作者: Thomas Bonnier
单位: Centrale Lille Alumni, France
来源: Findings of the Association for Computational Linguistics
时间: 2024.08
一、研究背景

二、核心贡献

三、方法
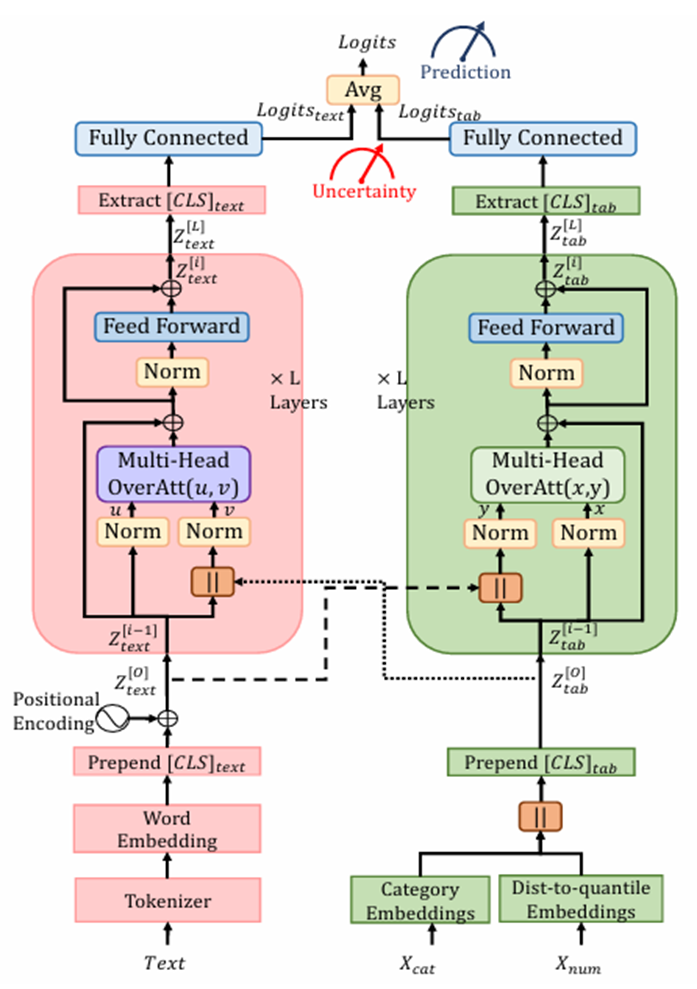
整体框架分为两条平行的处理路径,在处理过程中相互交流,但在最后又保持独立以进行不确定性评估
1)嵌入阶段:将不同模态数据首先转换为统一维度的向量
2)核心处理阶段:每一层用两个独立的模块,分别更新文本流和表格流,且更新时同时关注对方的信息特征
3)输出与预测阶段:经过处理后,两个流分别取出对应的[cls]token对应的向量,从而分别给出自己对类别的判断,最后对Logits取平均得出最终分类标签,还可比较两个流的预测结果。
四、实验
1.实验准备

2.实验结果
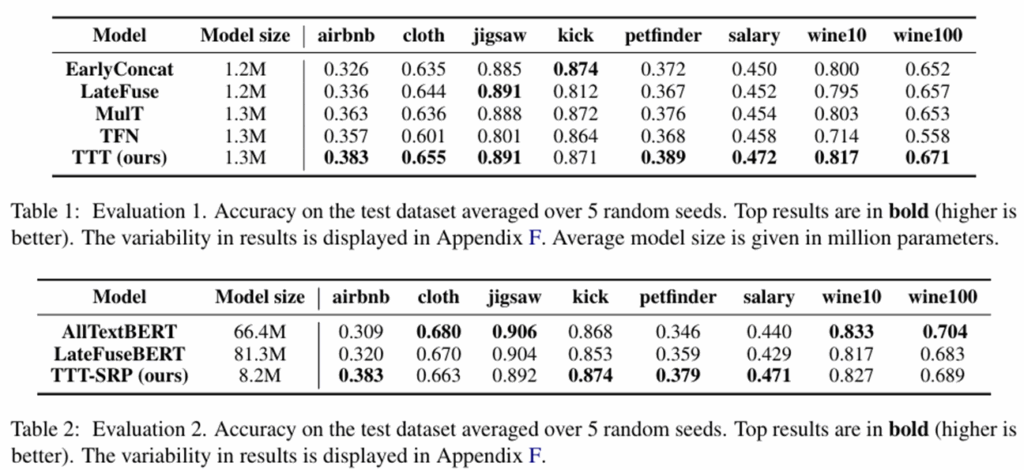
低维嵌入:即使在参数量相当的情况下,TTT的架构(整体注意力、分位数嵌入)比现有MulTi、LateFuse等架构优秀。
预训练模型:尽管参数量只有其他基线模型的1/10,但TTT-SRP任然在某些数据集上效果比大模型较好,说明TTT-SRP极为高效,不需要庞大的参数也能有效利用预训练的知识。
3.消融实验
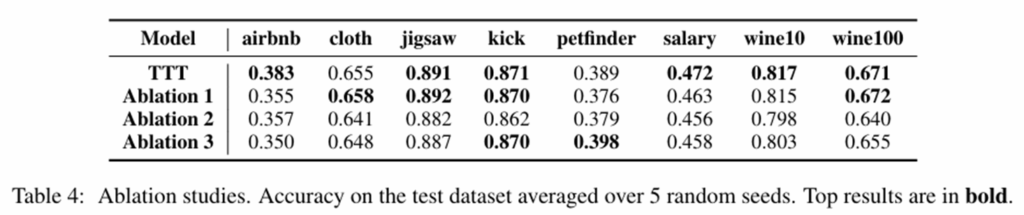
