来源:arXiv
作者:Kaiwen Wei、Rui Shan、 Dongsheng Zou等
单位:重庆大学、中国科学院自动化研究所
发表时间:2025年08月
一、论文介绍
背景:当前的LLM普遍采用单一线性推理链并结合非结构化检索,易造成错误累积且难以利用领域知识的结构化关联,限制了其在医疗问答等复杂场景的有效性。
核心: 基于这一背景,论文提出 MIRAGE 框架,创新性地采用并行多链推理与结构化图谱检索相结合的策略,通过跨链验证解决矛盾,显著提升了医疗问答的准确性与推理过程可追溯性。
二、问答策略比较
这张图对比了四种不同的医疗问答推理模式。它直观地展示了现有方法的缺陷:静态RAG缺乏推理能力,智能体RAG(如Search-o1)依赖单一线性链容易出错,思维树缺乏验证机制。相比之下,MIRAGE 创新性地结合了“多链并行推理”与“知识图谱检索”,并通过跨链验证解决矛盾,展示了其在结构化和容错性上的优势。
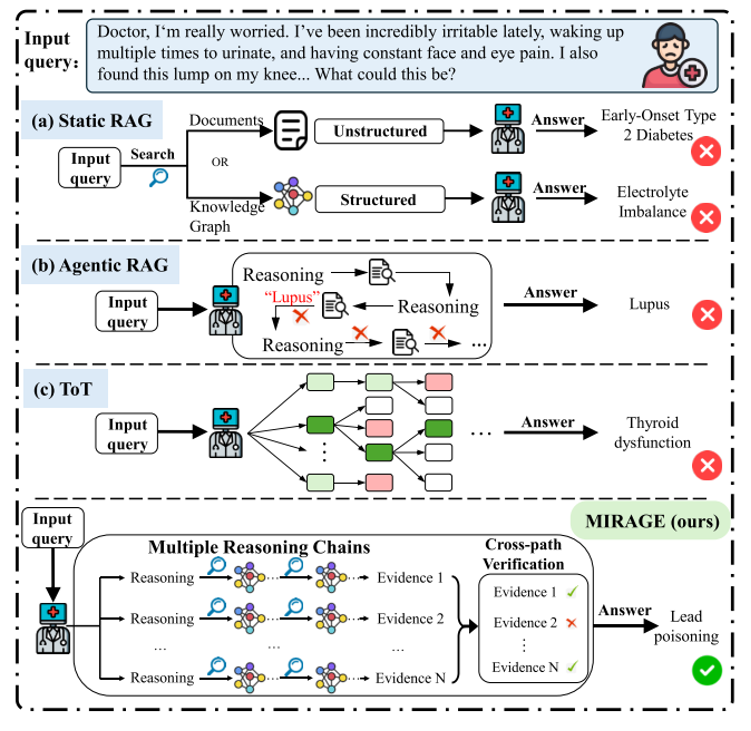
(a)静态RAG在没有显式推理的情况下检索文档或知识图条目;
(b) 代理RAG方法(如Search-o1)将检索与线性推理相结合;
(c)TOT通过采样来探索多个推理链;
(d)提出的MIRAGE通过跨并行推理链执行基于图的检索来结合这些方法。
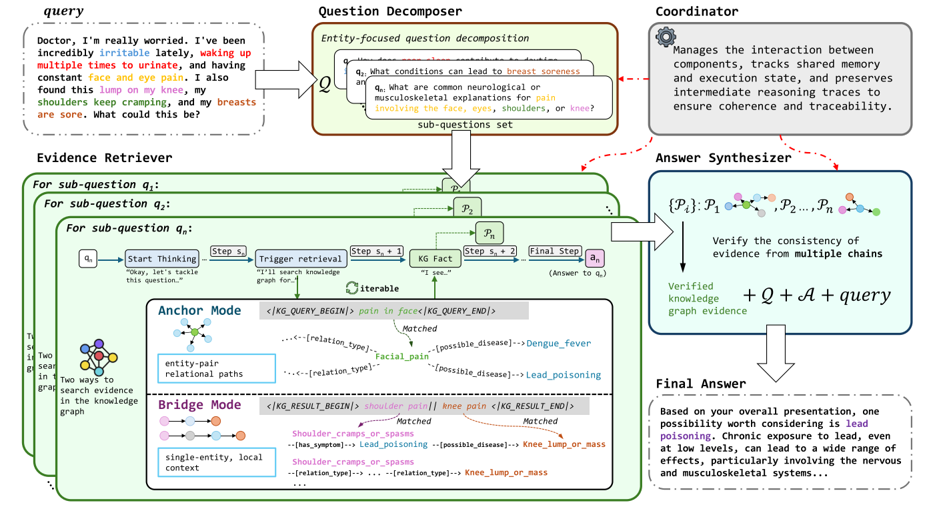
三、方法框架
问题分解器:将复杂医疗查询分解为子问题。证据检索器:对每个子问题独立检索,使用 锚点模式(查实体邻居)和 桥接模式(查实体间路径)在知识图谱中找证据。协调器:管理各组件间的通信和状态。答案合成器:进行 跨链验证,整合并验证各条推理链的证据,生成最终答案。
先回到“多链并行推理”
MIRAGE 把一个复杂问题拆成多个子问题,每个子问题走一条自己的推理链:
子问题 q1 → 推理链 P1 → 答案 a1(+一堆图谱证据)
子问题 q2 → 推理链 P2 → 答案 a2(+一堆图谱证据)
……
子问题 qn → 推理链 Pn → 答案 an(+一堆图谱证据)
