作者:Jiasen Lu1* Christopher Clark 1* Sangho Lee1* Zichen Zhang1* Savya Khosla2 Ryan Marten2 Derek Hoiem2 Aniruddha Kembhavi
时间:2024年6月
来源:CVPR 2024
背景
1、多模态智能是人工智能发展的关键方向
随着 AI 应用逐渐从单模态(如图像识别或文本生成)扩展到需要跨视觉、语言、语音、动作等多种模态的复杂任务,构建能够统一感知与生成多模态信息的模型成为重要研究目标。
2、现有方法仍存在模态割裂与任务专一的问题
以往的多模态模型多聚焦于“视觉-语言”结合(如图文匹配、VQA),缺乏对音频和动作等模态的统一处理;同时,大多数模型针对特定任务定制,难以在不同模态与任务之间共享知识或迁移能力。
3、统一建模面临结构与训练难题
不同模态的数据形式、尺度和语义差异极大,直接整合会导致表示不兼容、训练不稳定和计算成本高等问题,要实现真正的统一模型,需要在输入输出表示、模型结构、优化目标上设计通用机制。
4、自回归建模提供了潜在解决思路
近期自回归 Transformer 在语言和视觉生成领域表现出强大泛化能力,其“逐步预测下一个 token”的机制为多模态统一建模提供了自然框架:只要将所有模态转换为统一的 token 序列,即可用同一模型进行学习与生成。
主要贡献
1、提出统一的多模态自回归框架
作者设计了一个能够同时处理视觉、语言、音频和动作四种模态的自回归模型,使不同模态的理解与生成任务在同一架构内完成,该模型以“预测下一个 token”的统一范式实现多模态输入输出的整合。
2、构建通用的模态编码与表示机制
论文提出一种统一的 token 化方案,将图像、语音、文本、动作等不同模态数据转换为兼容的 token 序列,并通过模态嵌入(modality embeddings)标识模态属性,从而实现模态间的信息对齐与共享。
3、改进架构以增强训练稳定性和模态平衡
为解决多模态混合训练中常见的梯度冲突与模态偏置问题,作者设计了新的网络结构与优化策略,包括模态特定的前后处理模块、任务平衡训练调度机制,以及基于多模态去噪目标的学习方法。
实验过程
核心目标:
1、通用性:验证模型是否能同时处理多种模态任务;
2、有效性:检验自回归统一框架的性能是否能与专门单模态模型竞争;
3、可扩展性与可解释性:分析不同架构与训练策略对模型稳定性与性能的影响。
训练数据与规模:
作者整合了来自 120 余个公开数据集 的多模态数据,覆盖从图像–文本到音频–动作的多任务场景
