核心内容
- 本文给出了一个用于检测事实错误型机器幻觉的基准数据集 FactCHD。FactCHD 大约包含 5.8 万个样本,每个样本由一段人与大模型对话的文本、大模型的回答是否存在事实性错误的标签和给出这样的标签的理由(证据链)。FactCHD 的数据包含四种事实模式,要求模型不仅可以判断出对话内容是否含有事实错误,还要给出证据链解释支持自己的判断;
- 本文提出了一种基于大模型的方法可以充分利用现有的知识图谱(KGs)来构造数据集。相比传统的方法,这个方法可以节省大量人力的同时保证数据集的数据质量和广度;
- 本文还基于「三角互证」的思路设计了 Truth-Triangulator 框架,这个框架通过多个大模型之间的交叉验证来提高识别机器幻觉以及给出合理解释的能力。
背景
- 大语言模型由于认知能力限制以及学习了训练数据中的错误、过时知识的原因,经常会生成包含事实性错误或者表达过于模糊的文本,作者认为这就是机器幻觉的本质。机器幻觉严重阻碍了大语言模型在许多领域上的应用;
- 过去的事实验证任务一般只要求判断一段话中是不是存在事实性错误,和大模型的问答对话不一样,不能直接适用;
- 过去的幻觉检测基准往往只包含直接推理这一个类型的事实模式,没有在这方面做更深的研究。这一个类型难以覆盖全部的事实性错误,这导致现有的事实性错误型幻觉检测效果都不理想。
方法论
事实模式
事实模式指的是回答某问题所需要的逻辑方法。
作者在问题的事实模式上做了更深入的研究,他把事实模式分为机器幻觉中提到的四类:直接推理(vanilla)、多步推理(multi-hops)、比较(Comparison)、集合操作(Set-Operation)。
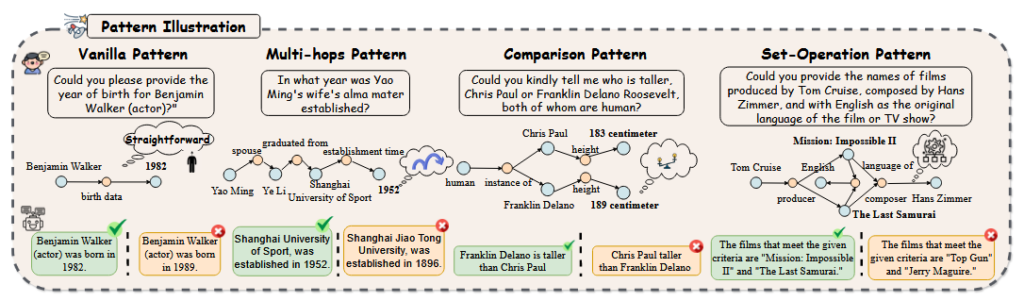
- 直接推理:从一段资料中直接寻找答案进行回答即可,只需要推理一次;
- 多步推理:需要基于多段材料中做多次推理才能得到答案;
- 比较:需要进行比较大小之类的操作才能得到答案;
- 集合操作:需要判定元素属于哪个集合才能得到答案。
之前的幻觉检测基准数据集基本上只包含直接推理这一种事实模式,而 FactCHD 包含这四种事实模式。
数据集构造
- 构造示例(demonstration):人工收集相关问题并且手动向开源 LLM 提问,获得对话文本;再人工判断大模型的回答是否出现幻觉,并且打上标签;
- 生成对话文本:收集已有的知识图谱或者文本类型的知识数据,将其归为四类事实模式,并且加入到提示词里面提供给 ChatGPT。在这些资料的支持下,要求 ChatGPT 在指定了是否要出现幻觉的情况下生成类似示例的对话文本;
- 语义去重:使用 SBERT 对生成的对话文本数据进行语义编码,比较不同样本之间的语义相似度,删去语义相似度过高的样本,保证不同样本内容不重复;
- 生成证据链:让 ChatGPT 基于前文收集的知识数据和对话文本生成能够给标签提供支持的证据链;此证据链在之后会被用于评估大模型解释能力;
- 人工筛查:由多个受教育的人类标注员对所有的生成数据进行检查,去除不良数据。
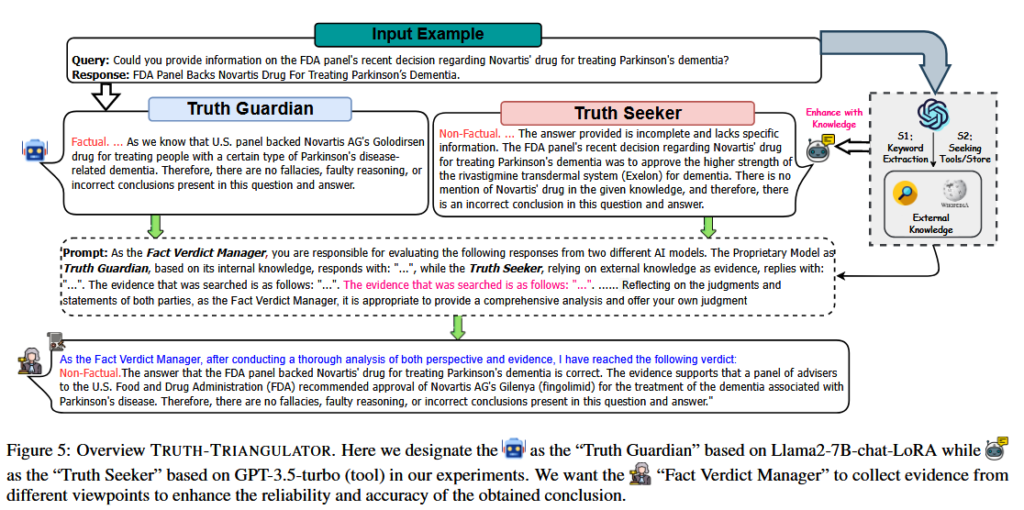
Truth-Triangulator
Truth-Triangulator 是一个基于三角互证法的思路设计的框架,它使用三个大模型分别扮演三个角色:
