作者:Biplab Das · Viswanath Gopalakrishnan
时间:2025年
来源:CVPR 2025
背景
问题: 现有的伪装目标检测(COD)数据集(如COD10K, CAMO)数据量有限,且标注成本高。
现状: 现有的生成式伪装方法(如SOTA方法 LAKE-RED)在生成质量和伪装效果上仍有不足。传统的图像生成评价指标(FID, KID)无法准确衡量“伪装的质量”
目标: 提出一种能够利用现有的分割数据集(如COCO),自动生成高质量伪装图像的框架,并能提升下游检测任务的性能。
贡献
Camouflage Anything 框架: 结合了受控外绘(Controlled Out-painting, CO)和表征工程(Representation Engineering, RE)。不仅能填充背景,还能强制前景物体学习背景的纹理特征。
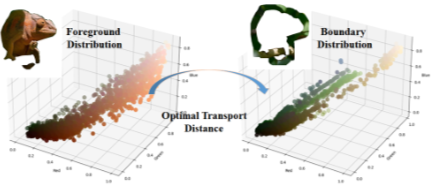
CamOT 指标: 提出了一种基于最优传输(Optimal Transport)的新指标。通过计算前景和背景的高斯混合模型(GMM)之间的Wasserstein距离,来量化伪装程度。
下游任务提升: 使用生成的伪装数据对SOTA分割模型(BiRefNet)进行LoRA微调,显著提升了伪装目标分割(COS)的准确率。
方法
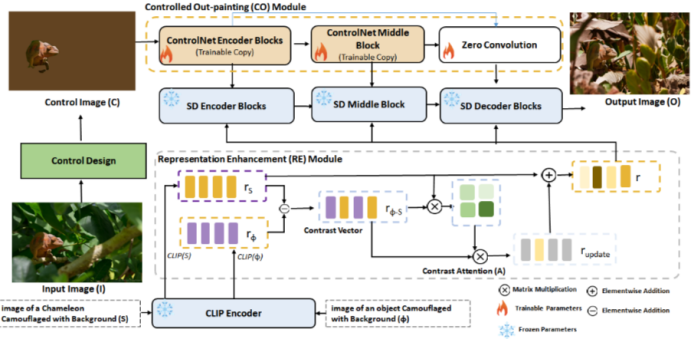
Camouflage Anything框架包含三个主要组件:
受控外绘模块 (Controlled Out-painting, CO): 基于 ControlNet 架构,负责引入空间掩码约束,控制生成内容的空间布局。 对于背景生成任务,计算背景区域的均值颜色 ,并按如下规则构造图像:
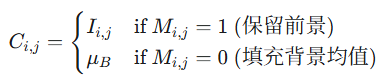
表征增强模块 (Representation Enhancement, RE): 基于 CLIP 编码器的潜在空间操作,负责构建并注入“伪装”语义特征。 设源文本描述为S,通用伪装描述为ϕ,对应表征为:
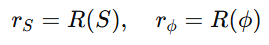
定义对比向量,刻画了目标语义相对于通用伪装语义的差异信息。
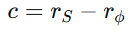
通过自注意力机制计算对比加权矩阵:

并生成更新表征
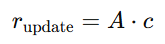
最终增强表征定义如下,该增强表征作为跨注意力条件输入至扩散模型的编码器与解码器阶段,用于引导背景纹理生成。

CamOT 评估度量: 为了解决 FID 和 KID 指标无法区分“高质量图像”与“高质量伪装”的问题,基于最优传输理论(Optimal Transport)的量化指标,提出 CamOT 指标,用于评估前景与背景的分布一致性。
高斯混合模型建模 (GMM Modeling):对于生成的图像,提取前景区域F(由掩码M定义)和局部背景区域B(M边缘外扩30像素范围)。分别使用期望最大化(EM)算法拟合两个高斯混合模型:
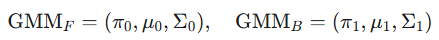
利用最优传输理论中的 Wasserstein-2 距离计算两个分布之间的差异,该距离量化了将前景纹理分布变换为背景纹理分布所需的最小代价。
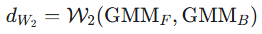
通过 Sigmoid 函数将距离映射为 [0,2][0,2]区间的质量分数(分数越高表示伪装效果越好,即分布差异越小):
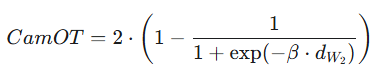
实验过程
数据集 训练数据:COD10K数据集中的5,066张图像
测试数据:LAKE-RED数据集
伪装物体(COD):来自COD10K、CAMO、NCAK
显著物体(SOD):从相关数据集中采样
通用分割物体(SEG):来自COCO数据集
总计:6,473个图像-掩码对
实验配置 基础模型:Stable Diffusion v1-5
训练设置:
Batch size: 4
迭代次数: 600,000
GPU: A6000 48GB
对比配置:
CO + RE + BG(使用背景颜色)
CO + RE – BG(背景设置为白色)
实验结果
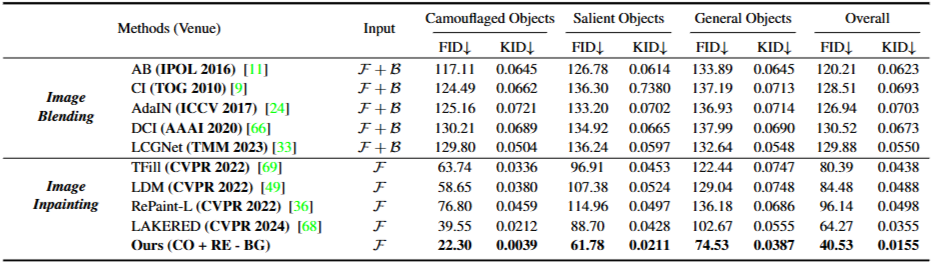

