作者:Mojtaba Heydari,Mehrez Souden,Bruno Conejo,Joshua Atkins
作者单位:University of Rochester(罗切斯特大学),Apple(苹果公司)
来源:arXiv
时间:2025年2月7日
背景
随着虚拟现实、增强现实、游戏、影视制作以及沉浸式交互系统的发展,对高真实感三维空间音频(3D Spatial Audio)的需求不断增长。相比传统的单声道或立体声音频,空间音频能够在方位、高度和距离等维度上准确呈现声源位置,从而显著增强沉浸体验 。近年来,基于扩散模型(Diffusion Models)的生成式音频方法取得了显著进展,如 AudioLDM、Stable Audio 等模型已能够根据文本生成高质量音频内容。然而,这些方法大多局限于单声道或立体声,缺乏对声源空间位置的精确建模能力,难以根据用户指令将声音准确放置在指定方向或空间位置。
主要贡献
本文提出了 ImmerseDiffusion,一种端到端的生成式空间音频扩散模型,其主要贡献包括:
- 首次提出面向三维空间音频的生成式扩散模型
作者提出了首个能够直接生成一阶 Ambisonics(FOA)格式空间音频的生成模型,实现对方位角、高度和距离等空间属性的建模 。 - 设计了双模式空间控制机制
模型支持两种生成方式:- 描述式(Descriptive)模式:通过包含空间与环境信息的自然语言文本控制音频生成;
- 参数式(Parametric)模式:结合非空间文本描述与显式数值化空间参数,实现精确、可控的空间音频生成,适用于游戏引擎和仿真系统等场景 。
- 提出针对空间音频生成的系统化评估指标
针对 FOA 空间音频生成,作者引入并改进了包括 Ambisonics FAD、空间 KL 散度、空间 CLAP 得分以及基于声强向量的空间定位误差指标,用于全面评估生成音频的质量与空间一致性 。
技术方法
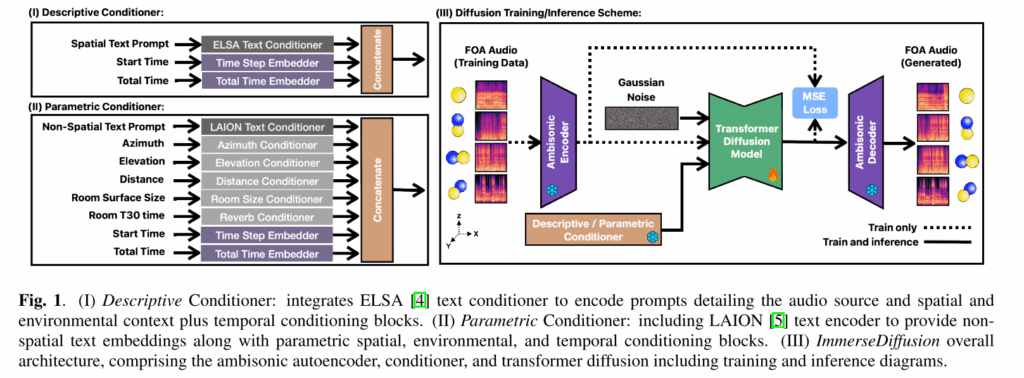
本文提出的 ImmerseDiffusion 是一个端到端的生成式空间音频系统,目标是在用户条件约束下生成 一阶 Ambisonics(FOA)四通道空间音频。整体方法由三部分组成:FOA 空间音频编码器(Codec)、条件控制模块(Conditioner)以及基于 Transformer 的潜空间扩散模型(Diffusion Transformer)。
1)空间音频表示:FOA(First-Order Ambisonics)
系统生成的空间音频采用 FOA 格式,包含 W、X、Y、Z 四个通道:W 为全向分量,X/Y/Z 为方向分量,分别表达前后、左右、上下方向信息。该表示能够通过渲染转换到多声道空间输出,是常用的沉浸式音频格式。
2)空间音频编码器:FOA Codec 将波形压缩到潜空间
由于 FOA 音频数据维度高、扩散迭代计算量大,作者先训练一个 空间音频自编码器(Ambisonic autoencoder / codec),将 FOA 波形映射到低维连续潜空间,再在潜空间进行扩散生成,以提升效率。
3)条件控制模块:描述式与参数式两种模式
为实现用户可控的空间音频生成,模型设计了两套条件输入方式,并在扩散网络中通过 cross-attention 等机制注入条件信息。在描述式模型中,使用 ELSA 空间文本编码器提取包含空间与环境语义的文本嵌入;在参数式模型中,采用 LAION CLAP 文本编码器处理非空间文本,并引入显式数值参数(方位角、高度、距离、房间大小、混响时间等)作为条件输入;同时,两种模型均引入时间条件(起始时间与总时长)以实现时间可控生成。