为了实现多模态统一,作者提出了一个关键机制:统一token 化(Unified Tokenization)。所有模态数据均被映射到统一的离散 token 空间:图像被分割为固定大小的patch,再编码为离散token;音频通过时频变换生成声谱token;动作被量化为连续控制参数的离散表示;文本保持原始的词或子词token形式。所有这些 token 都加上模态标签,比如 [V] 表示视觉、[A] 表示音频。
所有输入与输出都以同一序列格式表示,模型随后以统一的自回归方式预测“下一个 token”,Transformer 模型可以在同一架构下理解、推理和生成多种模态内容。
模型架构:
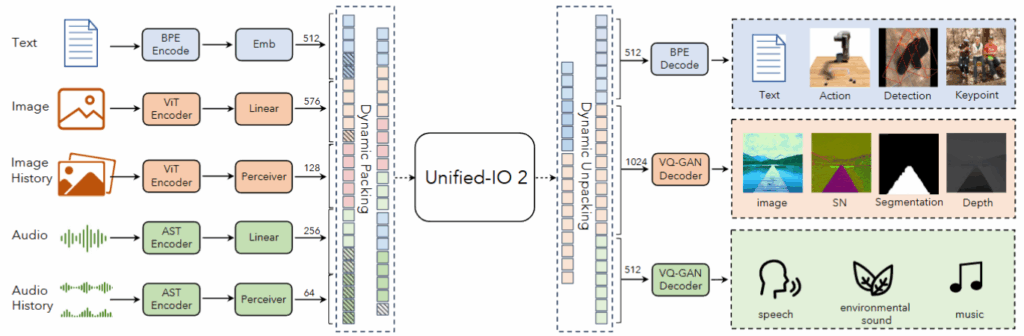
1、主干结构
模型采用 Encoder–Decoder Transformer 架构
Encoder对输入 token 序列进行多层自注意力建模,提取模态间联合表示;
Decoder在自回归机制下逐步生成输出 token,可对应文字、图像块、语音片段或动作指令。
2、融合方式:Cross-Attention
Encoder与Decoder之间通过Cross-Attention模块实现模态交互:
文本token可关注图像token,从而完成视觉问答等任务;图像token可响应语言 token,实现文本到图像的生成;语音与动作token可参与相互条件建模。
训练目标与优化策略
1、Mixture-of-Denoisers Objective
训练采用多模态去噪目标函数:模型在输入序列中随机屏蔽部分 token(可来自任意模态),要求模型在生成阶段重构被掩盖部分,这种策略使模型能够同时学习理解(识别被遮蔽内容)与生成(重建输出)的双重能力。
2、稳定性与模态平衡机制
由于多模态数据分布差异显著,作者引入以下机制以保持训练稳定性,确保模型在多模态并行训练过程中能够稳定收敛,而不会出现模态主导或性能塌陷现象:动态调整各模态在训练 batch 中的比例;保留模态特定前后处理层,在统一框架中保留轻量的模态适配器;进行梯度裁剪与正则化,防止梯度爆炸;通过自然语言提示词引导任务类型,增强模型的任务可识别性。
实验结果
zero-shot(零样本)任务 下的跨模态推理能力
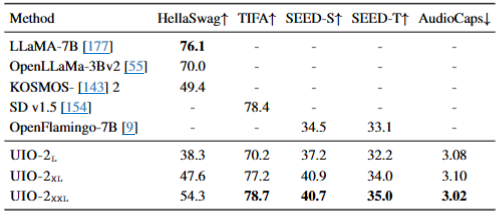
涉及任务:
- HellaSwag:常识性句子补全
- TIFA:文本到图像生成
- SEED-Bench:空间与时间理解
- AudioCaps:文本到音频生成
Unified-IO 2 在不经任务特定微调的情况下,具备较强的跨模态泛化能力
