作者:Zhifeng Kong,Wei Ping,Jiaji Huang
来源:ICLR 2021
单位:University of California, San Diego
时间:2021年5月
背景
在语音合成领域,深度生成模型已经能够合成高保真语音。早期的主流方法包括自回归模型(Autoregressive Models),如 WaveNet,能逐点生成波形,但速度极慢;流模型(Flow-based Models),如 WaveFlow,能并行生成,但结构复杂、参数量大;VAE模型(Variational Autoencoder),但生成语音的细节质量较低。这些模型普遍存在训练困难、推理慢或音质差的问题。扩散模型最早应用于图像生成,通过“逐步去噪”的方式将随机噪声转化为真实样本。这篇文章首次将这一思想引入语音领域,提出了一种非自回归、可并行、高保真的语音生成模型。
主要贡献
1.提出首个扩散模型的语音生成框架(DiffWave):能实现非自回归、并行的波形合成。兼顾有条件与无条件语音生成,在无条件语音生成与类别条件生成任务中,DiffWave 的音质与样本多样性均显著超越 WaveGAN 与 WaveNet。
2.提出了基于前馈式双向扩张卷积的音频生成架构,灵感来源于 WaveNet,但非自回归。在语音质量上与 WaveNet 持平,却能以极高速度生成长音频,只需极少的反向扩散步骤。
3.轻量化与高保真并存,尽管速度略慢于部分流模型,但模型参数更小、计算效率更高,未来仍具优化潜力。
技术方法
1.总体思想
DiffWave 的核心是一个基于 Markov 链的扩散—反向扩散过程:
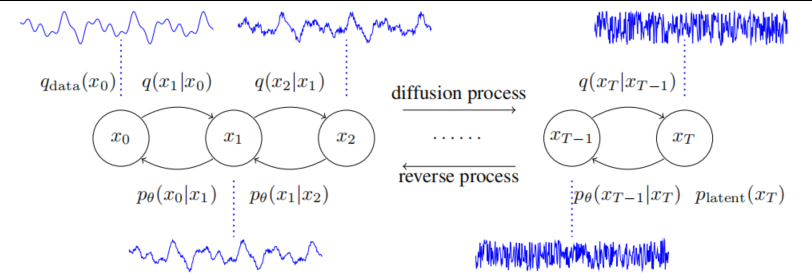
扩散过程(Diffusion Process):
从真实语音数据 x0开始,逐步加入高斯噪声,得到一系列中间状态 x1,x2,…,xT,最终变为白噪声。
反向过程(Reverse Process):
模型学习如何逐步去噪,从随机噪声 xT 逐步还原出结构化的音频波形 x0。每一步反向生成过程由神经网络ϵθ(xt,t) 预测噪声分量。
2.网络结构

DiffWave 的网络结构采用一种非自回归的前馈式卷积框架,由多层双向扩张卷积构成的残差堆叠组成,每层包含门控激活、残差连接与跳跃连接,从而在保证稳定训练的同时融合多层特征。
与WaveNet不同,DiffWave取消了因果约束,使模型能够同时利用前后时序信息,在并行条件下生成整段波形。
模型通过正弦-余弦时间步嵌入(timestep embedding)感知不同扩散阶段的特征,并可根据任务类型引入mel频谱(局部条件)或类别嵌入(全局条件)作为生成引导。整体结构轻量高效,仅需少量参数即可生成22.05 kHz高保真语音,兼顾音质与推理速度,展现了扩散模型在音频建模中的优越性。
实验分析
作者设计了三类实验任务,以验证 DiffWave 模型在不同音频生成场景下的性能与通用性。
1.条件语音生成
数据集:LJSpeech 数据集包含单一女声朗读 13,100 段短语音,时长约 24 小时。

实验结果表明,DiffWave 在音质上与 WaveNet 几乎持平,但推理速度提升了上百倍。DiffWave的参数量更小,仅为 WaveGlow 的 1/30。在未进行 CUDA 内核优化的情况下即可超实时生成,显示出极强的计算效率。
2.无条件语音生成
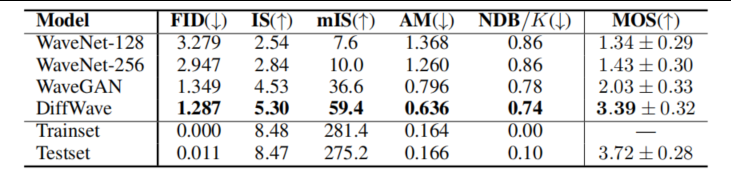
DiffWave 在完全无条件情况下仍能生成自然度较高的语音波形,显著超越 WaveGAN 与 WaveNet,证明其强大的概率建模能力。
3.类别条件语音生成

DiffWave 在类别条件任务中生成的语音不仅音质自然,而且类别辨识度更高,说明其在有条件生成中的一致性与可控性优异。
总结
DiffWave 展示了扩散模型在语音生成领域的强大潜力,充分证明了其方法在生成质量与计算效率上的突破性优势。它不仅能实现高保真、高速度的语音合成,并且在无条件和类别条件生成任务中,模型生成的语音不仅自然流畅,而且样本多样性更高。总体而言,DiffWave 不仅证明了扩散模型在连续时间信号建模中的可行性与优越性,也为后续语音扩散模型奠定了理论与方法基础,开启了高保真、高效率、可控语音生成的新方向。