作者:Zeyue Tian , Yizhu Jin , Zhaoyang Liu , Ruibin Yuan , Qifeng Chen
来源:arXiv
单位:香港科技大学(Hong Kong University of Science and Technology, HKUST)
时间:2025 年 4 月
背景
近年来,音频生成,尤其是音效和音乐生成,已成为多媒体创作中的关键要素,在众多应用中提升用户体验方面展现出实际价值。音频和音乐生成已成为许多应用中的关键任务,但现有方法存在显著局限性:它们孤立运行,缺乏跨模态的统一能力,高质量的多模态训练数据稀缺,且难以有效整合不同输入。在这项工作中,这篇文章提出了AudioX,这是一种用于任意内容到音频和音乐生成的统一扩散变压器模型。与以往特定领域的模型不同,AudioX可以高质量地生成通用音频和音乐,同时提供灵活的自然语言控制,并能无缝处理包括文本、视频、图像、音乐和音频在内的各种模态。
主要贡献
1.提出统一的生成框架 AudioX
论文首次提出一个基于 Diffusion Transformer 的统一模型,在单一架构下同时支持
- 音频生成与音乐生成
- 文本、视频、图像、音频、音乐等多模态任意组合输入
有效突破了现有方法“任务单一、模态受限”的问题。
2.构建大规模高质量多模态音频与音乐字幕数据集
为缓解多模态数据稀缺问题,作者构建并标注了两个大规模数据集:
- VGGSound-Caps:约 19 万条音频字幕
- V2M-Caps:约 600 万条音乐字幕
为统一多模态音频生成模型提供了关键数据支撑。
3.输入级多模态掩码策略
不同于以往在特征层进行掩码的方法,AudioX 直接在原始输入层(文本 token、视频帧、音频片段)进行随机遮挡,有效避免特征泄露,显著提升跨模态表示学习能力。
技术方法
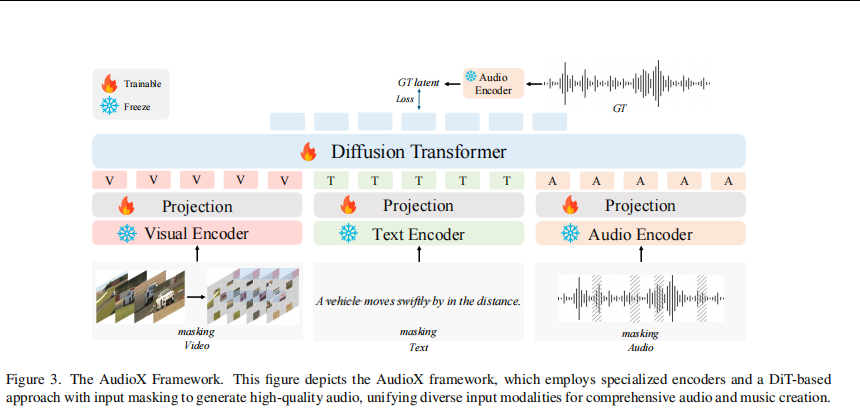
1.整体架构概述
AudioX 采用 “多模态编码器 + 投影层 + Diffusion Transformer(DiT)” 的统一架构,在潜空间中完成多模态条件建模与音频生成。模型以文本(Text)、视频/图像(Video)、音频(Audio)作为输入条件,输出高质量音频或音乐波形。
2.多模态输入与输入级掩码
模型支持三类输入模态:
- 视频模态(V):由连续视频帧组成
- 文本模态(T):自然语言描述
- 音频模态(A):音频或音乐片段
在进入编码器之前,AudioX 对每一种模态 独立进行输入级随机掩码:
- 视频:随机遮挡部分帧或图像 patch
- 文本:随机遮挡部分 token
- 音频:随机遮挡时间片段
这种输入级掩码迫使模型在信息不完整的情况下进行跨模态推理,显著增强了跨模态对齐能力与鲁棒性。
3.模态专用编码器
如图中雪花标识所示,AudioX 使用 预训练并冻结 的模态专用编码器:
- Visual Encoder:提取视频帧的视觉语义特征
- Text Encoder:提取文本语义表示
- Audio Encoder:将音频映射到潜空间表示
4.投影层与多模态条件融合
各模态编码器输出的特征维度不同,因此 AudioX 为每个模态设计了可训练的投影层(Projection):
- 将视觉、文本、音频特征映射到统一维度
- 对齐不同模态的表示空间
投影后的特征按模态顺序拼接,形成统一的多模态条件表示。该多模态条件向量作为 Diffusion Transformer 的条件输入。
