来源:ACM Transactions on Knowledge Discovery from Data
作者:Bijay Prasad Jaysawal,Jen-Wei Huang
单位:National Cheng Kung University
发表时间:2024年12月
一、研究背景
高效用模式(HUP)挖掘的研究源于高频模式挖掘,而高频模式挖掘仅将模式频率作为数据库中的重要值,未考虑单个项目的独立性,HUP挖掘则兼顾了项目的个体效用。数据挖掘方面已经广泛展开从静态数据库中挖掘HUP的研究,对于数据流环境的HUP挖掘研究极为有限,也更有挑战。在过去十几年里,提出过几种挖掘HUP的算法,但都采用两阶段设计,第一阶段剔除较低效用选项,采用了高估的效用上界,如此还是会产生大量候选集,难以扩展,尤其是采用了较小的阈值时;第二阶段需重新扫描数据库以确认其真实效用,效率低下。随后有人提出了一些单阶段算法,分别提出了更紧的上界、更好的剪枝、事务合并、批量计算等方面的优化,还有一些特定领域的研究,如挖掘Top-K高效用项集、挖掘闭高效用项集、以高效用项集优化商店商品陈列等。
二、核心内容
这篇文章提供的也是一种单阶段算法(SOHUPDS+),是基于阈值的高效用项集挖掘,即找出所有超出给定阈值的效用项集,更为通用基础。
- 提出的SOHUPDS+,用于在数据流的当前滑动窗口中挖掘具有绝对或相对最小效用阈值的高效用项集
