作者:Wenhui Liao, Jiapeng Wang, Hongliang Li等
单位:华南理工大学,阿里云计算,Scut-珠海现代产业创新研究院
来源:CVPR2025
时间:2024.08
研究背景与动机
当面对文档图像(如发票、表格、合同等)这类富含布局信息(Layout)和视觉结构(Visual Structure)的复杂数据时,标准LLM显得力不从心。
当前的文档理解(Document Understanding, DU)方法主要分为两类:
OCR依赖型方法:首先使用OCR引擎将图像中的文字识别出来,并通常附带文本内容及其在页面上的坐标(bounding boxes)。然后将这些“富文本”信息输入到下游模型中进行理解。这种方法的瓶颈在于OCR的准确性,尤其是在处理低质量、手写或复杂版式的文档时,OCR错误会直接传导并放大到后续的理解任务中。
OCR-free方法:试图直接从原始像素出发,绕过OCR步骤,利用多模态大模型(如基于ViT的视觉编码器+LLM)进行端到-end的理解。这类方法虽然避免了OCR错误,但面临着巨大的挑战:
训练数据污染:许多用于训练这些多模态模型的大规模图文数据集,本身就包含了来自公开DU基准(如FUNSD, CORD)的数据。这导致模型在官方测试集上的表现可能被高估,无法真实反映其在未见过的新数据集上的泛化能力。
效率与性能瓶颈:直接处理高分辨率文档图像计算成本高昂,且模型难以精确捕捉细粒度的文本内容和复杂的布局关系。
因此,领域内亟需一种既能有效利用布局信息、又不过度依赖OCR、同时具备强大零样本(zero-shot)泛化能力的高效文档理解框架。
该文旨在解决以下核心问题:
如何在不依赖高质量OCR输出的前提下,构建一个高效的文档理解模型?
如何设计一种新的表示方法,既能保留文档的关键布局和结构信息,又能以LLM友好的方式输入,从而实现强大的零样本泛化能力?
如何克服现有OCR-free方法因训练数据污染而导致的评估偏差问题?
解决办法-DocLayLLM
DocLayLLM的核心思想是:不直接输入原始像素或冗长的OCR坐标序列,而是将文档图像“编译”成一种简洁、结构化的“文档标记语言”(Document Markup Language),再将其作为纯文本指令输入给LLM。
DocLayLLM 的整体架构可以被看作是一个两阶段的流水线:感知阶段(Perception Stage)和推理阶段(Reasoning Stage)。其精髓在于如何在这两个阶段之间设计一个高效的、信息丰富的桥梁——即“文档标记语言”和配套的推理策略。
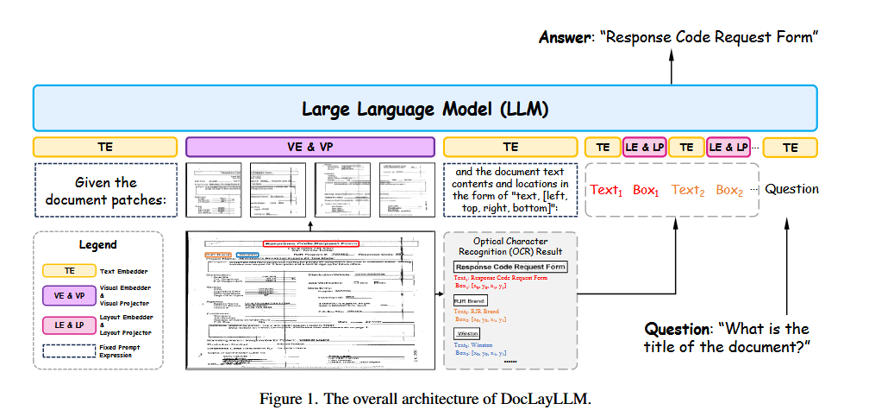
第一部分:感知阶段(Perception Stage)
文档布局解析(Document Layout Parsing)
首先,使用一个预训练的、通用的文档布局分析模型(例如,基于Detectron2或类似架构的模型)来处理输入的文档图像。
该模型会检测出文档中的不同语义区域(Semantic Regions),例如:text, title, list, table, figure, form 等,并为每个区域生成一个边界框(Bounding Box)。
区域内文本识别(Intra-region Text Recognition – 可选但推荐)
对于每个被识别出的文本类区域(如text, title),使用一个轻量级的OCR引擎(如PaddleOCR, Tesseract)来识别其中的文字内容。
关键点:这里的OCR仅用于获取区域内的纯文本内容,不再需要其精确的字符级或单词级坐标。这大大降低了对OCR精度的苛刻要求,因为即使OCR有少量错误,只要不影响整体语义,LLM依然可以理解。
构建“文档标记语言”(Constructing the Document Markup Language)
