来源:arXiv
作者:Jinyuan Fang、 Zaiqiao Meng、 Zaiqiao Meng等
单位:格拉斯哥大学
发表时间:2024年06月
一、论文介绍
背景:检索增强生成(RAG)在问答任务中表现优异,但检索器的不完美常引入无关信息,尤其多跳问题需多步推理时,现有方法(如IRCoT)易因幻觉或冗余信息降低性能。
核心: 基于这一背景,论文提出TRACE框架,通过知识图生成器将文档转为知识三元组,再以自回归方式构建逻辑连贯的推理链,精准整合支持证据,提升RAG的多跳推理能力。
二、论文核心思想
TRACE 做了一个中间层的转化。三个部分
KG Generation(变结构): 先把乱糟糟的文档变成结构化的知识图谱(三元组)。
Reasoning Chain(找路径): 在图里一步步“走”出一条推理链。
Answer(做减法): 最后只把这条“精华链”给大模型看,而不是把所有文档都给它看
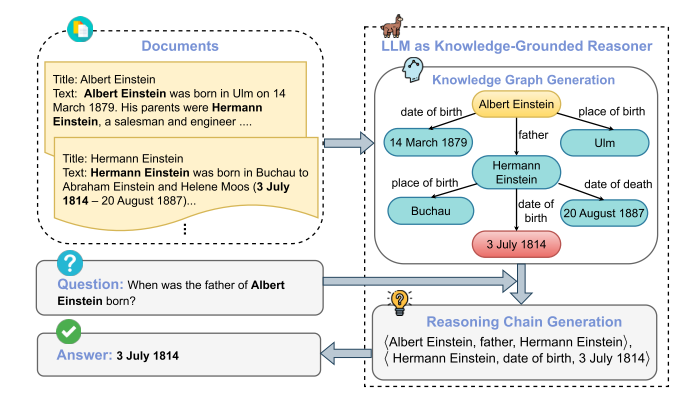
三、方法框架
三个模块:KG Generator(知识图生成器)、Autoregressive Reasoning Chain Constructor(自回归推理链构造器)、Answer Generation(答案生成器)
模块一:KG Generator 的细节
输入:检索到的一组非结构化文档。
机制:利用 In-context Learning 提示一个 LLM,让其从每个文档中提取知识三元组(head entity,relation,tail entity)。
独立处理:为了避免 LLM 处理长文本时的“lost-in-the-middle”(迷失在中间)问题,该方法独立地为每个文档生成三元组,并通过共享实体连接不同文档。
标题实体化:针对维基百科文档,该方法将文档的标题视为一个实体,并让模型推断正文中实体与标题实体之间的关系。
离线计算:该方式允许离线预先计算所有文档的 KG 三元组,提高效率。

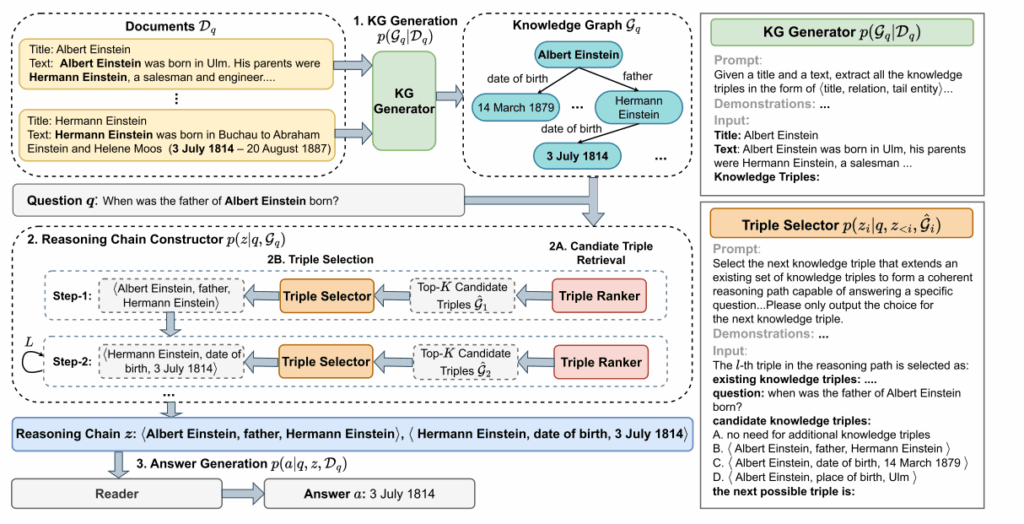
模块二:Reasoning Chain Constructor
负责从知识图(G_q)中构建推理链(z),即一系列逻辑上连接的知识三元组,以识别并整合用于回答问题的支持性证据。
Triple Ranker(三元组排序器):
作用:在知识图的所有三元组中,筛选出与当前问题及已选路径最相关的候选三元组。