- 提出了名为IUDataListSW+的数据结构,用于存储和维护当前滑动窗口中的每个项的效用值、上界值及其在事务中的位置,从而高效获取投影数据库
- 提出了BitMapTransactionMerging技术实现事务合并,在高密度数据集上显著缩短效用值和上界计算的执行时间
- 提出了更新策略,利用前一滑动窗口挖掘出的HUPs来更新当前滑动窗口的HUPs
- 对比了提出的SOHUPDS和SOHUPDS+在稀疏型和密集型真实数据集的有效性和效率,并与最先进的算法进行比较
三、方法
首次完整挖掘,后续增量更新,其中更新依据两个标志(batchAdded,batchDeleted),且对于绝对阈值和相对阈值有不同的处理方式。
Case 1: both batchAdded and batchDeleted are false
Case 2: batchAdded is true and batchDeleted is false
Case 3: batchAdded is false and batchDeleted is true
Case 4: both batchAdded,batchDeleted are true
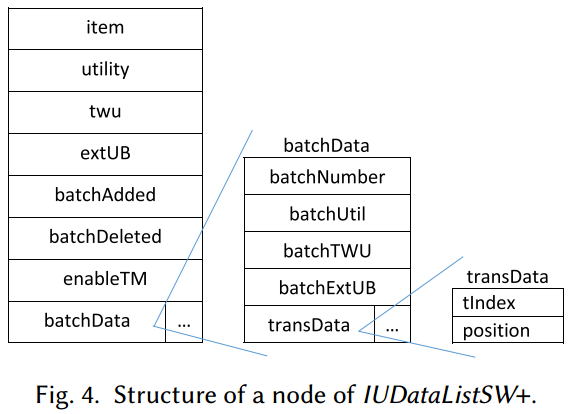

