作者:Thomas Palmeira Ferraz, Kartik Mehta, Yu-Hsiang Lin等
单位:亚马逊通用人工智能基础研究团队、法国巴黎电信学院等
来源:EMNLP
时间:2024.10
研究背景与动机
大型语言模型(LLMs)在遵循指令方面取得了显著进展,但当指令包含多个约束条件时(例如,“写一条推文,语气要幽默,不能使用标签,并且要推广AI”),其表现往往不尽如人意。现有研究和评估基准存在两个主要问题:
数据不真实:大多数评估基准(如IFEval)依赖于合成数据(synthetic data)。这些数据虽然便于自动化评估,但可能无法准确捕捉真实世界用户请求的复杂性和细微差别,甚至可能人为地制造出不切实际的难题。
评估成本高:评估真实世界的开放式指令非常困难,通常需要昂贵且耗时的人工标注。
因此,该领域缺乏一个能有效衡量LLM在处理真实、多约束用户请求时能力的基准,也缺乏一种高效、低成本的评估方法。同时,开源模型与顶尖闭源模型(如GPT-4)之间在该任务上存在明显的性能差距。
研究问题
本文旨在解决以下三个核心问题:
评估问题:如何构建一个基于真实用户请求的、可靠的多约束指令遵循评估基准?
评估成本问题:能否用模型自身(LLM-as-a-Judge)来替代人工进行低成本、高效率的评估?
性能提升问题:如何设计一个通用的自修正框架,以提升(尤其是开源)LLM在多约束指令遵循任务上的表现,并缩小与顶尖闭源模型的差距?
为了解决上述问题,本文提出了三项主要贡献:
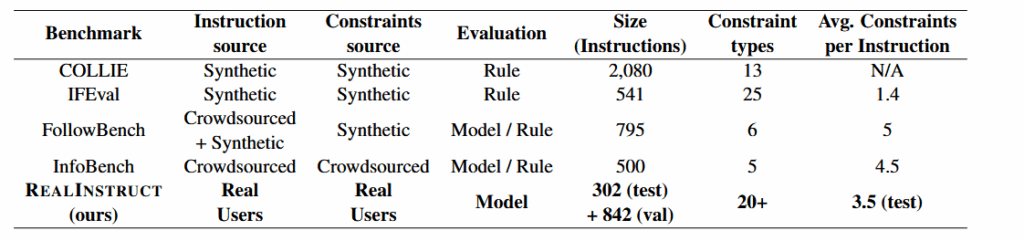
REALINSTRUCT 基准:这是第一个利用真实用户向AI助手提问的数据构建的多约束指令遵循评估基准。
LLM-as-a-Judge 评估协议:系统性地研究了使用开源和闭源LLM作为评估器来判断约束满足情况的有效性。
DECRIM 自修正流水线:一个新颖的、无需对约束类型做任何假设的自修正框架,用于增强LLM遵循多约束指令的能力。
解决办法-DECRIM 方法
DECRIM 是一个迭代式的自修正流水线,其核心思想是将复杂的多约束指令分解、批判并精炼。它包含四个关键步骤,循环执行直至所有约束被满足或达到最大迭代次数。
步骤一:初始响应 (Initial Response)
LLM直接根据用户的原始指令生成一个初步的回答。
步骤二:分解 (Decompose)
使用一个“分解器”(Decomposer)模型(可以是LLM本身或其他模型)将原始的、复杂的用户指令分解成一个清晰、细粒度的约束列表。

步骤三:批判 (Critique)
使用一个“批评家”(Critic)模型,根据上一步得到的约束列表,逐条检查初始响应是否满足了所有约束。
如果所有约束都满足,则将当前响应作为最终输出,流程结束。
如果有未满足的约束,批评家会以自然语言的形式提供具体的反馈,明确指出哪些约束未被满足。
步骤四:精炼 (Refine)
将批评家提供的具体反馈、原始用户指令以及上一轮的响应一起输入给底层的LLM。LLM根据这些信息生成一个改进后的新响应,目标是修正之前未满足的约束。
循环迭代:新生成的响应会再次进入“批判”步骤,接受新一轮的检查。这个“批判-精炼”的循环会持续进行,直到响应通过所有约束的检验,或者达到预设的最大迭代次数。

实验围绕三大贡献展开:
验证 LLM-as-a-Judge:
数据集:创建了EvalJudge数据集,包含近1000个经过专家人工验证的(指令,约束,响应)三元组。
模型:测试了GPT-4、GPT-4-Turbo、GPT-3.5-Turbo等闭源模型,以及Mistral、Vicuna、Zephyr等开源模型。
策略:比较了不同的提示策略(如整体评估 vs. 逐条评估,是否使用思维链CoT)和微调策略(用GPT-4-Turbo的推理过程弱监督训练Mistral)。
REALINSTRUCT 基准测试:
在REALINSTRUCT和流行的合成基准IFEval上,对多个开源和闭源模型进行了多约束指令遵循能力的基准测试。
使用经过验证的最佳评估器(GPT-4-Turbo + CoT)进行打分。
DECRIM 流水线评估:
主模型:以Mistral 7B v0.2作为底层LLM。
基线:与常规提示、“Make sure to follow all constraints”提示、以及Self-Refine等现有自修正方法进行比较。
消融研究:分别测试了不同强度的“分解器”(Self-Decomposer vs. Oracle Decomposer)和“批评家”(Self-Critic, Supervised Critic, GPT-4, Oracle Critic)对最终性能的影响。
质量评估:使用Prometheus-2评估精炼前后响应的整体质量,确保修正过程没有损害回答的流畅性和相关性。
核心内容总结:
1.提出REALINSTRUCT基准:首个基于真实用户交互的多约束指令遵循评估集,填补了合成数据与现实应用之间的鸿沟。
2.提出DECRIM框架:一个不依赖于约束先验知识的、基于细粒度反馈的迭代式自修正范式。其核心创新在于将复杂的全局优化问题,转化为一系列由批评家指导的、目标明确的局部修正任务。
3.对LLM-as-a-Judge的系统性分析:首次在多约束遵循任务上,全面比较了不同模型和策略作为评估器的效果,为社区提供了宝贵的实践指南。