机制:使用一个 bi-encoder 模型(如 E5-Mistral)。它将“问题 + 已选三元组”作为查询,与 KG 中的所有三元组分别计算向量相似度(内积),并选出相关性最高的 Top-K 个三元组作为候选集(G_i )。
Triple Selector(三元组选择器):
作用:从候选集中选出一个最合适的三元组,接在已有的推理链后面,形成逻辑连贯的路径。
机制:使用 In-context Learning 提示一个 LLM(如 LLaMA3)。该任务被构建为一个多选题形式,模型只需输出代表所选选项的单个 Token(如 “B”)。
分布定义:利用 LLM 输出的选项 Token 的 logits 来定义每个三元组的分布概率,并使用 beam search 生成多条推理链。
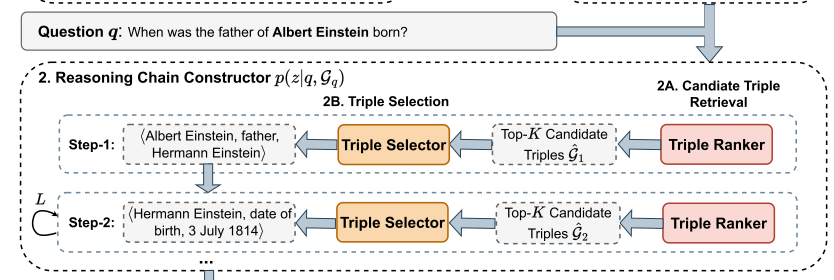
以及prompt:Triple Selector(三元组选择器)
作用:通过自回归方式逐步构建推理链,确保每一步选择的三元组与问题、已有三元组逻辑一致,最终整合支持证据回答问题。
功能:在推理链构建过程中,从候选三元组中选择下一个三元组,以扩展已有三元组并形成能回答问题的连贯推理路径。
示例:输入“已有三元组”“问题(如‘when was the father of Albert Einstein born?’)”和候选三元组(选项A – D),输出选择(如选项B或D对应的三元组)。

模块三:Answer Generation
TRACE-Triple:直接将构造好的推理链作为上下文输入到 Reader 中:推理链天然呈现了理想的逻辑顺序,因此直接拼接即可
TRACE-Doc:利用推理链中的三元组回溯并识别出原始文档中真正有用的文档子集,然后将这些文档作为上下文。采用多数投票策略。每个推理链中的三元组为其来源文档投一票,根据得票数对文档进行排序,过滤掉得票为 0 的无关文档。

四、实验
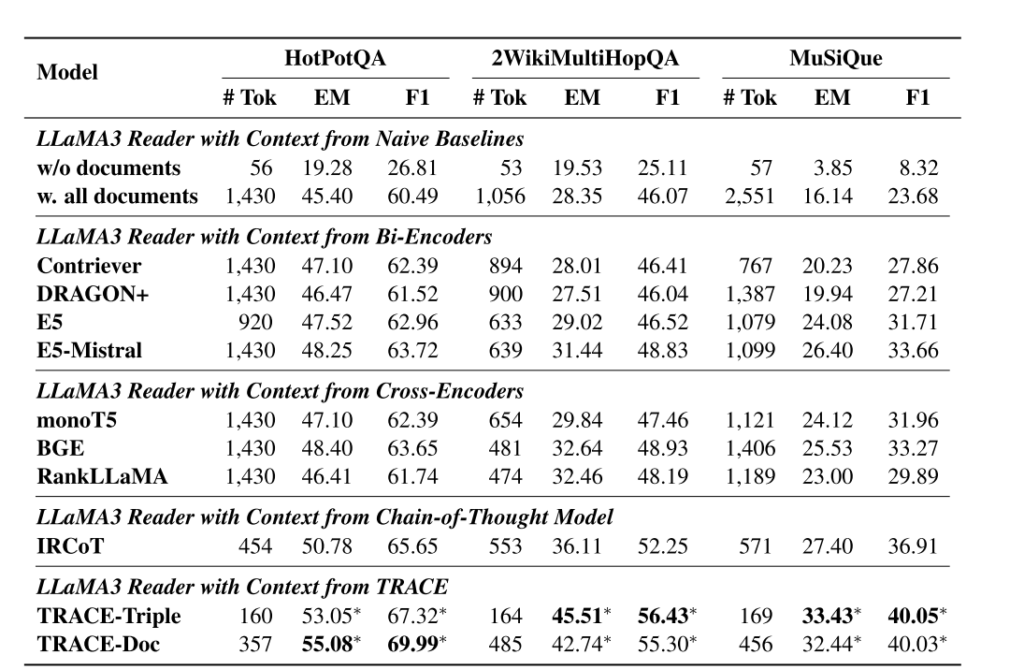
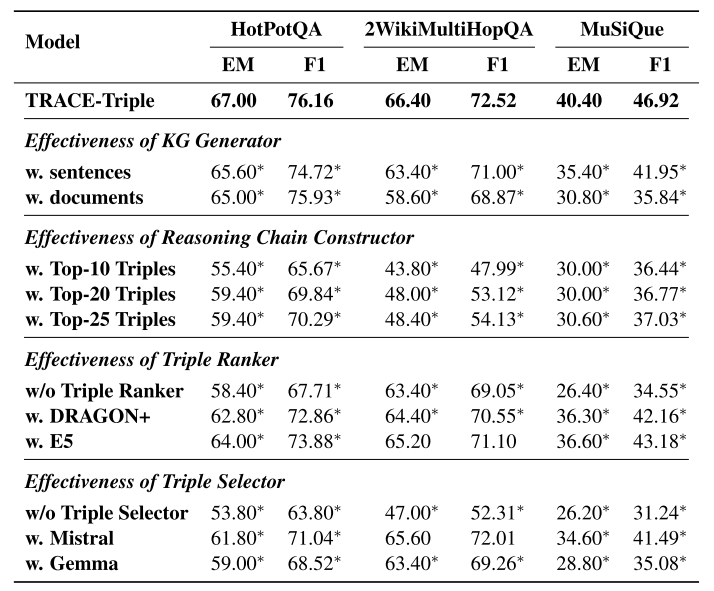
TRACE和基线的QA性能对比
实验结果表明,相比基线(如w. all documents),TRACE-Triple平均EM提升14.03%,TRACE-Doc提升13.46%,证明框架能有效提升多跳QA性能。
TRACE显著优于IRCoT(CoT方法的代表),说明“知识三元组+推理链”比“自由生成CoT”更可靠(减少幻觉)。