读取新批次,移除旧批次,更新IUDatalistSW+中的数据,筛选出所有 TWU ≥ δ 的项,组成 promisingItems 集合,TWU < δ 的项及其超集将被直接剪枝,对每个 promisingItems 中的项目 i:
- 如果 utility(i) ≥ δ,输出为 HUP。
- 如果 extUB(i) ≥ δ,调用 ExtendLevel1Node 扩展。

使用tIndex和position构建α-DB投影数据库,获取可扩展项集,根据节点中enableTM字段决定是否要进行事务合并,随后扫描α-DB计算u(α∪z)、extUB(α∪z)、lu(α,z):
- 如果 u(α∪z) ≥ δ,输出为 HUP。
- 如果 extUB(α∪z) ≥ δ,加入 Primary(α)。
- 如果 lu(α,z) ≥ δ,加入 Secondary(α)。
- 调用 SearchForExtension 递归扩展。

构建β-DB(扩展项集的投影数据库),secondary中获取可扩展项,在判断是否进行事务合并,扫描 β-DB,计算 u(β∪z)、extUB(β∪z)、lu(β,z):
- 如果 u(β∪z) ≥ δ,输出为 HUP。
- 更新 Primary(β) 和 Secondary(β),递归调用 SearchForExtension。
根据四个case对需要更新的节点调用算法2、3进行局部的挖掘、增量的挖掘,不用全局挖掘
四、实验
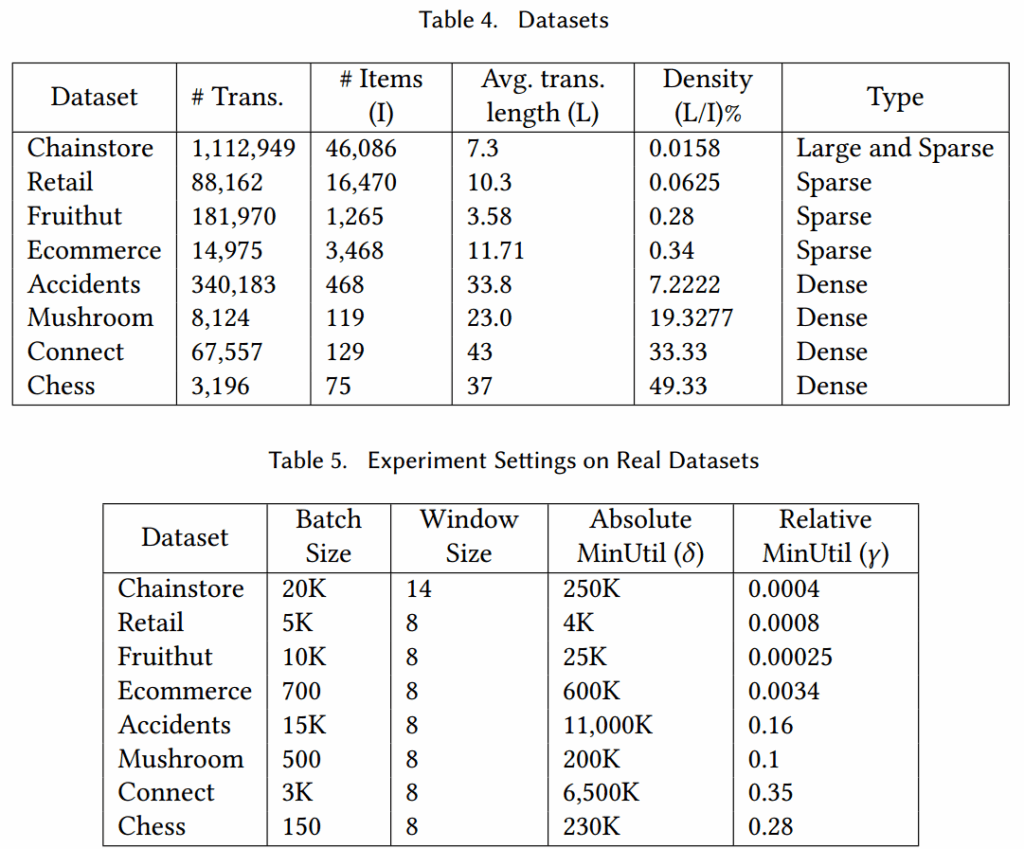