5.Diffusion Transformer(DiT)生成模块
AudioX 的核心生成模块是 Diffusion Transformer,负责在潜空间中完成音频生成。
扩散模型(Diffusion Model):AudioX 使用扩散模型的核心思想,将输入数据逐步添加噪声,然后通过一个逆向过程逐步去除噪声,最终生成高质量的音频或音乐。
前向扩散过程:将输入数据逐步添加高斯噪声,生成一系列含噪的潜变量。
反向去噪过程:Transformer 学习预测噪声并逐步还原干净音频潜变量,实现条件音频生成。
实验分析
实验系统比较了 AudioX 与多种 SOTA 专用模型 在不同数据集和任务上的性能,涵盖 文本/视频到音频、文本/视频到音乐 以及多模态联合生成任务。评价指标包括生成质量(IS↑)、分布相似度(FD↓、FAD↓)、声学一致性(KL↓)、美学质量(PC↑、PQ↑)及语义对齐能力(Align.↑)。
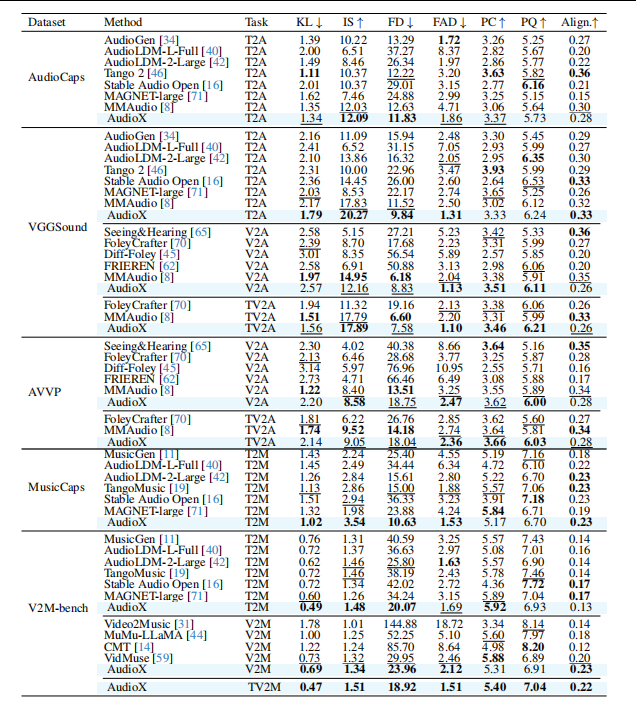
1. 文本到音频(T2A)任务分析
在 AudioCaps 与 VGGSound 数据集上:
- AudioX 在 IS、FD、FAD 等关键指标上整体优于或显著优于现有方法;
- 同时,FD 和 FAD 显著降低,说明生成音频在 整体分布与感知质量 上更接近真实音频。
2. 视频到音频(V2A)与文本+视频到音频(TV2A)
在统一视频-音频数据集 VGGSound 和跨域测试集 AVVP 上:
- 在 V2A 任务中,AudioX 在 FAD、PC、PQ 等指标上表现稳定,与 MMAudio、FoleyCrafter 等强基线保持同一水平;
- 在 TV2A(文本+视频) 场景下,AudioX 的 IS 和 PQ 普遍优于仅使用视频或文本的模型。
3. 文本到音乐(T2M)任务分析
在 MusicCaps 与 V2M-bench 数据集上:
- AudioX 在 IS、FD、FAD 等指标上全面领先 MusicGen、AudioLDM-2、TangoMusic、MAGNET 等音乐生成模型;
- 在 MusicCaps 上,AudioX 的 FD 和 FAD 显著低于所有对比方法,说明生成音乐在结构和音质上更加接近真实分布;
- 在 V2M-bench 上,AudioX 取得 最低 KL 和 FD,表现出更稳定的音乐生成能力。
4. 视频到音乐(V2M)与多模态音乐生成(TV2M)
在 V2M-bench 数据集上:
- AudioX 在 V2M 任务中取得 最优或次优的 IS、FD、FAD 与 Align. 指标;
- 当引入文本条件(TV2M)后,模型性能进一步提升,IS 达到 1.51,FD 和 FAD 进一步下降;
- 多模态输入显著改善音乐生成的语义一致性与整体质量。
总结
实验结果表明,AudioX 在文本到音频、视频到音频、文本到音乐、视频到音乐以及音频修复、音乐续写等多项任务中均取得了领先或具有竞争力的性能。尤其值得注意的是,统一模型并未牺牲单任务性能,反而在多模态条件下展现出更强的生成质量与语义一致性。这验证了论文提出的核心观点:音效生成与音乐生成可以在同一扩散框架中统一建模,而多模态条件能够显著提升生成效果。从方法论角度看,AudioX 不仅是一个性能提升的工程系统,更提出了一种 “通用音频生成模型(Generalist Audio Generator)” 的研究范式,为多模态生成领域提供了新的思路。