4)潜空间扩散模型:Diffusion Transformer 进行条件去噪生成
在潜在空间中,作者采用 Diffusion Transformer(DiT)结构作为扩散网络,结合自注意力、交叉注意力与门控 MLP 模块,实现多模态条件对音频生成过程的有效引导。
实验分析
数据集:作者使用了多套“合成空间化”的数据来训练 FOA codec 与两种 ImmerseDiffusion 模型,包括 Spatial FreeSound、Spatial AudioCaps、Spatial Clotho,并额外加入 Spatial LibriSpeech 与对应的 FOA 噪声数据以提升语音泛化能力;每条数据都包含空间化音频、原始字幕、空间/环境参数以及空间派生字幕。
评价指标
- Codec 重建质量:用 AuraLoss 计算原始/重建 FOA 的 STFT 距离与 MEL 距离。
- 生成音频质量/一致性:
- FAD:比较生成与真实音频嵌入分布差异。
- KL divergence:用预训练 ELSA 计算分布差异。
- CLAP score:用条件文本嵌入与生成音频嵌入的余弦相似度。

表 1 对比了不同压缩率的 FOA Codec 在 Spatial AudioCaps 数据集上的重建质量和空间精度。
当压缩率从 32X 提升至 128X 时,STFT Distance 和 Mel Distance 变化较小,说明即使在高压缩条件下,模型仍能较好地保留音频时频结构。
不同压缩率模型在方位角(L1 azimuth)、俯仰角(L1 elevation)和距离(L1 distance)上的误差基本保持在相近水平,表明 FOA 的空间线索在高压缩潜空间中并未明显丢失。
综上,在较高压缩比下进行潜空间扩散生成是可行的,FOA Codec 能够有效保留空间信息,为后续扩散模型提供了可靠的输入表示。

表 3 对比了 描述式(Descriptive) 与 参数式(Parametric) ImmerseDiffusion 模型在 Spatial AudioCaps 测试集上的生成质量与空间精度。
描述式模型的 FAD 显著低于参数式模型,说明其生成音频在整体分布上更接近真实数据。两种模型在 KL 和 CLAP 指标上表现接近,参数式模型在 KL 上略优,但在 CLAP 上略低。
参数式模型在方位角、俯仰角和整体空间角误差上明显优于描述式模型。两种模型在距离误差上的表现接近,说明距离估计仍受 FOA 强度向量估计误差的限制,尚未完全受益于参数化输入。
- 描述式模型:生成质量更高,适合影视、叙事等“语言驱动”的沉浸式内容创作;
- 参数式模型:空间定位更精确,更适合游戏引擎、虚拟仿真等需要精确空间控制的应用场景。
总结
本文的方法通过将一阶 Ambisonics(FOA)空间音频映射到潜空间,并结合基于 Transformer 的扩散模型,实现了在文本、空间、时间及环境条件约束下的三维空间音频生成。模型同时支持描述式与参数式两种控制方式,在灵活性与精确性之间取得了良好平衡。实验结果表明,所设计的 FOA Codec 在较高压缩率下仍能有效保留空间信息,为潜空间扩散生成提供了可靠基础;在生成阶段,描述式模型在整体音频质量与语义一致性方面表现更优,而参数式模型在空间定位精度上具有明显优势,验证了双模式设计在不同应用场景下的适用性。