来源:COLM 2025
单位:MBZUAI、UCLA、斯坦福大学
作者:Jianshu She, Zhuohao Li, Zhemin Huang, Qi Li, Peiran X,
Haonan Li, Qirong Ho
一、背景
思维链 ( CoT )推理技术被证明能大幅增强LLM的复杂任务解题能力,尤其在数学推理、代码生成等领域。然而,这类推理的效率问题极为突出:
- 推理token数量庞大:CoT生成了大量中间思维token,其中多数是语义冗余或低密度信息。
- 计算成本高昂:推理token数直接决定计算与存储成本。
- 部署延迟显著:例如OpenAI o1模型平均使用4万token,而GPT-4o平均仅4千。
因此,核心问题是:
如何在不牺牲推理质量的前提下,减少推理过程中无用的CoT冗余token?
二、贡献
- 提出了一种全新的推理范式 HAWKEYE,通过模型协作(model collaboration)实现高效推理。在该框架中,大模型负责生成简洁的推理指令,小模型在此基础上将其扩展为完整的自然语言响应。HAWKEYE 在保持响应质量的同时,显著降低了计算成本与经济成本。
- 首次对 CoT 冗余性进行了系统性研究,表明过量的推理 token 是在多种任务中普遍存在的现象。分析结果显示,通过一种有原则的压缩策略,可以移除相当大比例的推理 token,而不会对输出质量造成明显损害。
- 构建了一个高质量的 CoT 数据集,并利用强化学习对推理模型进行微调,以优化 CoT 的生成过程。该方法在基本保持模型性能的前提下,使 CoT 长度相较于原始大模型缩短超过 75%,且在评测数据集上的准确率仅下降约 4%。
三、方法
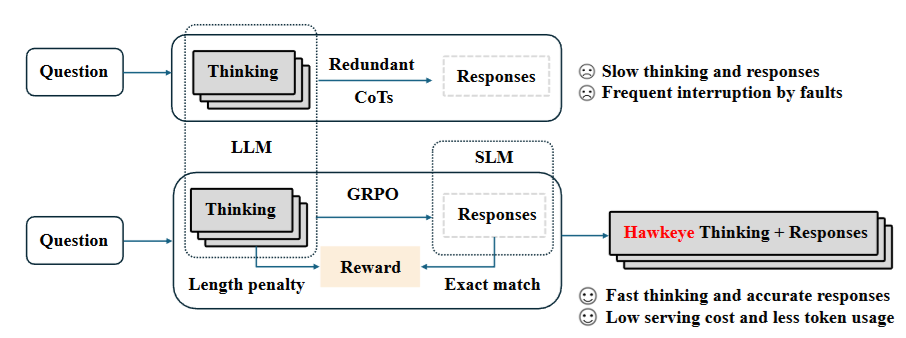
HAWKEYE 的整体设计同时覆盖后训练阶段(post-training)与推理阶段(inference),其核心思想是“高密度推理 + 模型协作解码”。
- CoT 冗余分析与逻辑承载token
作者首先通过实验验证了 CoT 推理中存在大量冗余,并提出“逻辑承载 token”的概念,用以指代那些真正包含关键逻辑或数学推理信息的 token。实验表明,只保留这些 token 即可维持推理性能。
2. 强化学习驱动的 CoT 后训练(Post-training)
在后训练阶段,HAWKEYE 使用 GRPO 强化学习方法对一个 7B 模型进行微调,使其生成:
- 更短的 CoT;