消融实验
验证KG Generator的必要性:说明知识三元组的细粒度表达能减少无关信息干扰。
验证Reasoning Chain Constructor的必要性:证明自回归构建推理链(逐步依赖已有三元组)能更精准整合证据。
验证Triple Ranker/Triple Selector的必要性:去掉任一组件性能下降,说明“排序+选择”的双阶段设计是推理链质量的关键。
Case Study
具体问题的推理链示例(如“父亲出生日期”问题,展示⟨Albert Einstein, father, Hermann Einstein⟩→⟨Hermann Einstein, date of birth, 3 July 1814⟩的推理过程。
从问题出发,先找“父亲关系”,再找“父亲出生日期”,直观解释“推理链”的构建逻辑。
对比“文档全文”与“推理链”的差异:推理链更简洁(token数少),但能准确回答问题,说明“精准证据”比“全文”更有效。

五、论文总结和对齐思考
论文提出了一种面向RAG的证据驱动推理链构建框架TRACE,通过从文献中动态构建任务相关的局部知识图,并以显式推理链约束生成过程,从而提升多跳推理的一致性与可验证性。
(1) 证据级推理链建模:将推理链作为一等结构对象,从检索文献中抽取实体–关系事实并组织为有序推理链,替代传统 RAG 的平面证据拼接;
(2) 任务驱动的局部知识图:无需全局本体或预定义知识图,仅基于当前任务与检索结果动态构建轻量级图结构,提升适配性与可扩展性;
(3) 链式证据约束生成:以推理链而非原始文本作为生成条件,使模型沿证据支持的逻辑路径推理,降低幻觉并增强推理一致性。
对齐思考
技术创新——逻辑思维推理框架:当前实验尚不能区分性能提升源于“链式结构”还是“因果机制”。受 TRACE 启发,可引入一个对照基线:仅从文献抽取无因果方向的事实/机制链(无因果门控、无反事实、无一致性验证)。若 MERICA 显著优于该基线,则证明其优势来自因果约束,而非单纯使用链结构。
技术目标——跨域知识结构对比:TRACE 明确区分了“证据如何组织”与“推理是否因果有效”;在此基础上,MERICA 将任务从构建可读的证据链,推进到生成可干预、可反事实验证的因果解释链,实现了从中西医知识拼接到跨域因果协同的升级。
场景功能——食养通:实际应用中以“因果链 + 证据溯源”的形式呈现推荐逻辑,使用户理解其个性化健康与食养解释。