来源:ACM SIGIR
作者:Shengyao Zhuang、Honglei Zhuang等
单位:CSIRO、Google Research
发表时间:2024 年 7月
研究背景
LLM-based Zero-shot Ranking 的效果—效率矛盾
大语言模型已被广泛用于零样本文档重排序任务。
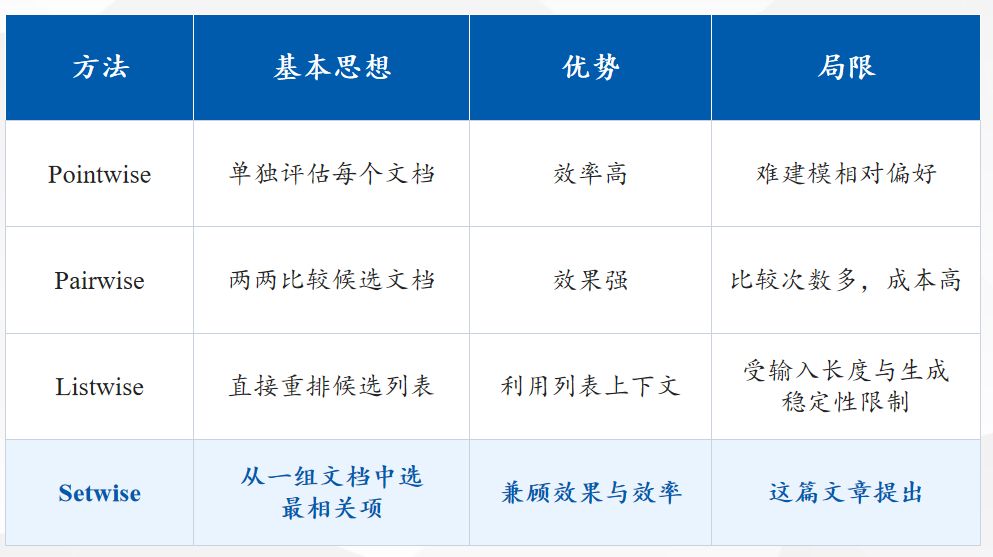
现有方法主要分为 Pointwise、Pairwise 和Listwise 三类。它们在排序效果与推理效率之间存在明显权衡。
如何在保持较高排序效果的同时,显著降低 LLM 推理开销?
这篇文章提出Setwise —— 一种全新的集合级(Setwise)提示方法,旨在解决现有技术中效果与效率难以兼得的痛点
主要框架
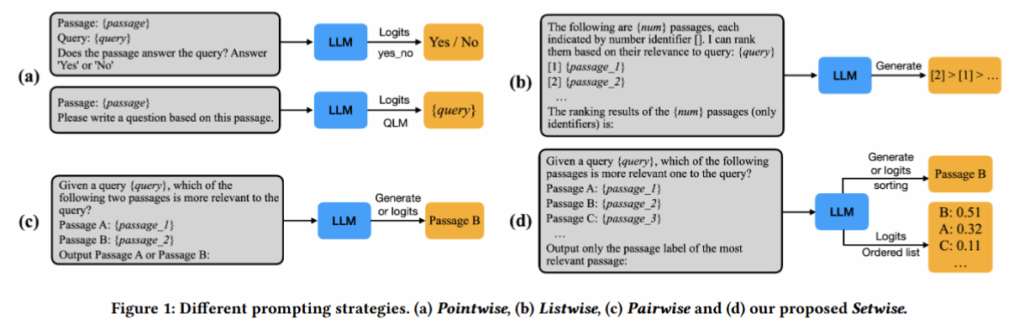
四类 Prompting 范式对比
Setwise 可以视为对 Pairwise 思想的自然扩展:比较粒度从 2 个候选提升到 1 个候选集合。
- Setwise 的核心思想:一次比较多个候选
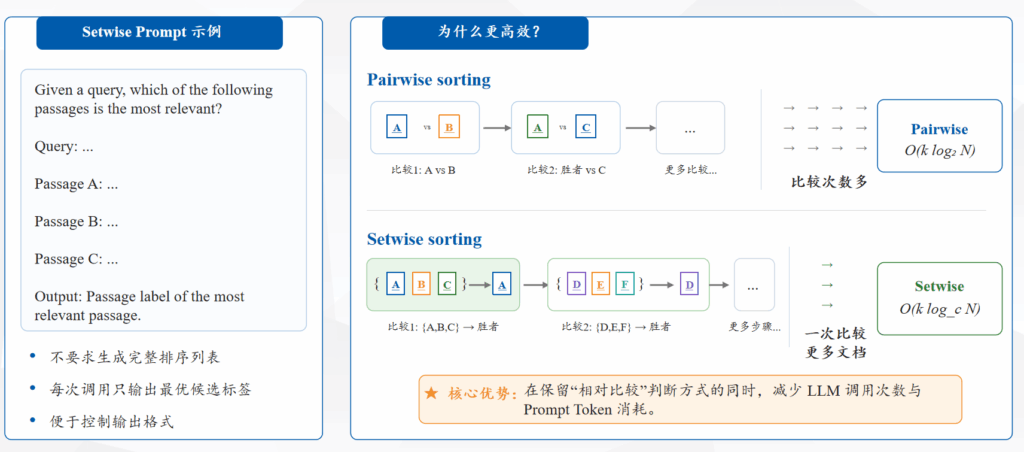