- 更连贯、可解释的推理指令;
- 更有利于下游小模型理解与执行的推理结构。
奖励函数同时考虑:
- 小模型最终答案的精确匹配(Exact Match);
- CoT 长度相对于原始 CoT 的惩罚项。
通过引入“大模型生成 CoT,小模型负责答题”的奖励计算机制,有效避免了大模型通过跳过推理来“投机取巧”的问题。
3. 协同推理与双模型解码(Inference)
在推理阶段,HAWKEYE 采用两阶段解码流程:
- 大模型阶段:生成压缩且高密度的 CoT 作为推理指令;
- 小模型阶段:基于该 CoT 展开生成最终自然语言回答。
这种协同推理方式不仅降低了推理开销,还使系统在部署时具备更高的灵活性,例如可选择安全对齐或高效解码导向的小模型。

四、实验
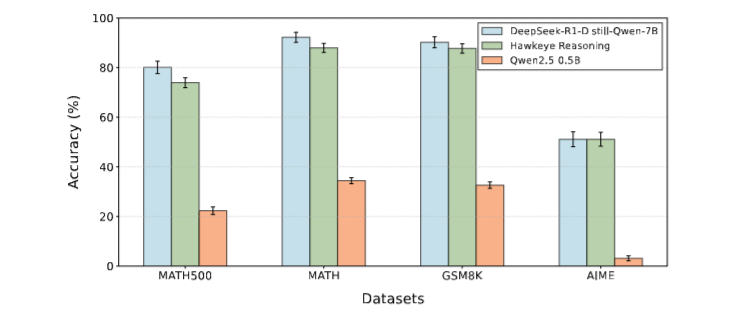
- 响应质量评估
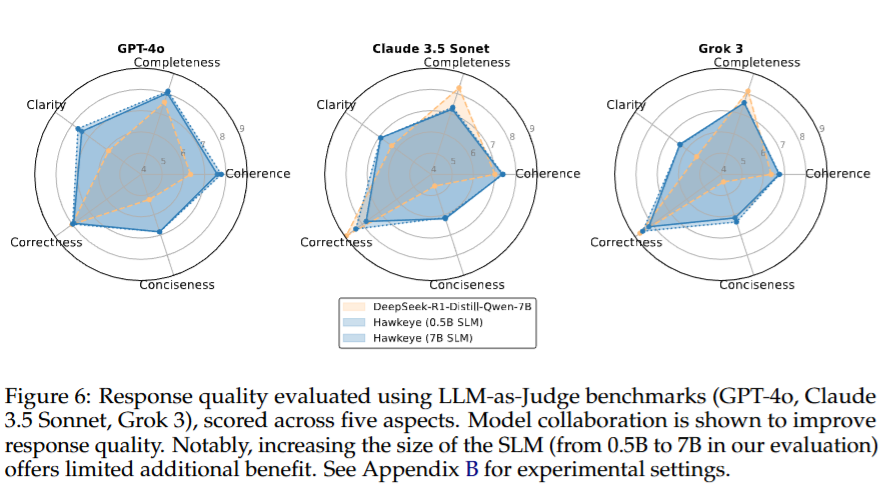
在 GSM8K、MATH、MATH500 等数据集上,HAWKEYE 的准确率相较基线模型仅下降 3%–6%。同时,通过 LLM-as-Judge(GPT-4o、Grok-3、Claude-3.5)在连贯性、清晰度、简洁性等维度进行评估,HAWKEYE 在多项指标上反而优于原始模型,显示出更好的用户可读性。
2. 推理延迟与吞吐量
在不同并发设置(10 / 100)下,HAWKEYE 相较基线模型实现了 1.6×–3.4× 的端到端推理加速,同时 token 使用量显著下降,验证了其在高并发场景下的实际部署价值。

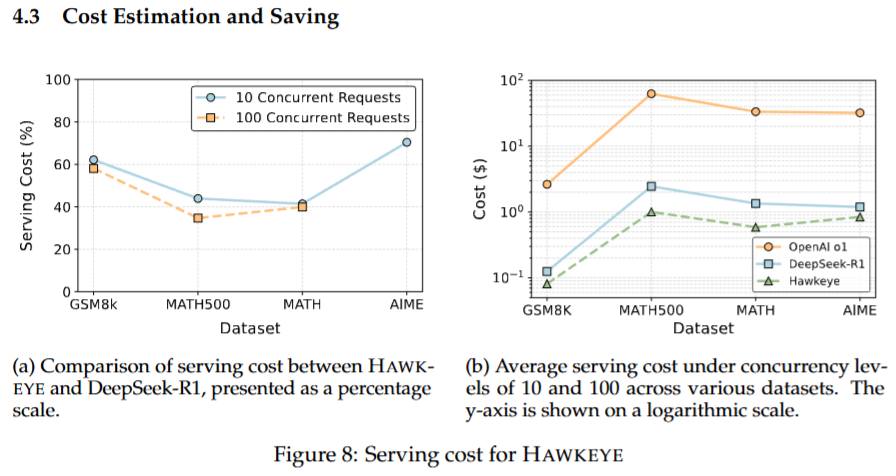
3. 成本节省分析
基于真实 API 定价模型的估算结果显示,由于输出 token 数大幅减少,HAWKEYE 在推理成本上相较 OpenAI o1 和 DeepSeek-R1 分别最高可节省 98% 与 59%,突出了该方法在工业级应用中的经济优势。
五、结论
本文提出的 HAWKEYE 框架表明,高质量推理并不依赖冗长的 CoT。通过系统性识别并压缩推理冗余,并引入模型协作机制,可以在显著降低成本与延迟的同时,维持甚至提升推理质量。
HAWKEYE 为推理模型的发展提供了一个重要启示:未来的可扩展推理系统,可能不再依赖“单一大模型长思考”,而是走向“大模型规划、小模型执行”的协同范式。这一思路对推理模型的训练、部署以及实际应用均具有较强的参考价值。