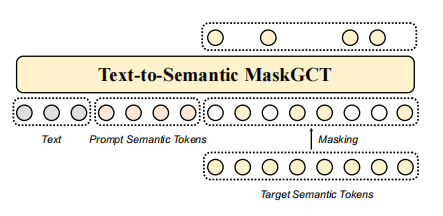
文本到语义模型
使用非自回归掩码生成transformer来训练一个文本到语义模型。随机提取语义标记序列的部分前缀作为提示,将文本标记序列和提示作为前缀序列添加带输入的掩蔽语义标记序列中,以利用语言模型的上下文学习能力。使用一个llama风格的transformer作为模型主干,结合GELU和旋转位置编码,双向注意取代因果注意,使用自适应RMSNorm,接受时间步长作为条件。
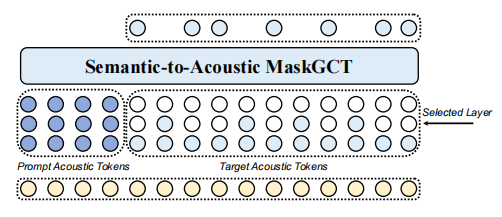
语义到声学模型
语义到声学模型基于SoundStorm,生成多层声学标记序列。给定1到N层中选择一层j,训练模型在提示、相应的语义标记序列和所有小于j层的声学标记的条件下预测j层声学标记。推理过程为每一层使用迭代并行解码,从粗到细生成标记。
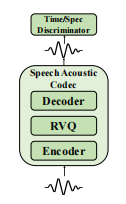
语音声学编解码器
遵循残差向量量化(RVQ)的方法将24K采样率语音压缩为12层离散标记,每层码本大小1024,码本维数8。模型架构、鉴别器和训练损失遵循DAC,使用Vocos作为解码器。
其他应用
除了零镜头TTS之外,在持续时间可控的语音翻译、情绪控制、语音内容编辑和通过简单修改的语音转换上,MaskGCT展示出作为语音生成基础模型的潜力。
三、实验结果
实验设置
数据集:Emilia的英文和中文数据,每个数据都有50K小时的语音时间,在LibriSpeech test-clean,SeedTTS test-en和SeedTTS-zh上评估零镜头TTS模型。
评价指标
客观指标上评估说话人相似度SIM-O,词错率WER和语音质量FSD。
主观指标上使用比较平均选项评分CMOS和相似度平均选项评分SMOS来评价自然性和相似性。
基线模型:NaturalSpeech 3,VALL-E,VoiceBox,VoiceCraft,XTTS-v2和CosyVoice。
实验结果
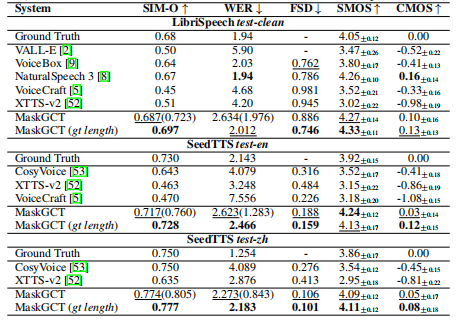
与基于自回归模型相比:
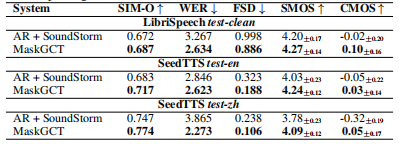
在口音模仿上的指标对比:
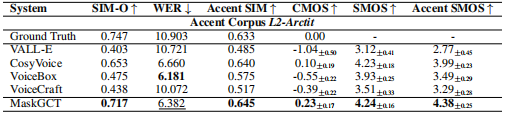
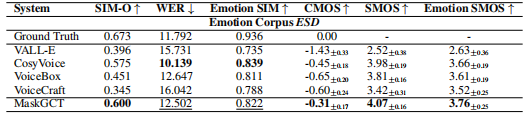
在情绪模仿上的指标对比:
消融实验
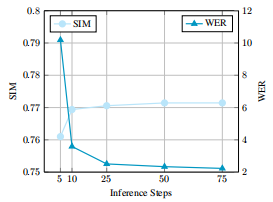
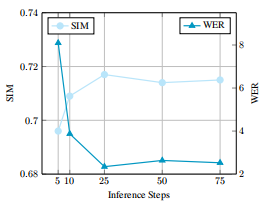
推理时间步数对结果的影响:
SeedTTS test-zh上的结果:
SeedTTS test-en上的结果:
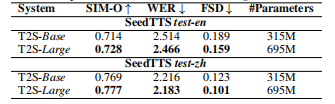
不同模型大小下的性能差异:
四、总结思考
1、在自监督学习语义模型的基础上,用向量量化的方法离散化特征能够改善K-Means聚类过程导致的信息丢失的问题。
2、相比于语义标记,声学标记包含更多的音色和韵律等声学信息,合成的语音具有更高的质量和可懂度。
3、语义标记与文本和音素的关联性比声学标记更高,从文本预测语义标记,再由语义标记预测声学标记,既能保持高度相关的内容特征,也能补充缺乏的韵律特征。