为证明三个核心组件缺一不可,设计了三个剥离实验,Ablation 1~3分别替换了分位数距离嵌入、整体注意力机制、损失函数。
1)Ablation 1性能下降,证明分位数距离嵌入确实更能捕捉数值特征和异常值信息。
2)Ablation 2性能下降最严重,证明TTT的核心就在于整体注意力机制,与传统注意力机制不同,能够权衡同一层中所有特征。
3)Ablation 3性能下降,证明迫使两个流各自独立学习能增强各自流的鲁棒性。
4.初始化策略
对比了三种将BERT向量降维的方法:稀疏随机投影(SRP)、主成分分析(PCA)、Kaiming初始化
由表5可知,TTT-SRP通常取得最好或接近最好的结果。可能是因为SRP能保留预训练embedding的稀疏结构或语义信号,同时避免过拟合和高维噪声;而PCA会丢失部分语义方向,Kaiming随机初始化没有预训练语义信息。

5.不确定性量化
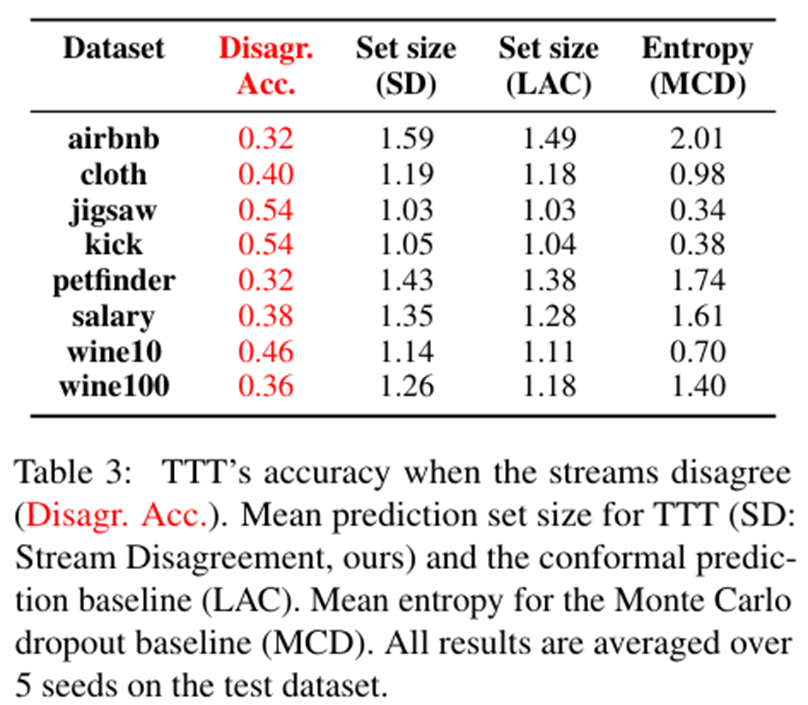
1)当模型判定为“不确定”时,其准确率显著低于平均水平,说明模型的不确定信号真实可靠。
2)本文生成的平均预测集大小与LAC非常接近,说明TTT的不确定性量化能力在统计学上是合理的,达到了主流方法的水平,并且拥有额外的可解释性。
3)从acc与size的负相关可看出,越准确集合大小越小,进一步验证了方法的有效性。
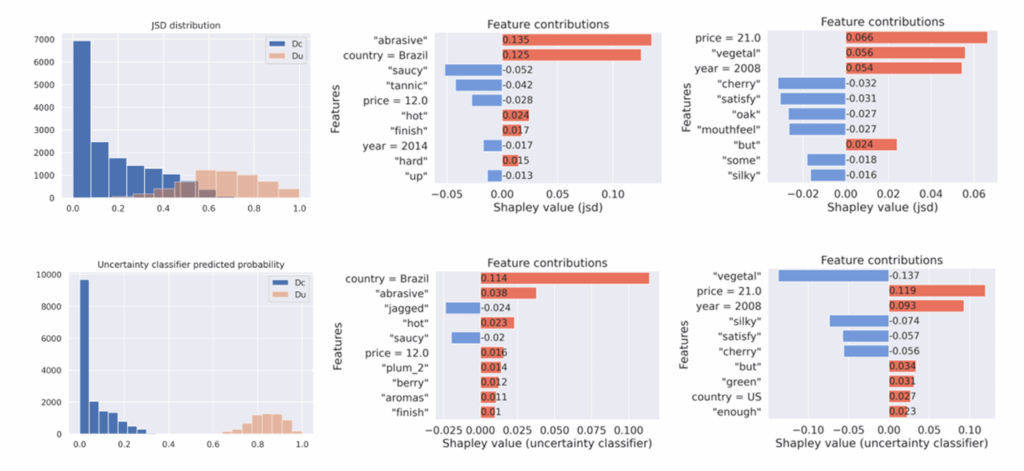