- Truth Guardian:经过微调训练,使用内在知识进行判断
- Truth Seeker:拥有检索能力,检索外在知识进行判断
- Fact Verdict Manager:总结前二者的判断和理由,生成最终的判断
实验
本文除了构造数据集,还通过实验验证了现有大模型在不同方法下识别机器幻觉以及生成证据链的能力。
评价指标
- FACTCLS:模型在判断对话文本是否出现了机器幻觉这个分类任务上的 Micro F1,FACTCLS 衡量了模型识别机器幻觉的能力;
- EXPMATCH:证据链文本可以分为介绍说明部分(一般在首段、末段)和核心解释部分(一般占据主体)。把生成的证据链和参照证据链的这两部分分别进行最长公共子序列匹配,计算出相似度 $Score_{ht},Socre_{bd}$ 再赋予不同的权重即可得到 EXPMATCH;EXPMATCH 衡量了模型实施推理、生成证据链的能力。
实验步骤
选取了 5 种大模型参与实验,按照条件不同分成若干组:
- 对照组:不进行任何操作,直接在 FactCHD 上评估其识别机器幻觉和生成证据链的能力;
- 实验组:
所有组都在 FactCHD 的测试集上进行测试,通过计算 FACTCLS 和 EXPMATCH 两个指标来比对结果好坏。
实验结果

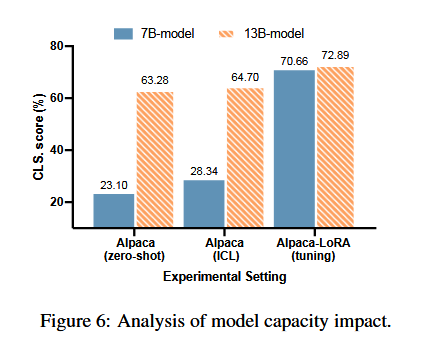
- 对照组的效果比较差;
- 相比对照组,在提示词中增加示例对除了 text-davinci-003 之外的模型提升作用很明显;
- 相比上下文学习组,LoRA 微调给所有模型的效果都带来了巨大提升,尤其是 Llama2-7 B-chat;
- 在微调基础上进行检索增强带来的提升比较小;
- 相比上下文学习,工具增强带来提升较大;
- Truth-Triangulator 显著减少了错判,获得了最佳效果;
- 微调法提升参数量大的模型的作用很有限,远不如参数量小的模型。
结论
- 介绍了 FactCHD,一个专门用于评估大模型事实性错误幻觉的基准数据集,包含多种事实模式的数据并且强调了可解释的证据链文本的重要性;
- 提出了 Truth-Triangulator 框架,其采用三角互证法鉴别信息真实性,最后由仲裁者给出结论;Truth-Triangulator 展现出比较好的幻觉识别能力和解释能力。
启发与评价
- 大模型虽然具备相关潜能,但是仍然需要一定的帮助才可以发挥出逻辑思考能力;根据本文的实验分析可知,随着大模型的规模越来越大,微调这一策略可能上限并不高;
- 大模型和人脑具有高度相似性,「 三角互证法 」可以迁移到大模型上面获得更好的效果,那其他强化人类逻辑思考能力的方法也许也可以;
- 文本形式的证据链一般可以分为「概念说明」+「核心解释」两个部分,概念说明可以看作图结点的声明,核心解释则是将结点用逻辑关系串起来。至于如何构造好的文本形式,这方面可以参见某些修辞学研究;
- 本文构造的数据集其核心创新是归纳了四种事实模式以及将证据链解释也引入进数据集中,但是作者没有讨论有没有更多其他的事实模式,也没有考虑若干中事实模式组合起来的情况。此外,评估证据链文本好坏的指标 EXPMATCH 是基于文本匹配的,不考虑文本的语义是否相似;这导致 EXPMATCH 这个指标缺乏说服力。