作者:Nelson F. Liu, Kevin Lin, John Hewitt
来源:Transactions of the Association for Computational Linguistics (TACL)
单位:Stanford University;University of California, Berkeley
发表日期:2023.8
一、论文介绍
背景动机
1.近年来大语言模型(LLM)在长文本处理能力上不断突破,支持从数千到数万 token 的输入,被广泛应用于多文档问答、检索增强生成(RAG)、长文档理解等场景,为复杂知识获取任务提供了新的技术基础。
2.现有研究与实践通常默认“更长上下文 = 更强能力”,但对于 LLM 是否能够稳定、有效地利用整个长上下文中的关键信息,尤其是在跨文档、多干扰信息的设置下,缺乏系统、可控的实证分析。
3.在真实应用中,关键信息往往位于长上下文的中间位置而非开头或结尾,但现有评测多忽略信息位置因素,导致我们难以判断 LLM 在长上下文中是否存在位置偏置(如首因效应、近因效应),从而限制了对长上下文模型能力边界与改进方向的理解。
研究目标
提出可控评测框架,系统分析大语言模型在长上下文中对关键信息的利用能力及其随上下文长度和信息位置变化的性能特征。
通过控制关键信息位置与上下文规模,评估模型在多文档问答与键值检索任务中的位置敏感性与鲁棒性,揭示首因与近因效应。
从模型架构与上下文组织方式等角度,分析影响长上下文建模能力的关键因素,为评测标准与模型改进提供依据。
核心内容
当关键信息位于上下文开头或结尾时模型表现最好
但位于中间时性能显著下降,形成明显的 U 型曲线
说明模型存在严重的位置偏置。
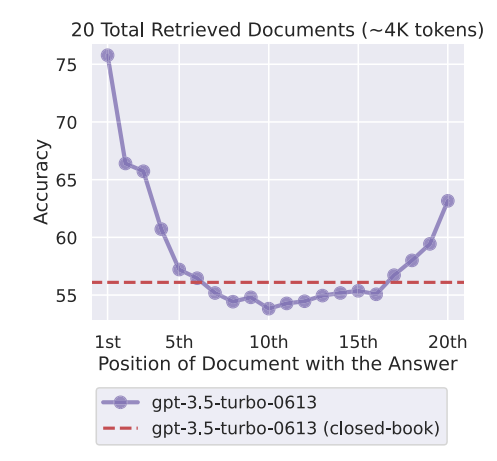



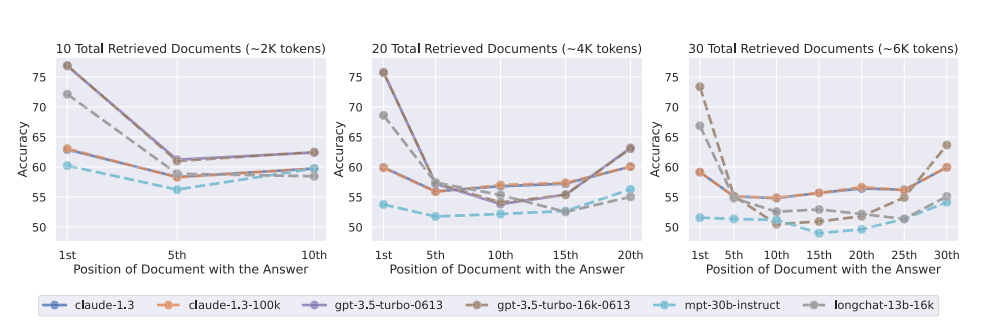
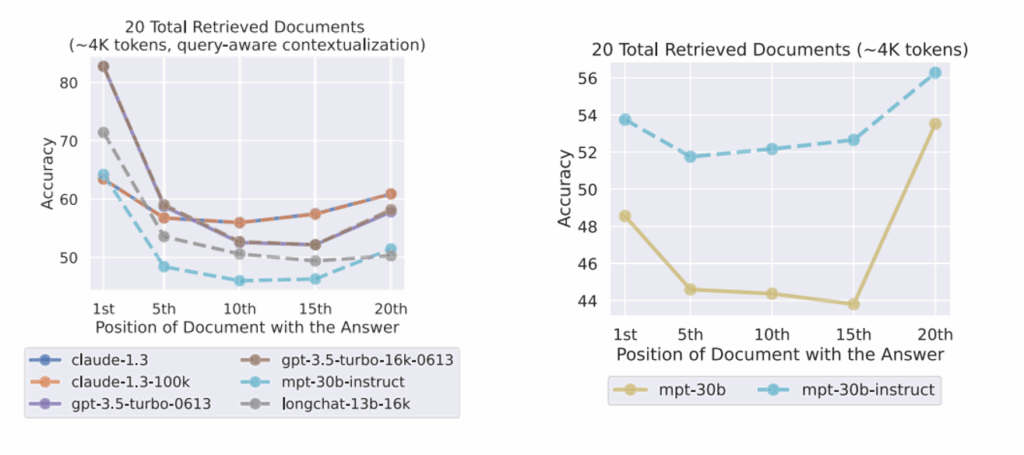