- 对 Listwise 的改造与方法性质总结

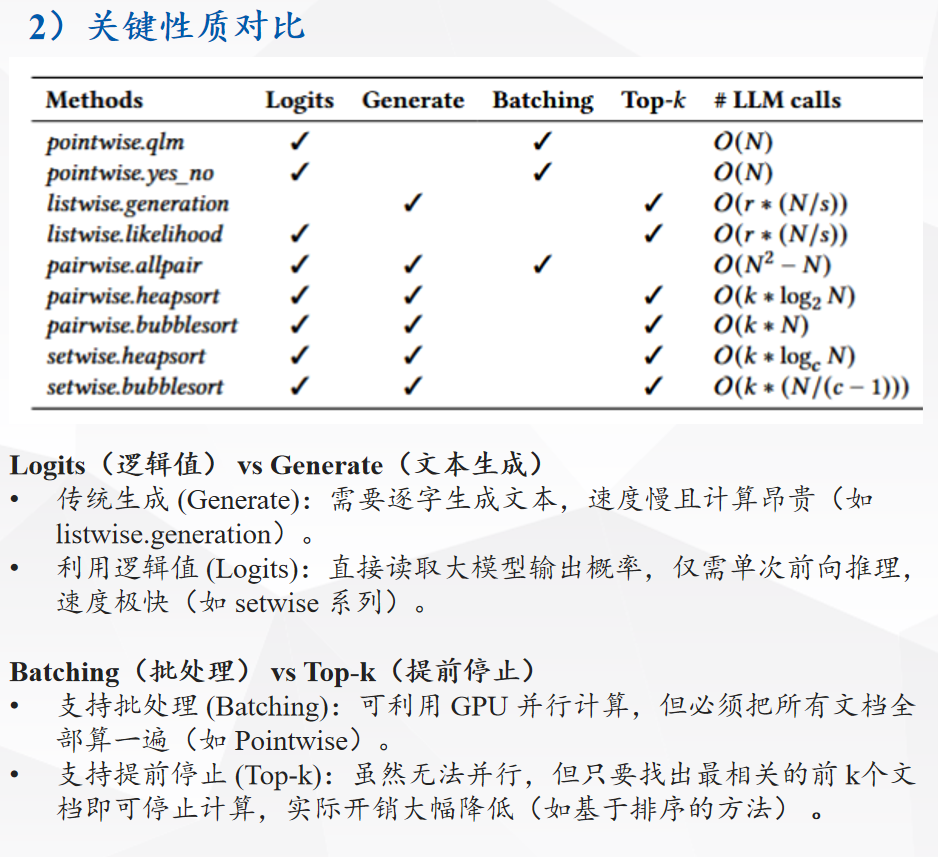
实验
实验设置
任务与数据集
核心任务:对 BM25 检索出的前 100 篇候选文档进行大模型零样本重排,目标找出 Top-10 。
权威数据:TREC DL 2019/2020 以及涵盖多领域的 BEIR 基准数据集 。
参测模型
主实验基准:Flan-T5 系列(780M / 3B / 11B 参数),用于严格控制变量的公平对比 。
拓展验证:Llama2-7b、Vicuna-13b 以及闭源的 GPT-3.5-turbo 。
评估双维度:效果 vs. 效率
效果(排得准):采用官方评测指标 NDCG@10 。
效率(排得快):全面考核 LLM 调用次数、Token 消耗量(输入与生成)、以及单次查询硬件延迟(Latency) 。
关键超参数
Setwise 核心设定:每步让大模型同时对比 3 篇文档(c=3) 。
上下文限制:单篇文档最大截断至 128 Tokens 。
总体性能
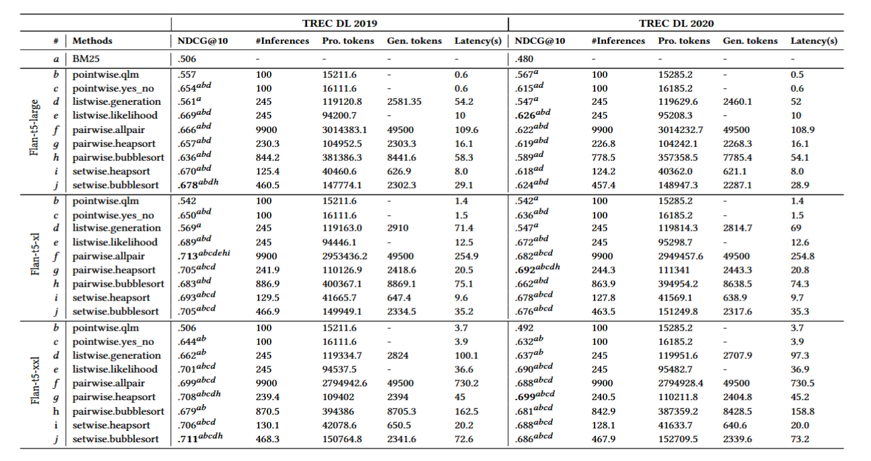
