作者:Hsin-Ling Hsu , Ping-Sheng Lin等
单位:台湾政治大学
来源:Arxiv
时间:2025.03
研究背景与动机
1.1 检索增强生成(RAG)与混合检索
RAG(Retrieval-Augmented Generation)已成为知识密集型任务(如问答系统)的核心技术。
混合检索(Hybrid Retrieval)结合了:
稀疏检索(Sparse Retrieval,如 BM25):基于关键词匹配;
稠密检索(Dense Retrieval):基于语义嵌入相似度。
1.2 非叙述性文档的挑战
非叙述性文档(Non-narrative documents)如表格、财务报表等具有以下特点:
结构复杂(含大量表格、对齐格式);
词汇丰富、术语专业;
繁体中文存在大量同义词、语序敏感问题。
OCR处理这些问题时易出错:
字符识别错误(如“0”→“O”、“1”→“l”);
表格结构丢失,导致数据错位;
文本碎片化,破坏语义连贯性。
1.3 现有方法的不足
现有OCR后处理方法主要关注语言流畅性或可读性,而非检索性能优化。
缺乏针对混合检索双重要求(关键词匹配 + 语义理解)的文本预处理策略。
研究问题
该文旨在解决以下核心问题:
如何将OCR输出的噪声文本转化为同时适配稀疏检索(BM25)和稠密检索(Embedding)的高质量、结构保留、语义完整的文本?
具体包括:
修正OCR字符错误;
重建表格等结构信息;
重写文本以提升关键词覆盖(BM25友好)和语义表达(Dense Retrieval友好)。
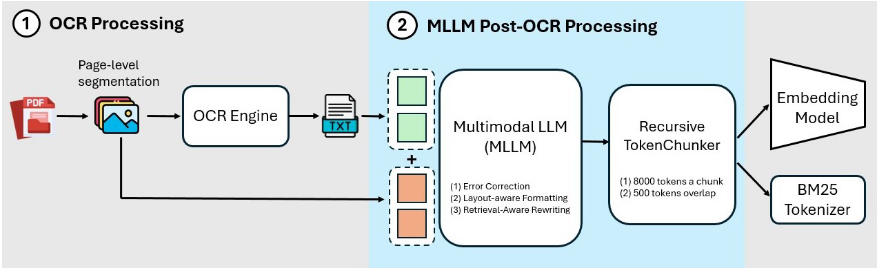
解决办法-KAP框架
KAP是一个两阶段预处理框架:
阶段1:OCR处理
使用 Tesseract OCR 提取PDF中的原始文本。
输出通常包含错字、格式混乱、表格结构丢失等问题。
阶段2:MLLM后处理(核心创新)
利用多模态大语言模型(MLLM,如 Claude-3.7-Sonnet)对OCR输出进行增强。该阶段通过精心设计的Prompt模板(原为繁体中文),实现三大功能:
3.1 错误校正(Error Correction)
修正OCR产生的拼写错误、数字错识、标点错位、语序颠倒等。
保持语义不变的前提下提升语言流畅性。
示例:将“公囸”纠正为“公司”。
3.2 布局感知的格式重建(Layout-Aware Format Reconstruction)
关键创新:MLLM可同时接收OCR文本 + 原始PDF图像。
利用视觉信息理解原始布局(如表格行列关系、标题位置),重建结构。
特别强调对表格内容的还原。
Prompt中明确指示:“可参考附图理解原文排版(如表格、叙述句),并判断各文字/数字在原文中的位置与含义。”
3.3 检索感知的重写(Retrieval-Aware Rewriting)
这是KAP最核心的设计,分为两类优化:
(a) 稠密检索优化(Dense Retrieval Friendly)
将表格/非纯叙述内容转化为自然语言描述句,便于语义嵌入模型理解。
示例:
原始表格:日期 | 公司 | 金额 → 2025/03/03 | XX公司 | $10,000
重写后:“2025年3月3日,XX公司记录了一笔$10,000的交易。”
(b) 稀疏检索优化(BM25 Friendly)
在保留原始关键词的基础上,自然融入同义词或近义表达,提升关键词召回率。
避免过度替换影响向量检索效果。
示例:
原文:“系統可以分析數據,以提升商業決策能力。”
重写:“系統能夠分析數據與相關資訊,幫助企業或公司做出更精確的決策,並提升整體策略。”
“數據” → 补充“資訊”;
“決策” → 扩展为“決策與策略”。
注意:重写顺序是先做Dense优化,再做BM25优化,确保两者兼容。
实验
数据集:
来源:E.SUN Bank 提供的非公开数据集(AI CUP 2024竞赛)。
包含三类文档:FAQ(JSON)、保险条款(PDF)、财务报告(PDF,重点研究对象)。
财务报告含大量表格,符合“非叙述性”定义。
验证集:每类50个问题,共150个;通过LLM数据增强扩展至500个问题,采用9种变换策略(如同义词替换、关键词抽取、句式变换等)。
模型选择
OCR引擎:Tesseract(支持繁体中文);
MLLM:Claude-3.7-Sonnet(强大多模态理解能力);
稠密检索模型:text-embedding-3-large(OpenAI);
分词器:Jieba(带繁体词典)。
Chunking策略
先按页面分割,保留上下文;
再用递归分块(Recursive Chunking),块大小8000 tokens,重叠500 tokens,避免表格被切碎。
Baseline:直接使用Tesseract OCR输出;
Ablation Study(消融实验):
KAP w/o Vision:禁用图像输入,仅用OCR文本;
KAP w/o OCR Text:仅用图像,让MLLM从头提取;
KAP w/o Rewrite:不做检索感知重写;
Full KAP:完整流程。
实验结果
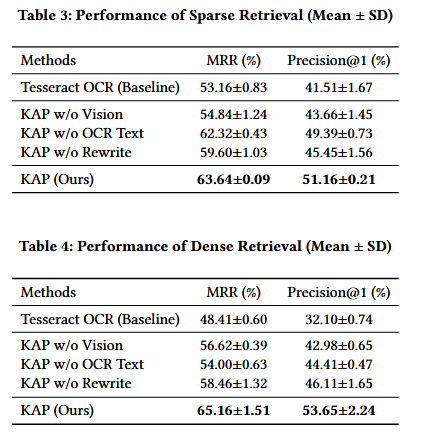
核心内容总结:
1.将MLLM用于面向混合检索的OCR后处理,而非通用文本修复;
2.提出“检索感知重写”双路径策略:
稠密路径:表格→自然语言描述;
稀疏路径:关键词保留+同义扩展;
3.多模态Prompt工程:在同一Prompt中整合纠错、结构理解、重写指令,高效统一;
4.构建面向混合检索的验证集增强方法:通过9种LLM驱动的查询变体,全面测试系统鲁棒性;