在 10 / 20 / 30 篇检索文档(约 2K / 4K / 6K tokens)条件下,不同语言模型在多文档问答任务中的表现随关键信息位置变化的情况。可以观察到,无论上下文长度如何变化,模型在关键信息位于输入上下文开头或结尾时准确率最高,而当关键信息位于中间位置时性能显著下降,呈现出稳定的 U 型性能曲线。
三、实验评估
四、总结思考
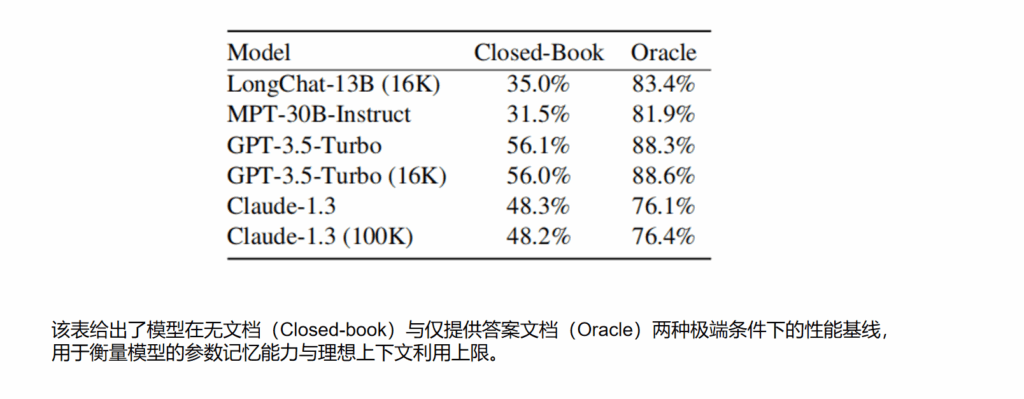
现有大语言模型虽然支持长上下文输入,但在实际推理过程中难以鲁棒地利用整个上下文信息,尤其对位于长上下文中间位置的关键信息敏感性较低,表现出明显的首因效应与近因效应,限制了其在多文档理解与检索增强任务中的有效性。
通过构建可控的长上下文评测框架,在多文档问答与键值检索任务中系统地操纵关键信息的位置与上下文长度,揭示了语言模型普遍存在的 U 型性能曲线,并从模型架构、上下文组织方式及指令微调等角度分析了影响长上下文利用能力的关键因素。
大量实验结果表明,扩展上下文长度并不能保证模型更好地使用上下文信息,即使在简单的检索任务中,中间信息仍易被忽略。该结论为长上下文语言模型的评测设计、RAG 系统的文档排序策略以及未来模型结构改进提供了重要启示。
启发思考
1.1技术创新-逻辑思维推理框架:简单的文本拼接并不能保证关键信息被有效建模。在抽取任务中,应将“拼接顺序”视为推理逻辑的一部分,通过前置关键信息、分段提示或结构化标记,引导模型优先关注高价值内容,从而降低位置偏置对抽取结果的负面影响。
2.1技术目标-专业手册公共服务:让模型能够在冗长、复杂的专业手册中,快速找到并准确抽取“真正有用的信息”,避免无关内容干扰判断。
3.1场景功能-食养通:在“食养通”等应用场景中,成分、限量、适用人群等关键信息通常跨段落、跨文档出现。借鉴该文章发现,在实验设计中需要避免无序拼接全文文本,而应围绕核心实体构建位置友好的上下文组织方式,从而提升模型对关键约束关系的抽取效果,增强系统在健康饮食场景下的可解释性与实用价值。