到这一步,每条链都给出了自己的“诊断意见”,但还没决定谁是对的。
跨链验证:就是“多专家会诊 + 投票”
“跨链验证”发生在一个叫 答案合成器(Answer Synthesizer) 的组件里,它做的事情,很像一个“会诊会议”:
对所有答案做两两比较,找出互相排斥的诊断或相互矛盾的治疗建议,当出现冲突时,系统保留那个“证据链覆盖更广、关系更一致”的答案,这是一种“基于多数的验证策略”。
先看看各条链的答案有没有冲突
比如:
链 1 说:可能是“系统性红斑狼疮”
链 2 说:可能是“铅中毒”
链 3 说:可能是“甲状腺功能亢进”
这就是“互相排斥的诊断”,不能同时都成立,必须选一个。
再看每条链背后的证据够不够“硬”
系统会看:
这条链在知识图谱里找到的关系多不多?
有多少条独立路径都指向同一个结论?
这些关系是不是都紧扣原始问题?
证据链更长、关系更密、能互相佐证的链,就会被认为更可信。
按“少数服从多数 + 证据强度”来投票
论文里用的是“基于多数的验证策略”:
如果好几条链都指向同一个诊断,那这个诊断更可能是对的;
如果某条链的结论和大多数链冲突,而且它自己的证据又很单薄,就会被“压下去”。
用一个例子“跨链验证”
病人有一堆症状:易怒、夜尿多、面眼痛、膝部肿块、肩部痉挛、乳腺胀痛等。
在 MIRAGE 里:
链 A:从“情绪易怒 + 夜尿多”出发,查到可能是甲状腺问题或电解质紊乱;
链 B:从“肩部痉挛 + 膝部肿块”出发,查到可能是铅中毒(肩痉挛 → 铅中毒 ← 膝肿块);
链 C:从“面眼痛”出发,查到可能是三叉神经痛或某些风湿病。
这时候:
链 A、B、C 各说各的;
到了“跨链验证”这一步,系统发现:
链 B 的证据能同时解释“肩部痉挛、膝部肿块、夜尿、情绪问题”等多个症状;
链 A 和链 C 只能解释一小部分症状。
于是系统就会:
把“铅中毒”这个结论保留下来,
把那些解释力不强、和整体证据冲突的结论压下去。
这就是“跨链验证”在纠错——即使某一条链一开始想歪了,其他链也能把它拉回来。
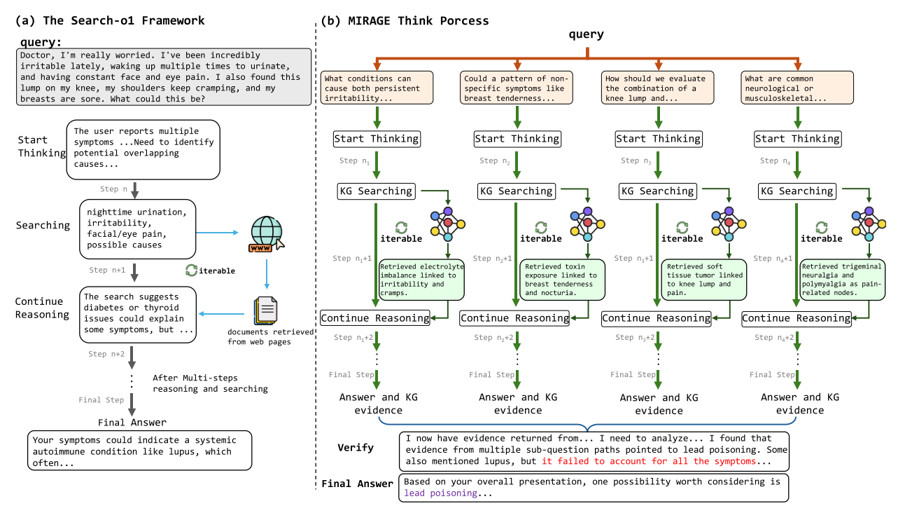
四、案例研究对比
1.左侧:Search – o1 Framework(传统单链推理)
