来源:IEEE Transactions on Intelligent Transportation Systems 2025
单位:同济大学
作者:Jiaxiong Yang, Ning Jia, Xianhui Liu, Rui Fan, Yougang Sun,
Weidong Zhao
一、背景
现有的实时目标检测器主要依赖纯视觉特征,缺乏高级语义支持。虽然视觉语言目标检测(VLOD)方法通过引入 CLIP 等视觉语言模型 提升了分类性能,但仍存在两大缺陷:
- 文本特征利用不充分: 大多数VLOD方法主要在分类任务中使用文本特征进行对比学习,但未充分探索其对回归过程(即目标定位)的影响 ;
- 多模态融合不足: 现有的多模态融合方法未能将文本特征与多尺度图像特征在对应尺度上进行融合,这损害了模型的表示能力,可能导致概念混淆 。
针对上述问题,这篇文章提出Zone-Yolo,一种基于视觉语言模型的YOLO检测器。
二、贡献
- 尺度感知模态融合 (SAMF): 提出了一种双流多模态融合方法,通过尺度感知查询(Scale-Aware Query)在对应的尺度上对齐图像和文本特征,实现了从粗到细的特征增强,解决了多尺度融合中的概念混淆问题。
- 区域提示学习 (Zone Prompt Learning): 开创性地将文本特征引入回归头部。通过设计类别不可知区域提示、适配器和区域头部,捕获了“区域-类别-实体”的三元组共现信息,显著提升了定位精度。
三、方法
Zone-YOLO基于 YOLOv8 图像编码器和 CLIP 文本编码器构建,通过尺度感知 VL 颈部(VL-Neck)和区域头部(Zone Head)两个关键组件,实现了特征增强和定位指导。
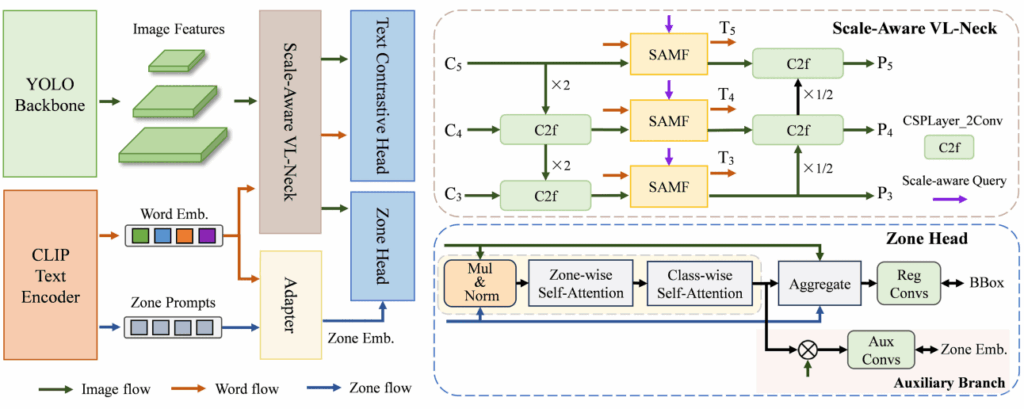
- 尺度感知模态融合 (SAMF)
SAMF 模块负责在网络的颈部实现多尺度图像特征和文本特征的精确对齐和无缝融合:
- 核心机制: 引入尺度感知查询(SQ)作为掩码,指导模态混合矩阵(MISAMF)针对当前尺度的图像特征,提取最相关的文本语义信息,从而有效抑制不同尺度间的概念混淆。
