来源: 2025, IEEE Access
作者: JINLIANG LIANG
单位: 广州南方学院
一、论文主要工作
现有的图像分割方法往往面临着高精度和计算效率的取舍问题。在这篇论文中,作者提出了一种新的图像分割方法来解决这些挑战。
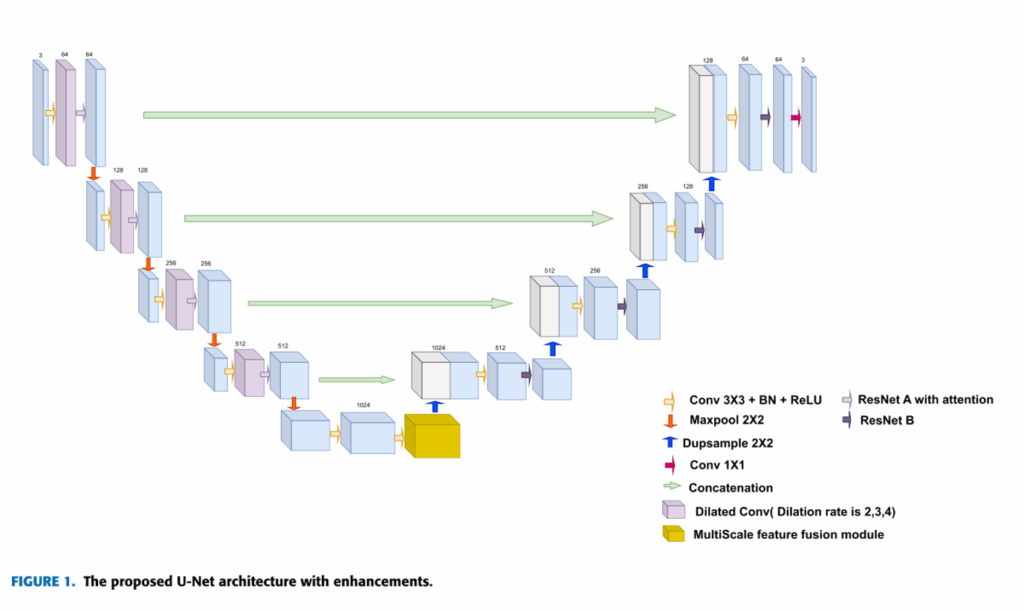
该方法基于集成多种先进技术的复杂U-Net深度学习结构,通过引入残差连接来缓解梯度消失问题,从而提高训练过程的稳定性和收敛速度。通过引入膨胀卷积来扩展网络的接受范围,使模型能够捕获更多的上下文信息。此外,还集成了注意力机制,从而实现更精确的分割。
该模型采用多尺度特征融合策略,将网络不同层次的特征组合在一起,丰富了特征表示,提高了模型处理不同大小对象的能力。此外,作者还设计了一种新的损失函数,它结合了传统的交叉熵损失和结构相似指数(SSIM)损失。交叉熵损失保证了准确的像素分类,而SSIM损失保持了分割图像的结构完整性和一致性。
二、模型
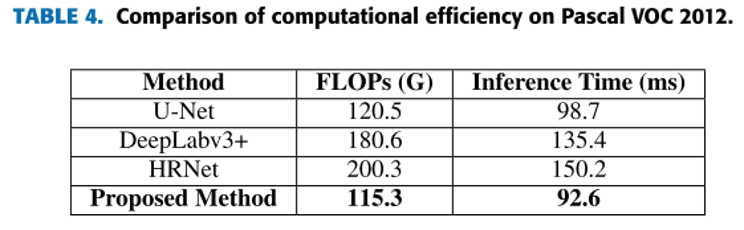
三、实验结果
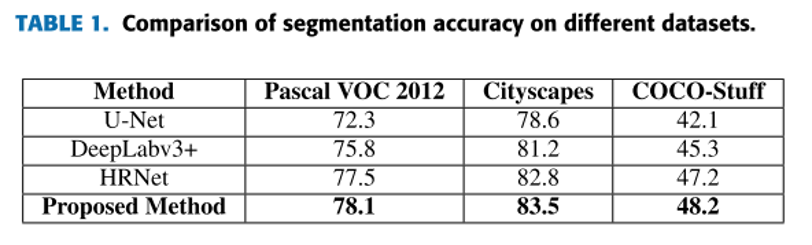
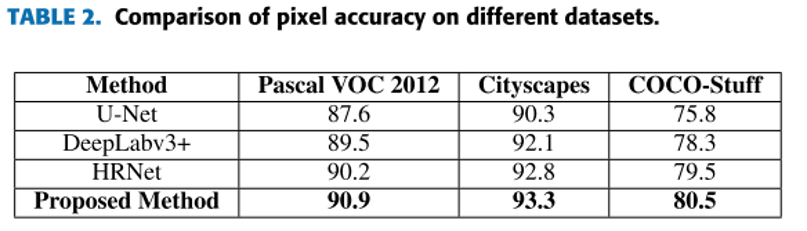
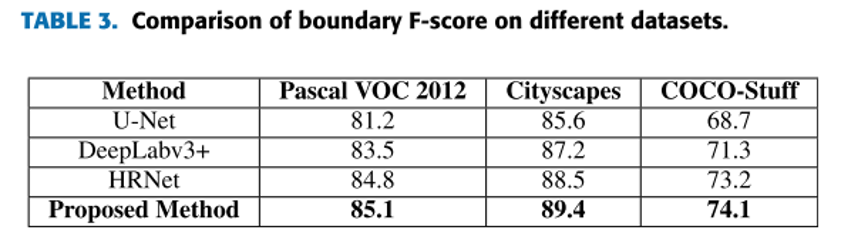
四、总结
课题综合对齐思考:
技术创新—数据拓扑标签计算:这篇研究贡献点在于改进U-Net网络,提高分割的精度和效率,并不存在数据托盘标签计算。
技术目标—跨域知识结构对齐:这篇研究并不包含明显的跨域知识结构对齐。
场景功能—食养通:可以用于食物图片的分割。