流程:用户输入复杂症状(如尿频、易怒、关节痛等),模型尝试识别重叠病因。采用单链线性推理:先分解症状,通过网页搜索获取文档,经多步推理后给出答案(如“系统性红斑狼疮”)。
局限:依赖无结构化的网页信息,易导致信息过载或推理方向偏差,难以精准匹配复杂症状的深层关联。
右侧:MIRAGE Think Process(并行多链 + 图检索推理)
针对同一症状,MIRAGE通过“分解 – 并行 – 验证”的创新流程实现更精准推理:
问题分解:将复杂症状拆解为4个聚焦的子问题(如“持续性易怒的病因”“乳房胀痛模式”“膝关节肿块评估”“神经/肌肉骨骼解释”),每个子问题独立启动推理链。
多链并行 + 知识图谱检索:每条推理链通过知识图谱(KG)检索获取结构化证据(如电解质失衡、毒素暴露、软组织肿瘤、三叉神经痛等),替代无结构的网页搜索,确保证据的精准性与可追溯性。
跨链验证与整合:最后整合多链证据并验证一致性,最终锁定“铅中毒”这一更精准结论(而非单链可能产生的模糊答案)。
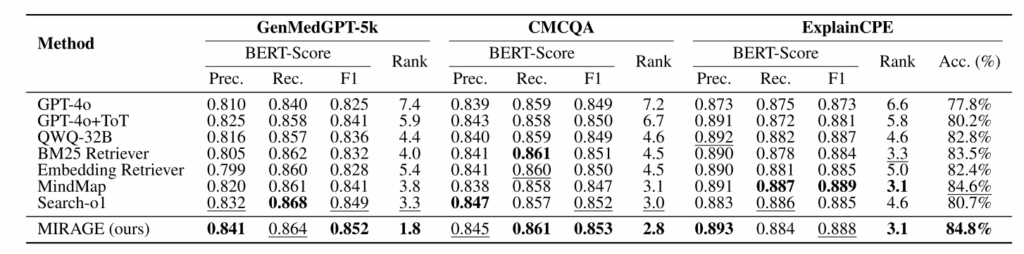
五、实验方法
主实验性能对比:展示了在三个医疗问答基准上的核心结果。MIRAGE 在所有数据集上均取得了最佳性能,例如在 GenMedGPT-5k 上排名最低(越好),在 ExplainCPE 上准确率达到 84.8%,全面超越了 GPT-4o 和现有的检索增强基线,证明了其有效性。
为了验证框架的通用性,使用了 DeepSeek-R1-32B 作为骨干模型进行测试。结果表明,更换底层模型后,MIRAGE 依然显著优于其他对比方法,证明了该框架具有良好的模型适应性和鲁棒性,不依赖特定的模型结构。
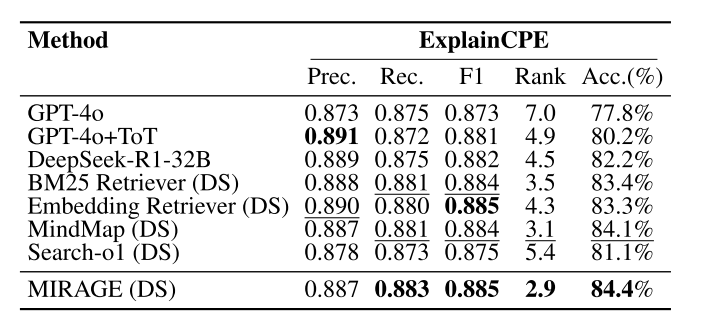
该图分析了两个关键参数的影响,揭示了最佳配置:子问题数量:不是越多越好。分解过多会引入噪声,导致性能先升后降。检索步数:增加检索步数收益递减但不会损害性能。表明系统具有“按需检索”能力,能在获得足够信息后自动停止,避免无效计算。