- 特征增强: 利用MISAMF 进行双向增强(通道增强和模态增强),实现了从粗粒度到细粒度的多模态特征提炼。
2. 区域提示学习方法
这是 Zone-YOLO 的主要贡献,它将文本的位置信息引入目标检测的边界框回归任务,以提高定位精度。
- 区域提示:使用类别不可知的 9 个固定位置名词(如“center”、“top left”)作为区域提示,避免指代模糊。
- 适配器:学习区域提示与类别词嵌入之间的 “区域-类别共现” 关系,生成类别特定区域嵌入(Z )。
- 区域头部:将 Z 与图像特征(实体信息)融合,捕获 “区域-类别-实体三元组共现” 知识,并通过自注意力机制精炼后,指导回归分支进行边界框预测。
- 辅助分支:采用自监督的 MSE 损失,确保区域嵌入在特征转换过程中的稳定性。
通过 Zone Prompt,模型不仅利用了文本进行分类对比,还利用其位置先验知识,解决了现有 VLOD 对定位任务指导不足的局限。
四、实验
- 数据集
- COCO: 通用目标检测基准。
- BDD100K: 自动驾驶场景,包含复杂天气和光照。
- VisDrone2019: 无人机视角,包含大量密集小目标。
- LVIS: 长尾分布数据集,用于测试泛化能力。
2. 表现
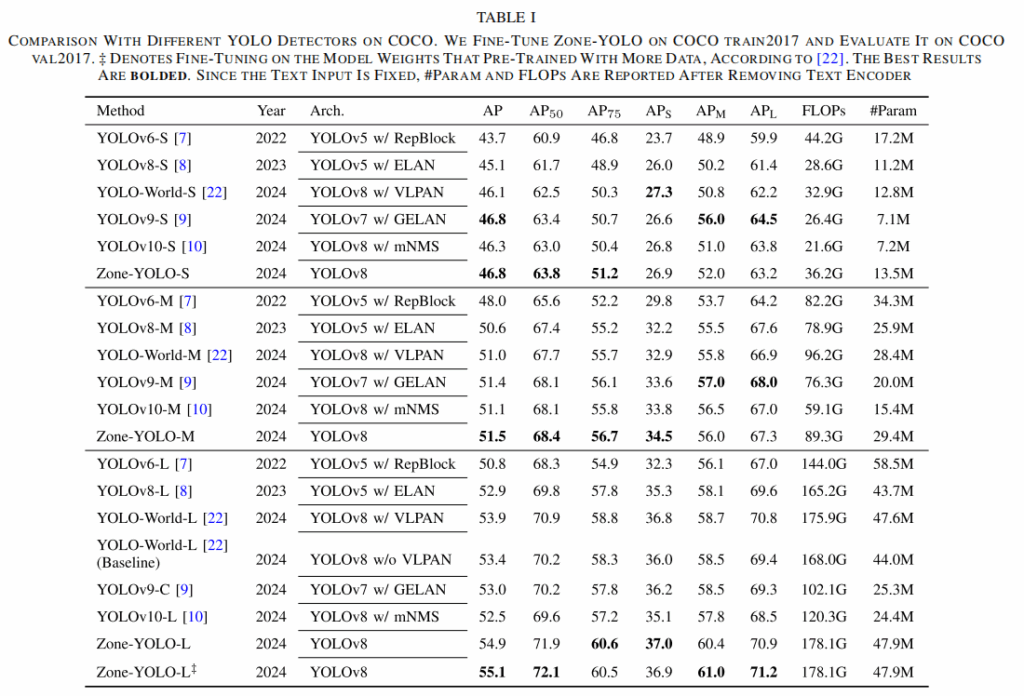
- COCO基准:
- Zone-YOLO-L 达到55.1 AP;
- 相比 YOLO-World 和 YOLOv9/v10,在 AP75 (高精度定位) 和 APL (大目标) 上提升显著,证明了引入区域提示对回归任务的有效性。
- 交通场景 (BDD100K & VisDrone):
- 在 VisDrone 上,AP50 比第二名高出 2.0,极大地改善了密集小目标的检测。
- 在 BDD100K 上,APL 表现优异,且 在弱光和复杂背景下鲁棒性更强。

五、结论
Zone-YOLO 成功地将视觉语言模型的优势扩展到了目标检测的回归任务中。通过 SAMF 实现了精细的多模态特征对齐,通过 Zone Prompt 机制利用“区域-类别-实体”共现信息显著增强了模型的定位能力。该模型在复杂交通场景下表现出卓越的性能和鲁棒性,为智能交通系统的感知模块提供了一个强有力的基础模型。