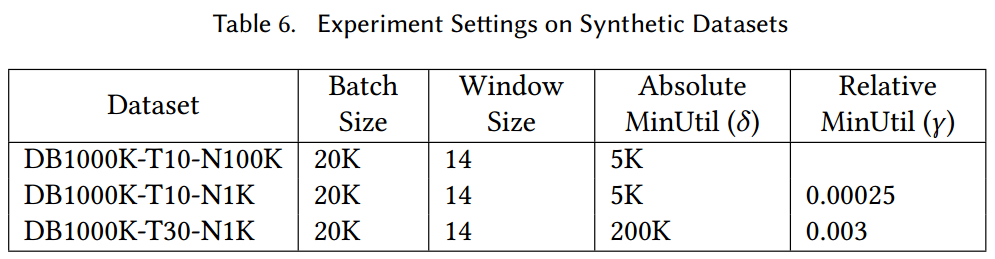
对SHUGrowth、HUPMS、HUPM_Stream、SOHUPDS、SOHUPDS+等算法在不同数据集内进行比较,以下是其真实数据集、合成数据集及其默认参数
五、实验结果
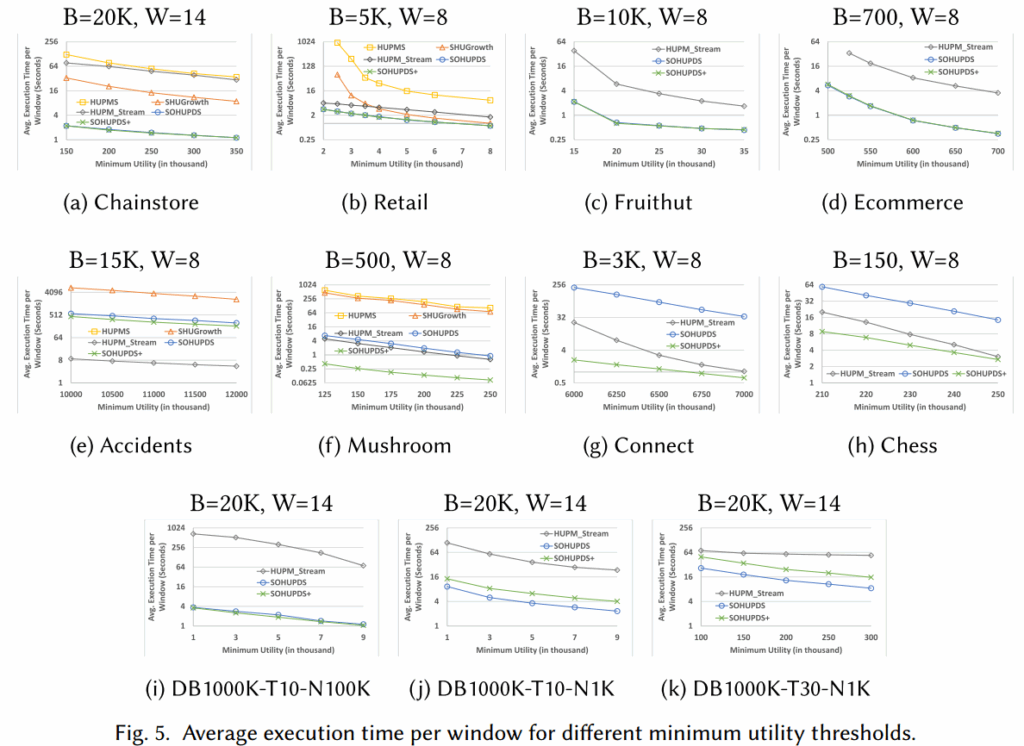
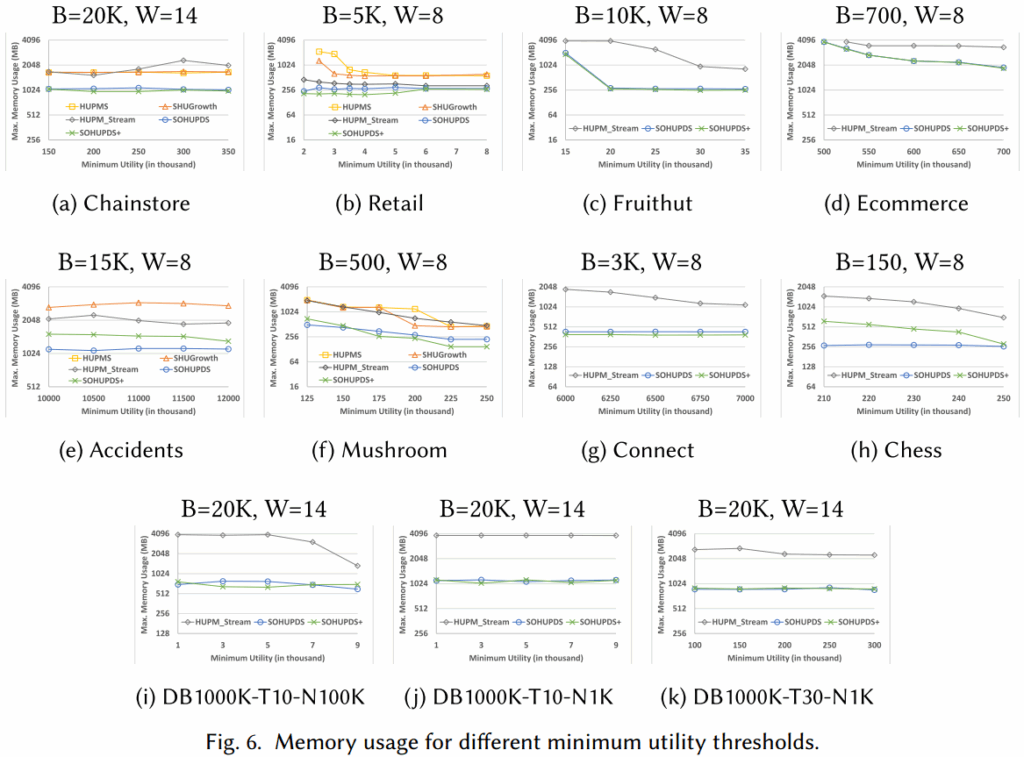
图5、6(绝对最小效用阈值)表明
- 执行时间:SOHUPDS+ 在大多数数据集上显著优于其他算法,在稀疏数据集中和SOHUPD中相似是因为无法从事务合并中获益,甚至可能产生额外开销,但在稠密数据集中其优势极其明显。唯一的例外是accident数据集,HUPM_Stream稍快,只能说明不同算法在不同特性数据上各有优势,但SOHUPDS+的综合优势更明显。
- 内存使用:SOHUPDS/SOHUPDS+的内存消耗始终最少,SOHUPDS/SOHUPDS+通过直接计算真实效用值以及紧致的上界,避免了候选集爆炸的情况,且SOHUPDS+虽然增加了位图结构,但其计算效率远超其内存开销
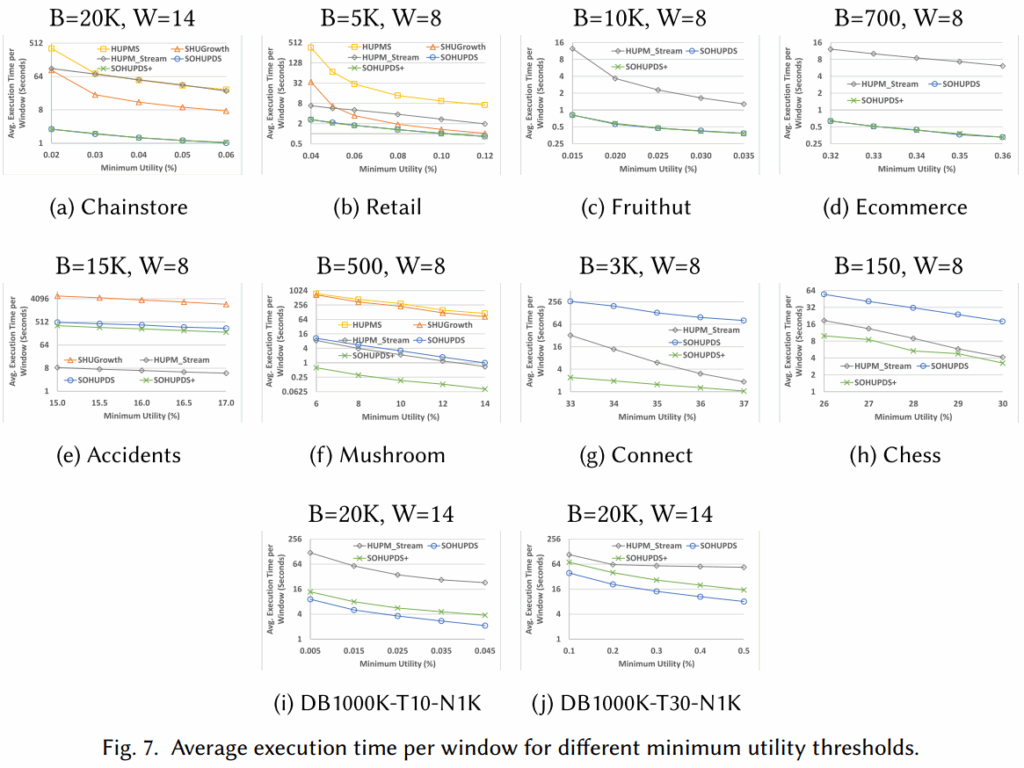
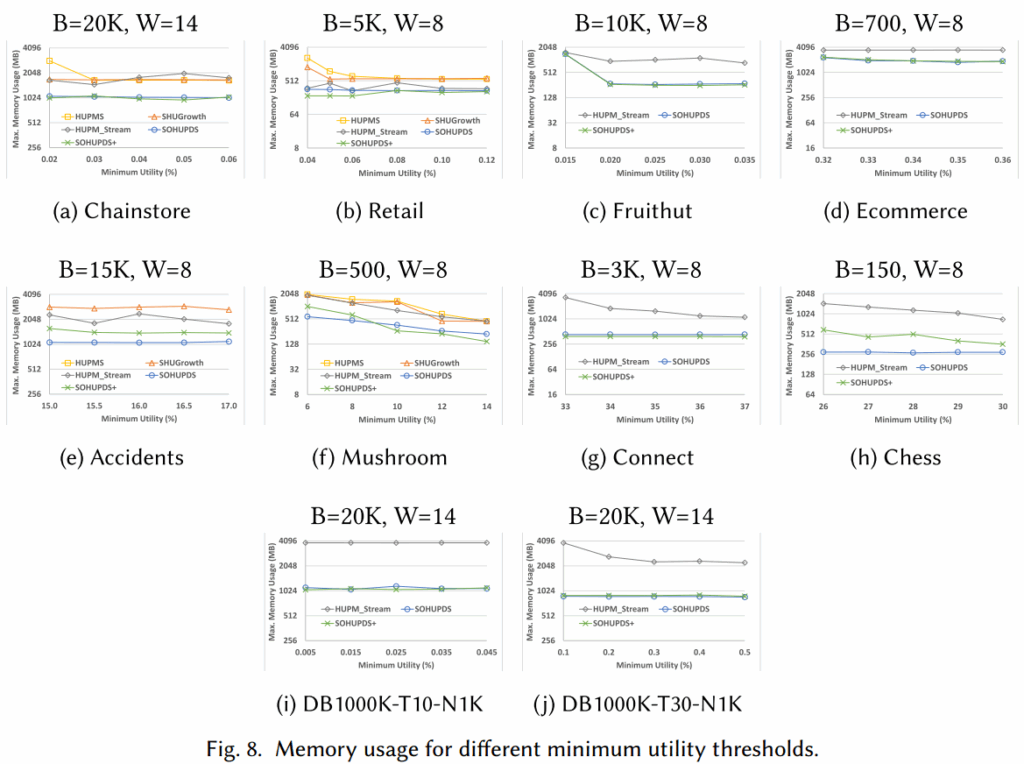