这是DocLayLLM最核心的创新。系统将上一步得到的布局区域和文本内容,按照它们在页面上的空间位置关系(主要是从上到下、从左到右的阅读顺序),组织成一种类似HTML/XML的结构化文本。
构建“文档标记语言”(Constructing the Document Markup Language)
这是DocLayLLM最核心的创新。系统将上一步得到的布局区域和文本内容,按照它们在页面上的空间位置关系(主要是从上到下、从左到右的阅读顺序),组织成一种类似HTML/XML的结构化文本。
这种表示法显式地编码了文档的层次结构和语义类型,同时隐式地通过标签的顺序编码了空间布局信息。它将复杂的多模态信息(图像+布局+文本)统一转化为了LLM最擅长处理的纯文本序列。

第二部分:推理阶段(Reasoning Stage)与 CoT 策略
这是DocLayLLM展现其智能的地方。它不仅仅是将 DML 丢给LLM,而是通过精心设计的 Chain-of-Thought (CoT) 提示工程,引导LLM进行符合文档理解逻辑的逐步推理。
Layout-Type-Related CoT (布局类型相关 CoT)
这种CoT主要用于键值对信息抽取(KIE)等任务,其目标是推断某个特定区域的布局类型或从中提取信息。
适用场景: 当用户查询指向一个具体的区域(通过bounding box给出)时。
CoT 步骤:
Step 1: 定位与区域描述
“首先,识别查询区域 [x1, y1, x2, y2] 内的文本内容,并确定该区域在文档中的大致位置(例如,左上角、右下角等)。”
Step 2: 寻找最近邻
“然后,找到与该查询区域在空间上最接近的其他布局区块,并评估它们的布局类型(例如,它是否紧邻一个‘标题’或位于一个‘表格’内部?)。”
Step 3: 基于上下文推理
“最后,综合以上信息,推断出查询区域的布局类型或所需的信息。”
作用: 这种CoT教会LLM像人类一样,通过局部上下文(附近的元素是什么)来理解一个未知区域的含义。例如,一个孤立的数字如果紧挨着“Total:”字样,很可能就是总金额。
Geometry-Related CoT (几何关系相关 CoT)
这种CoT主要用于文档视觉问答(VQA)等需要理解元素间空间关系的任务。
适用场景: 当问题涉及到两个或多个文本片段之间的相对位置关系时(例如,“‘Conclusion’这个词在‘AIR’这个词的哪个方向?”)。
CoT 步骤(根据您提供的知识库内容):
Step 1: 获取坐标
“‘Concluding’ is located at [35,17,167,49] and ‘AIR’ at [816,259,858,289].”
(首先,从DML或附加的元数据中提取两个关键词的精确边界框坐标。)
Step 2: 投影分析
“The vertical projection is 35–167 for ‘Concluding’ and 816–858 for ‘AIR’; the horizontal projection is 17–49 for ‘Concluding’ and 259–289 for ‘AIR,’ with no overlap.”
(接着,分别计算两个框在X轴(垂直投影)和Y轴(水平投影)上的区间,并判断它们是否有重叠。没有重叠意味着它们既不在同一行也不在同一列。)
Step 3: 中心点计算与方向判断
“The centers are (101,33) for ‘Concluding’ and (827,274) for ‘AIR’.”
(然后,计算两个边界框的中心点坐标。)
Step 4: 最终结论
“Since the center of ‘Concluding’ has a smaller X and Y coordinate than ‘AIR’, it is located to the top-left of ‘AIR’.”
