作者: Satyananda Kashyap, Sola Shirai, Nandana Mihindukulasooriya, Horst Samulowitz
单位: IBM Research
来源: VLDB 2025 Workshop
时间: 2025.09
一、研究背景

二、核心贡献

三、方法

四、实验
1.实验准备

2.实验结果——生成质量
(1)低幻觉,证明了两阶段方法非常有效
(2)连贯性低,模型不遗漏表格中任意一个数,牺牲了文学上的流畅度

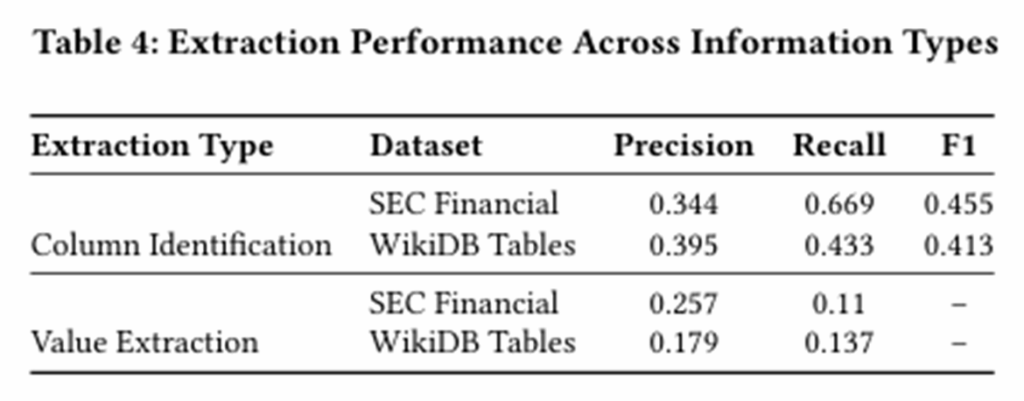
3.实验结果——客观精准度
F1分数高,表明生成文本和原始表格匹配度高,从而证明了合成的基准数据集高度可靠
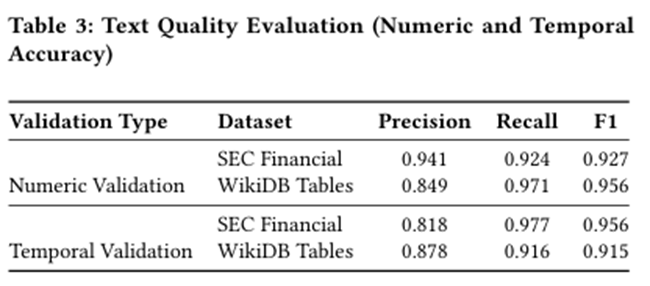
4.实验结果——提取性能
(1)列名识别的F1分数低,即模型很难准确识别出这应该填入表格哪一列
(2)数值提取的效果也极差
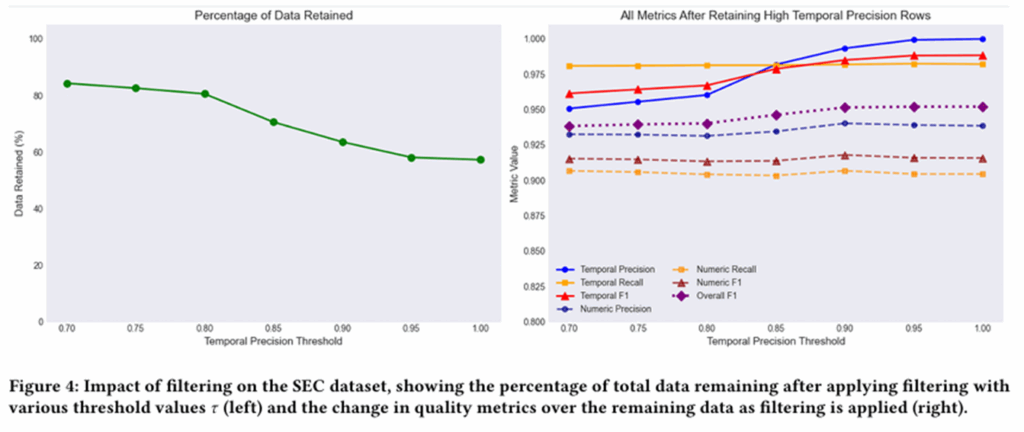
5.实验结果——质量过滤
当阈值为0.9时,虽然舍弃了近50%的数据,但剩下的数据在其他指标上很完美
五、总结
1)本文提出了 StructText,一种可控的合成式表格生成文本基准,并配套设计了多维度评估体系,以系统衡量模型在结构理解、语义组合和事实一致性等方面的生成能力。
2)通过结合 LLM 裁判与数值/时间客观指标的多维度评估,我们构建并发布了包含 7.1 万个样本 的大规模基准集。
3)实验结果表明,现有模型在复杂表格结构理解、多属性语义组合和事实一致性方面仍存在明显不足,凸显了构建高质量评测基准对于推动表格生成文本研究的重要性。
六、对齐思考
1.1技术创新——数据拓扑标签计算: 先计划后执行的方法能确保LLM准确评估分析表格,以便生成具有高度逻辑性和可提取性的文本。
2.0技术目标——跨域知识结构对比:与其他文章关注点不同,其他文章主要是关注如何提高生成文本的流畅度,本文则是关注信息是否是否准确藏在叙述中。
3.0应用场景——可以利用该技术构建企业自己的基准,并检测内部的AI提取算法准不准。