Pointwise虽然由于支持批处理而速度最快,但排序准确度较差,且其效果甚至会随模型尺寸增大而下降 ;
Pairwise和Listwise虽然准确度较高,但计算成本极为高昂,尤其是列表法在小参数模型上表现极差 。
Setwise不仅让列表法在小模型上也能发挥出强大的性能 ,更在保持与最优成对法同等顶级排序准确度的前提下,将大模型推理次数、Token消耗和查询延迟等计算成本大幅削减了约62% ,完美实现了排序效果与效率的双赢 。
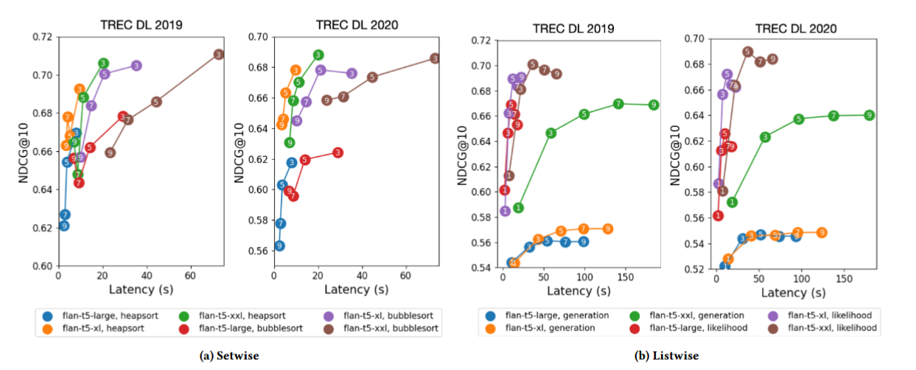
综合对比
将 (a) 和 (b) 放在一起对比,核心观点是:
Setwise 方法 (左图) 比 Listwise 方法 (右图) 提供了更好的“性价比”。
效率优势: 在达到相同 NDCG 效果(比如 0.68)时,Setwise 方法(左图)所需的延迟通常低于 Listwise 的 Likelihood 方法(右图)。
效果优势: 在相似的延迟下,Setwise 方法往往能获得比 Listwise Generation 方法更高的准确率。
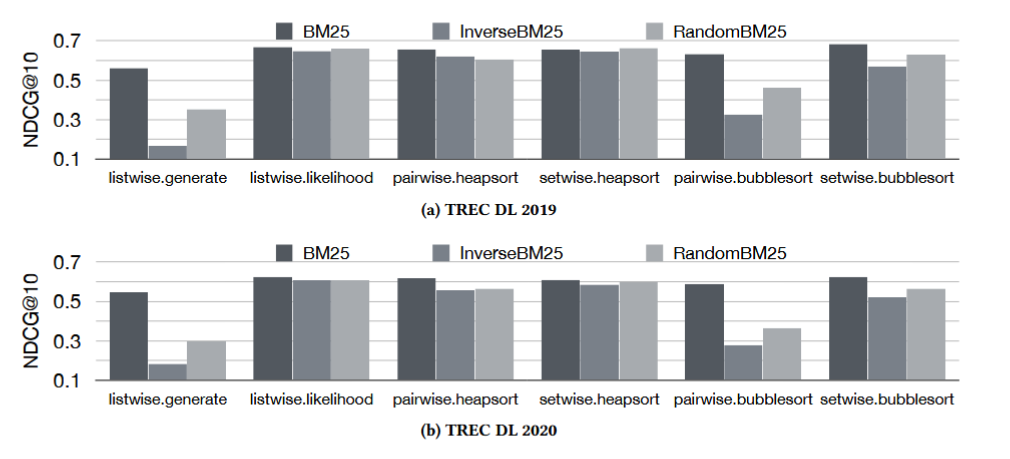
展示不同重排方法对“初始排序质量”的依赖程度。
它的核心结论是:Setwise Heapsort 方法最稳健(Robust),它几乎不受初始排序好坏的影响;而 Listwise.generate 方法非常脆弱,严重依赖初始排序。
总结与综合对齐思考
这篇论文核心创新点主要集中在算法设计和鲁棒性两个方面。其核心贡献包括:
提出了基于 Setwise 比较的堆排序框架:文章摒弃了传统的 Listwise(全列表生成)或简单的 Pairwise(两两比较)方法,提出了一种Setwise Heapsort 策略。
核心逻辑: 利用大语言模型一次比较 c 个文档(Setwise),并结合堆排序算法的逻辑来组织这些比较。
优势: 这种策略在排序效率(大模型调用次数/延迟)和排序效果(NDCG)之间取得了更好的平衡,比传统的冒泡排序或全列表生成更高效。
解决了重排模型对“初始排序”的依赖问题:文章发现现有的 Listwise 生成式方法对输入的文档顺序极其敏感(如果输入顺序被打乱,效果会崩塌)。
核心突破: 证明了 Setwise Heapsort 具有极强的鲁棒性。
优势: 无论初始检索结果是正序、倒序还是随机打乱,该方法都能稳定地输出高质量的排序结果,不再依赖 BM25 等检索器的初始质量。