(最后,通过比较中心点的坐标,得出最终的空间方位关系。)
作用: 这种CoT将抽象的空间关系问题,分解为一系列可计算的、基于坐标的几何操作。它赋予了纯文本LLM一种“空间想象力”,使其能够精确回答关于布局的问题。
第三部分:模型集成与训练
LLM选择: 使用一个强大的开源LLM(如Vicuna-7B),并且冻结其所有参数。这保证了模型的通用语言能力不会被破坏,同时也极大地节省了计算资源。
输入构造: 将任务指令、DML字符串以及相应的CoT模板(作为Few-shot示例或系统提示)拼接成一个完整的Prompt。
训练: 由于LLM是冻结的,训练仅涉及一个非常轻量级的视觉适配器(Visual Adapter)或LoRA模块,用于微调模型以更好地理解DML的语法和遵循CoT指令。训练数据量需求很小。
推理: 在推理时,整个流程是确定性的:图像 -> 布局分析 -> OCR -> DML -> Prompt -> LLM -> 答案。
DocLayLLM 的完整工作流如下:
视觉感知: 用传统CV模型解析文档的布局结构和区块文本。
信息编译: 将感知结果编译成LLM友好的**结构化文档标记语言 **(DML)。
智能推理: 通过精心设计的 Layout-Type-Related 和 Geometry-Related 两种 **Chain-of-Thought **(CoT) 策略,引导冻结的LLM对DML进行深度理解和推理。
高效实现: 整个系统训练成本低,推理速度快,且对OCR错误鲁棒。
训练策略(Training Strategy):
高效性体现:由于LLM的参数是冻结的,整个训练过程只需要微调一个非常轻量级的适配器(Adapter)或者甚至只进行上下文学习(In-context Learning)。
训练数据仅需少量的(文档标记语言,指令,答案)三元组,即可让模型学会如何响应各种DU任务。
实验
数据集:
训练集:使用了多个标准DU数据集(如DocVQA, RVL-CDIP等)来构建“文档标记语言”格式的训练样本。
测试集:在多个具有挑战性的基准上进行了评估,包括:
OCR-dependent benchmarks: FUNSD(表单理解), CORD(收据理解), SROIE(票据信息抽取)。
OCR-free / VQA benchmarks: DocVQA(文档视觉问答)。
关键控制:作者特别强调并验证了他们的训练数据不包含FUNSD、CORD、SROIE等测试集的任何样本,以确保评估的公平性和对零样本泛化能力的真实检验。
对比方法:
SOTA OCR-dependent methods: 如UDoc, StructEqTable等。
SOTA OCR-free methods: 如Donut, Pix2Struct等。
评估指标:
根据不同任务采用相应指标,如F1-score(信息抽取)、ANLS(DocVQA)等。
实验结果
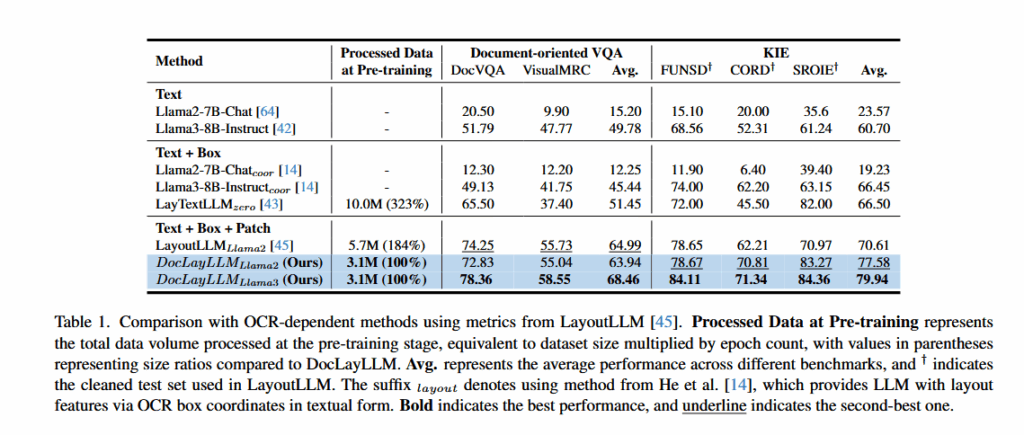
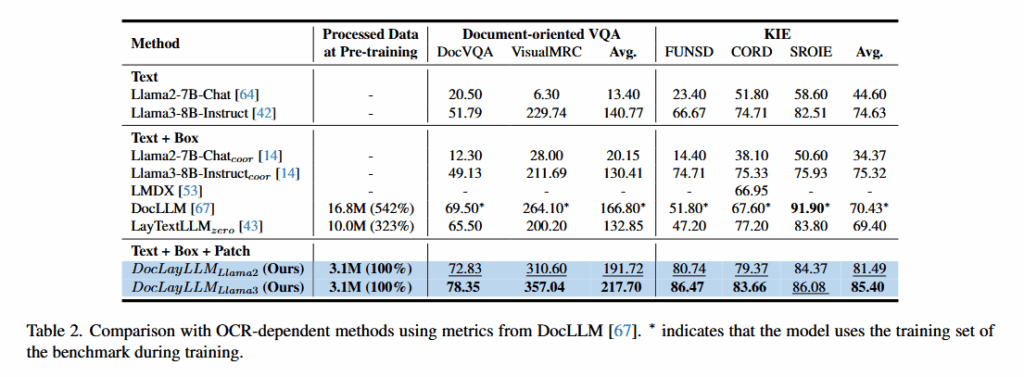
核心内容总结
“文档标记语言”表示法:最核心的创新。用一种简洁、结构化、LLM原生友好的方式,统一编码了文档的语义类型、层次结构和空间布局信息。
解耦的两阶段架构:将复杂的视觉感知任务(布局分析、粗略OCR)与高级语义理解任务(由LLM完成)解耦。这种模块化设计提高了系统的灵活性、可维护性和效率。
高效的训练范式:通过冻结LLM并仅微调轻量级组件,极大地降低了计算资源需求,使得在有限资源下也能部署强大的DU模型。