作者:Nusrat Jahan Prottasha, Md Kowsher, Hafijur Raman, Ivan Garibay et al.
单位:University of Central Florida, Daffodil International University
来源:ArXiv:2502.10660
时间:2025.02
一、研究背景

二、核心贡献

三、方法
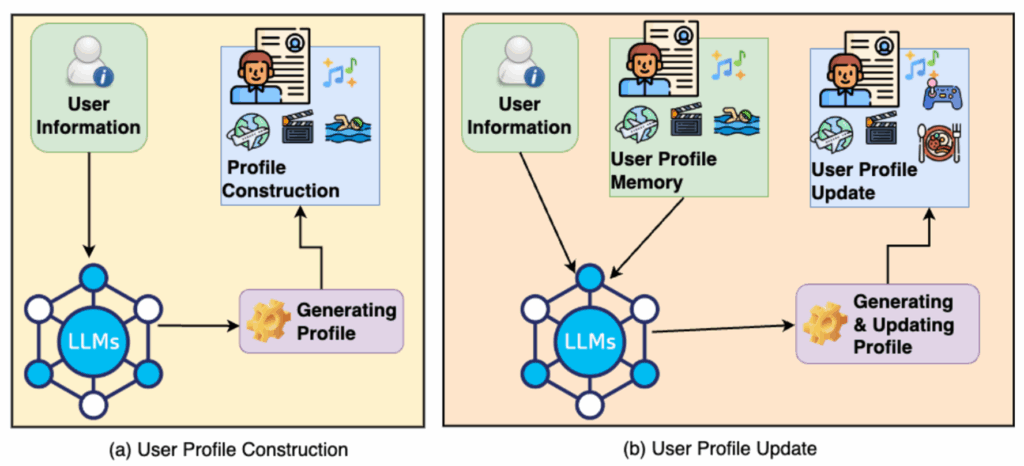
整体框架分为两部分: Profile Construction 和 Profile Updating
Profile Construction(把画像拆分为token序列,由LLM生成,本质上是一个文本生成结构化序列任务);Profile Updating(修补缺失属性、删除不再正确的属性、覆盖错误属性以及合并旧画像与新信息)
四、实验
1.实验准备

2.实验结果
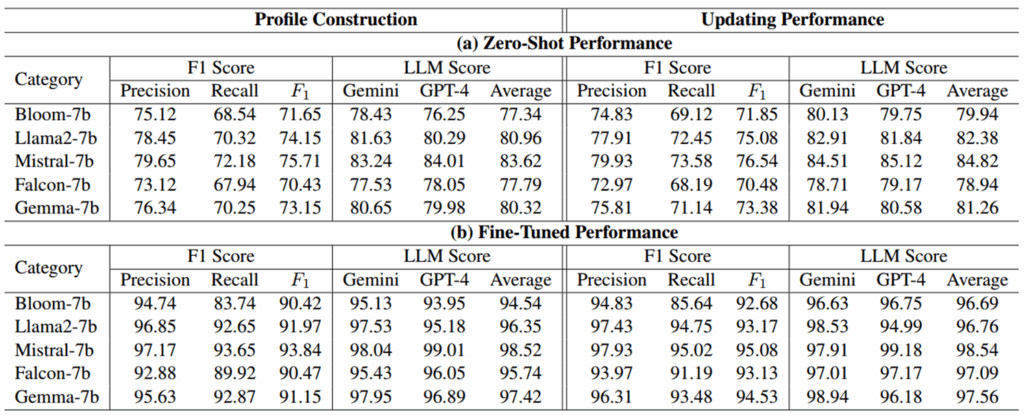
对于Profile Construction: 微调主要减少了 hallucination 与错误输出;微调帮助模型更全面地覆盖输入中存在的属性;自动化符号匹配指标与语义评估在总体上达成一致(模型生成既正确又自然)
对于Updating Performance: LLM 能学会“保留旧信息 + 整合新信息”的策略,有效利用旧画像与新增文本线索对画像进行修正和补全。
五、总结
1.LLM(尤其 Mistral-7B)在用户画像构建与更新上表现优异,在微调后基本达到90以上的user-level F1
2.微调收益远大于 zero-shot,提示在特定结构化输出任务上,少量有监督微调仍然是显著提高性能的有效手段
3.Prompt-based LLM 评分(GPT-4/Gemini)和符号指标(F1)一致提升,为结果的可靠性提供了二次验证
4.数据与训练策略(PEFT、schema、prompt)是高性能的关键
六、思考
1.1技术创新——数据拓扑标签计算: 对比神经网络、知识图谱、图神经网络等方法构建用户图像,LLM能够直接理解非结构化文本端到端生成用户画像,并且支持基于新文本的即时画像更新
2.0技术目标——跨域知识结构对比: 感觉可以和多模态大模型一样,将不同类型的数据一同输入,多模态大模型会将其映射到同一特征空间进行理解处理
3.0应用场景——食养通: 可以对照片上扫描出来的文字进行标签提取,提取出对应的营养成分或添加剂,以此再进行评分估计;或者根据扫描出来的营养成分分为对应的食品类别