图7、8(相对最小效用阈值)表明趋势与绝对阈值完全一致,证明了SOHUPDS+的通用性,不仅适用于固定的绝对阈值,也能高效处理随窗口动态变化的相对阈值。
还有一些其他方面的比较,如不同批次大小的影响、不同滑动窗口大小的影响等,SOHUPDS/SOHUPDS+依旧保持领先。
在模拟长期运行环境(更小的批次、更大的窗口)下,SOHUPDS/SOHUPDS+ 在所有大窗口设置下都能稳定运行,并保持了显著的性能优势,且在稠密数据集上SOHUPDS+ 相对于 SOHUPDS 的加速比进一步扩大到 20x 以上,再次证明了 BitmapTransactionMerging 在处理大规模稠密数据时的威力。
六、结果
- 单阶段挖掘:避免了生成和存储大量候选集,从根本上解决了两阶段算法的内存和计算瓶颈。这是其内存效率高和在稀疏数据集上表现优异的主要原因。
- 高效的更新策略:通过 batchAdded 和 batchDeleted 标志位,智能地复用前一个窗口的挖掘结果,避免了每次窗口滑动都从头开始计算。这是其可扩展性好,尤其在窗口变大时优势更明显的原因。
- BitmapTransactionMerging 策略:专门针对稠密数据集优化,通过合并相似事务,极大压缩了投影数据库的规模。这是 SOHUPDS+ 在稠密数据集上产生数量级性能提升的直接原因。
- 紧致的效用上界(extUB, lu):在挖掘过程中使用了比TWU更紧致的上界进行剪枝,有效缩减了搜索空间,提升了挖掘效率。