GRIT Benchmark 综合评测
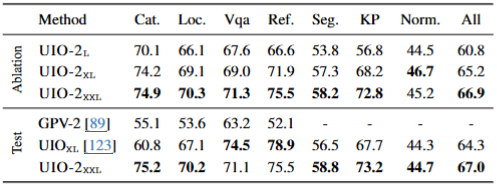
评估了从图像理解到语言生成、知识推理等任务的统一性能,与多任务基线 GPV-2 相比,UIO-2-XXL 的整体性能(All=66.9)显著领先,验证了统一建模的高效性与任务迁移性。
跨模态生成任务
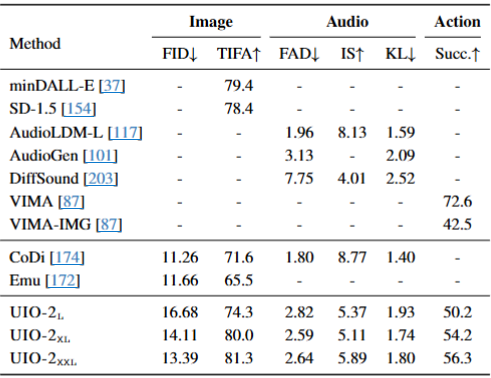
FID 降低(图像生成更逼真),TIFA 提升(文本–图像一致性更高),FAD 与 KL 减小(音频生成更自然),动作生成成功率(Succ)由 49.0 提升至 56.3,说明统一框架对复杂时序控制任务也有良好适应性。
视觉–语言任务表现
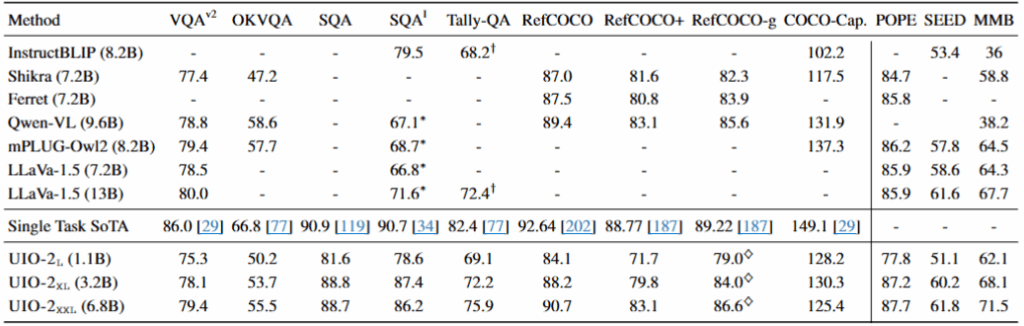
展示了模型在九个视觉语言任务上的表现,包括:
- 图像问答(VQA、OKVQA、SQA 等)
- 指代消解(RefCOCO 系列)
- 图像描述(COCO-Cap)
- 视觉推理(POPE、SEED、MMB)
在所有视觉语言任务中,UIO-2-XXL均接近或超过单任务SOTA模型;在指代消解任务中,达到 90.7%,优于多数开源模型;在复杂视觉推理任务中,表现尤其突出,说明模型具备跨模态逻辑推理能力。
视频与音频理解任务
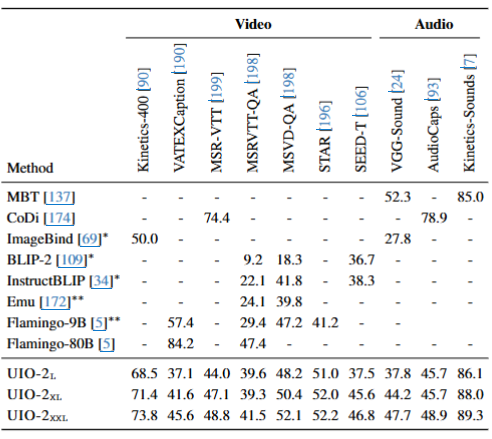
验证了模型在 时序模态(视频、音频)下的能力
- 在视频任务(MSVD-QA、STAR)上,UIO-2-XXL 接近专门的视频语言模型;
- 在音频任务(AudioCaps、VGG-Sound)上表现稳定;
- 说明统一建模在处理时间序列模态上同样具有强泛化性;
启发与局限
1、主要结论
- 统一自回归多模态架构在视觉、语言、音频、视频等任务中表现优异,验证了多模态统一建模的可行性;
- 模型性能随规模扩大显著提升,呈现清晰的 scaling law;
- 在零样本和跨模态迁移任务上表现出强泛化能力;
- 在图像、音频、动作生成等任务中达到或接近专用模型水平,兼顾理解与生成能力。
2、局限性
- 模态间数据分布不平衡,音频与动作任务表现仍落后;
- 向量量化虽统一表示,但造成部分高保真信息损失;
- 模型训练资源消耗巨大,难以广泛复现;
- 模态交互过程可解释性不足,生成控制能力有限。
3、未来方向
- 提升模态平衡与时序建模能力,增强复杂场景理解;
- 优化量化与统一表示机制,减少信息损失;
- 探索轻量化与高效训练策略,降低资源成本;
- 增强模型可解释性与生成可控性,推动通用多模态智能体发展。