作者:Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, Jason Weston (Meta AI)
单位:国防科技大学
来源:ACL 2024 Findings
时间:2024.08
幻觉定义: LLM 生成看似合理但事实错误的信息
幻觉特点:
低频知识(长尾事实)更容易产生幻觉
长文本生成比短回答更容易幻觉
幻觉内容在表面上极具迷惑性,用户难以自行判断
现有方法不足:
Chain-of-Thought (CoT) 促进推理但不检查事实,甚至可能增加幻觉
检索增强 (RAG) 需要外部知识库,成本高
指令微调 (Instruction Tuning) 未必减少幻觉,可能产生更多错误输出
核心挑战: LLM 在一次性生成(one-pass generation)中产生了错误,但它自己能否发现并修正这些错误?
关键假设:
LLM 回答短问题比生成长文本更准确(这是CoVe的理论基础)
即:将”验证一段话是否正确”拆解为多个”回答具体小问题”,可以提高准确率
研究目标: 设计一种无需外部工具、无需额外训练的自验证方法,仅通过提示策略让模型自我纠错
关键公式化表达:短问题准确率 > 长文本事实密度 → 拆解验证 > 一次性生成
解决办法- CoVe 方法 总览
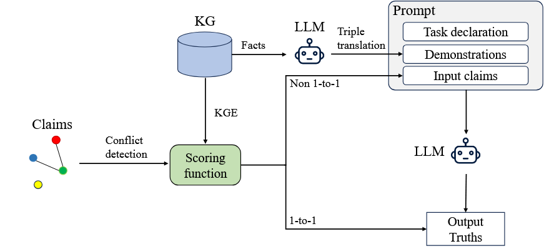
提出了一种结合冲突检测和大语言模型(LLM)的新框架,主要流程如下:
知识图谱嵌入(KGE):使用TransE等技术对现有KG进行嵌入学习,并定义评分函数来衡量三元组的“困惑度”(Perplexity,即错误可能性)。
关系分类:将KG中的关系和属性分为两类:
1-to-1 关系:一个头实体只对应一个尾实体(如“位于”、“出生日期”)。
Non-1-to-1 关系:一个头实体可对应多个尾实体(如“学生”、“作者”)。
分阶段解决策略:
针对 1-to-1 关系:直接利用评分函数,选择困惑度最低(最可信)的候选项
作为真理。
针对 Non-1-to-1 关系:
首先用评分函数过滤掉明显错误的候选项(困惑度高于阈值)。
对于剩余的难例,利用LLM进行最终判断。
LLM 提示工程(Prompt Engineering):设计了包含三个部分的提示模板:
任务声明:明确告诉LLM任务是冲突消解。
演示(Demonstrations):从KG中抽取相关三元组,通过“三元组翻译”转化为自然语言描述,作为上下文提供给LLM,增强其对实体的理解。
输入候选项:待判断的外部三元组列表。
Generate Baseline: 给定查询,LLM 正常生成初始回答(即 baseline)
Plan Verifications: 基于查询+初始回答,LLM 自动生成一系列验证问题(非模板化,LLM自由生成)
Execute Verifications: 独立回答每个验证问题(关键:不让模型看到初始回答,避免复制同样的错误)
Generate Final: 综合验证结果与初始回答,生成修正后的最终回答
实验任务与评估指标
| 任务 | 数据集 | 评估指标 | 任务特点 |
| 列表型问题 | Wikidata API (56题) | Precision (micro) | 答案是实体列表,判断幻觉实体数 |
| 列表型问题 | Wiki-Category (55题) | Precision (micro) | 类似Wikidata,但实体更复杂 |
| 多答案QA | MultiSpanQA (418题) | F1 Score | 闭卷设置,需要多个独立答案 |
| 长文本生成 | 人物传记 (任选人物) | FACTSCORE | 检测长文本中每个事实声明的准确性 |
基线模型: Llama 65B(few-shot)
对比方法: Zero-Shot, Few-Shot, CoT, Instruction-Tuned (Llama 2), InstructGPT, ChatGPT, PerplexityAI
实验结果
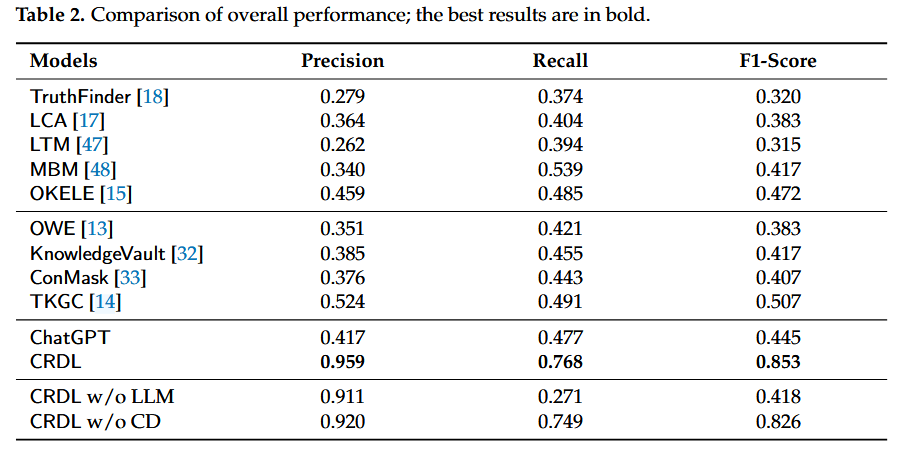
核心内容总结
1.提出“先检测,后解决”(Detect-Then-Resolve) 的差异化处理策略,使用精细化冲突感知,利用LLM作为外部知识增强器,结构化提示增强。
2.提出基于关系类型的自适应冲突检测机制。首次显式地在冲突消解框架中引入冲突检测步骤,并根据关系类型(1-to-1 vs Non-1-to-1)动态调整解决策略。
3.提出融合LLM的混合过滤架构。构建了一个级联过滤系统。对于简单情况使用轻量级的嵌入评分,对于复杂情况(涉及未见实体或模糊关系)调用LLM进行深度推理。
4.设计面向冲突消解的“三元组翻译”提示策略。设计了独特的Prompt构造方法,特别是“三元组翻译”(Triple Translation)环节。它不是直接将三元组扔给LLM,而是先从KG中采样相关事实,让LLM(或预处理模块)将其生成一段自然的实体描述文本,作为Few-shot演示注入Prompt。