定量对比分析: 本研究提出的方法在所有测试子集及总体平均分上均取得了最优结果。具体而言,总体 FID 得分为 40.53,KID 得分为 0.0155,显著优于 SOTA 方法 LAKE-RED。


消融实验显示: 纹理质量:+RE配置显著改善背景纹理真实性,引入 RE 模块后,FID 从 55.58 降至 40.53,表明通过 CLIP 嵌入空间的语义增强有效地引导了生成过程,提升了图像的语义连贯性。
颜色一致性:+BG配置促进前景背景颜色融合。实验观察到一个显著的现象:虽然去除背景颜色控制(-BG)的配置在 FID/KID 指标上表现最佳,但在实际的伪装效果上,引入背景控制(+BG)能促使前景与背景的颜色分布趋于收敛。这揭示了传统生成指标(FID/KID)在评估“伪装”任务时的局限性——即高质量的图像并不等同于高质量的伪装(高对比度物体通常具有更好的 FID,但伪装性差)。
伪装效果:CO+RE+BG在视觉伪装效果上最佳

不同配置下的 CamOT 得分(分数越高代表前景与背景分布差异越小,伪装越好)。带有背景控制的配置在所有数据集划分中均取得了最高的 CamOT 均值,证实了通过显式地将背景均值颜色注入控制图像,模型能够生成纹理分布与背景高度一致的前景对象,从而实现更高级别的视觉隐身,验证了 CamOT 作为难度分级和伪装质量评估标准的有效性。
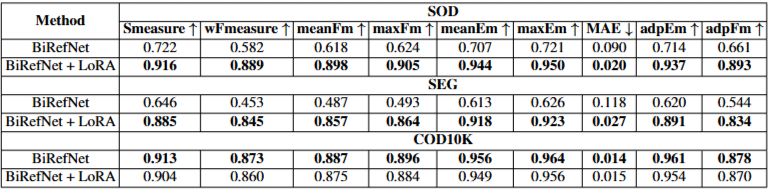
下游任务验证:为验证生成数据的实用价值,实验将生成的伪装数据集用于微调最先进的伪装目标分割模型 BiRefNet。 经过生成数据微调的模型(BiRefNet + LoRA)在 SOD 和 SEG 数据集上表现出显著的性能提升。 虽然在COD10K上性能略有下降,但在通用场景下的分割能力显著增强,证明模型泛化能力提升。
对齐思考
1. 技术创新—多模态拓扑认知
受论文中 表征工程(RE) 利用语义差值向量控制生成方向的启发,可以引入“跨模态拓扑认知”作为创新点。具体而言,在多模态交叉注意力机制中,需引入几何拓扑约束,可以构建一个“语义-几何双流注意力网络”:
语义流借鉴论文的 RE 模块,通过 CLIP 向量控制迷彩的“隐身程度”;
几何流则利用 ControlNet 提取的车辆 Mask 和边缘信息,计算持久同调特征,强制生成过程中的注意力图保持车辆的 3D 拓扑结构不变。
2. 技术目标—虚拟声景孪生生成
依托论文中 受控外绘与 CamOT的核心思想,可实现从单体适应到场域分布:论文通过计算前景 GMM 与局部背景 GMM 的 Wasserstein 距离来量化伪装,迁移到在多车场景下,可以设计一个“全局 CamOT 损失函数”,在生成多车图像时,不仅最小化单车与背景的距离,还要最大化车辆之间伪装纹理的多样性与协同性,模拟真实战场中“同一迷彩适应不同局部背景”的复杂分布。
构建伪装环境孪生: 借鉴论文中 Mask 引导的 Out-painting 逻辑,反向利用该技术构建“数字孪生训练场”。即:固定车辆的迷彩纹理(作为控制条件),利用生成模型反推最适合该迷彩的“背景环境”。这将极大地扩充数据的多样性,实现“车适环境”与“环境适车”的双向生成闭环,为训练高鲁棒性的检测模型提供完备的“分布孪生”数据支持。
3. 场景功能—EchoMie
论文的核心在于利用 CamOT 指标极值化地追求“前景融入背景”。对于 EchoMie,我们可以借鉴这种技术思想,利用论文中的分割掩码与局部重绘技术,实现前景(用户)与背景(环境)的语义解耦。当检测到“社恐/低落/内省”情绪时,算法可正向应用论文逻辑,提高背景纹理对人物边缘的渗透率(High Blending),生成一种人物与环境色调同频、边界柔和的“保护色”视觉风格,营造安全感与沉浸感;当检测到“自信/快乐/外向”情绪时,算法则反向应用论文逻辑,主动增大前景与背景的特征分布距离(Low Blending),强化人物主体的显著性与光影对比,生成主体突出的高光时刻视频。
可以借鉴 RE 模块,论文通过计算R_source – R_null提取出抽象的“伪装”向量并注入生成过程,EchoMie 可复用这一“抽象概念向量化注入”的机制,建立一个基于 CLIP 潜空间的情绪表征库,当 APP 评估出用户此刻心情为“复杂的怀旧”时,系统利用 RE 模块计算“当前环境语义”与“怀旧情绪语义”的特征向量,并通过交叉注意力机制(Cross-Attention)将其注入到视频风格迁移模型中。