6.不确定性解释
1)左侧图表展示了两种方法区分“确定性预测”和“不确定性预测”的能力
2)中间图表展示了一个具体的不确定样本,并利用Shapley(一种解释性算法)找出来导致模型困惑的特征
3)右侧图表展示了一个人为制造的不确定性案例,用来验证解释方法的逻辑是否正确
五、总结
1)本文提出的TTT模型可用于专门处理包含文本字段的表格数据的多模态架构,还可通过双流架构的分歧来量化预测的不确定性,并解释为什么模型对这个样本不确定。
2)虽然本文目标是为了处理一些高风险的关键领域,但测试时使用的数据集和关键领域不大相关,在实际使用时应该在相关数据集上进行测试才能验证其有效性。
3)未评估文本序列长度过长或表格特征过长的情况,即不平衡长度对于模型性能的具体影响仍是一个未知数。
4)TTT提出的不确定性量化方法虽然简单直观,但在统计学上的严谨性不如适形预测,即预测集大小限制、准确率不可控、存在局部失效的风险。
六、对齐思考
1.1技术创新——数据拓扑标签计算: 分位数距离嵌入能够使得数值保留原有的表格特征;整体注意力机制使得查询某个词时,能够以同时关注文本数据的上下文和表格数据;还利用双流框架预测分歧指出意见不合的原因。
2.0技术目标——跨域知识结构对比:与自注意力机制和跨模态注意力机制不同,同时关注文本特征和表格数据特征。
3.0应用场景——能够对酒店、电影院或着电商进行预测分析,结合表格中的价格以及其他信息和一些人的评论进行预测,预测出好评或差评的理由是什么,还可以进行推荐