该图分析了两个关键参数的影响,揭示了最佳配置:子问题数量:不是越多越好。分解过多会引入噪声,导致性能先升后降。检索步数:增加检索步数收益递减但不会损害性能。表明系统具有“按需检索”能力,能在获得足够信息后自动停止,避免无效计算。
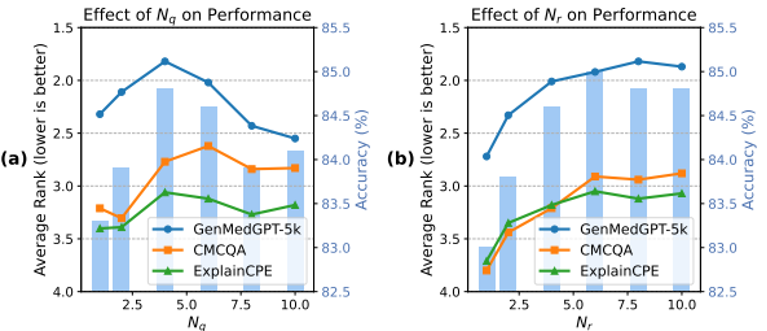
通过柱状图展示了人类专家对不同模型答案的偏好。结果显示,MIRAGE 在对比中获得了最高的“胜出”比例(绿色部分),且“失败”比例极低。这证明了 MIRAGE 不仅在自动指标上领先,在实际人类评估中也因为推理清晰、准确而更受青睐。
通过移除关键组件(分解器或验证器)来测试其对性能的贡献。结果显示,移除任一组件后,模型的“胜出率”均显著下降。这有力证明了 “问题分解”和“跨链验证”是 MIRAGE 提升推理准确性的关键创新点,缺一不可。

六、论文总结
论文提出了一种面向医疗问答的测试时可扩展推理框架MIRAGE:
(1) 并行多链推理范式:突破传统线性推理链易累积错误的局限,将复杂查询分解为实体关联的子问题并行推理,通过跨链验证机制实现误差纠正与结果整合;
(2) 结构化图谱自适应检索:摒弃扁平文本检索方式,设计锚点模式与桥接模式在知识图谱中进行邻居扩展与多跳遍历,动态捕获实体间的结构化语义证据;
(3) 跨链验证与一致性生成:引入答案合成器对多链推理结果进行一致性与矛盾检测,基于验证后的证据链生成最终答案,显著提升推理的可追溯性与临床准确性。
启发:
技术创新——逻辑思维推理框架:借鉴 MIRAGE 的跨链验证逻辑,在融合阶段前增加独立仲裁步骤:对比免疫链与经络链的关键节点证据权重,优先保留证据覆盖度高的一方,从而切断误差传播,实现从单纯的“证据驱动融合”向更具鲁棒性的“验证后融合”升级。
技术目标——跨域知识结构对比:参考 MIRAGE 的桥接检索模式,将证据检索逻辑从孤立的逐边匹配升级为主动探索“免疫因子→中介节点→经络证型”的跨域因果路径。
场景功能——食养通:引入 MIRAGE 的可解释性理念,在最终调理建议中附带证据溯源。例如:“建议食用红枣,因其富含铁元素改善贫血(免疫依据),且归脾经补气养血(经络依据),支持证据 ID:XXX”。