作者:Aneesa Bashir, Rong Peng, Yongchang Ding
单位:Wuhan University
来源:ScienceDirect, Data & Knowledge Engineering
时间:2025.5
一. 研究背景
这篇论文的研究背景源于一个核心矛盾:目前拥有强大的知识图谱(结构化知识)和强大的大语言模型(语言理解),但缺乏一座有效的桥梁来连接两者,以解决专业领域中需要复杂逻辑推理的问答问题。
现有方法无法有效融合LLMs的感知能力与符号逻辑的推理能力,导致在关键应用场景下表现不佳。这为本论文提出的“将LLM与逻辑编程(Prolog)集成”的创新方案提供了坚实的动机和研究起点。
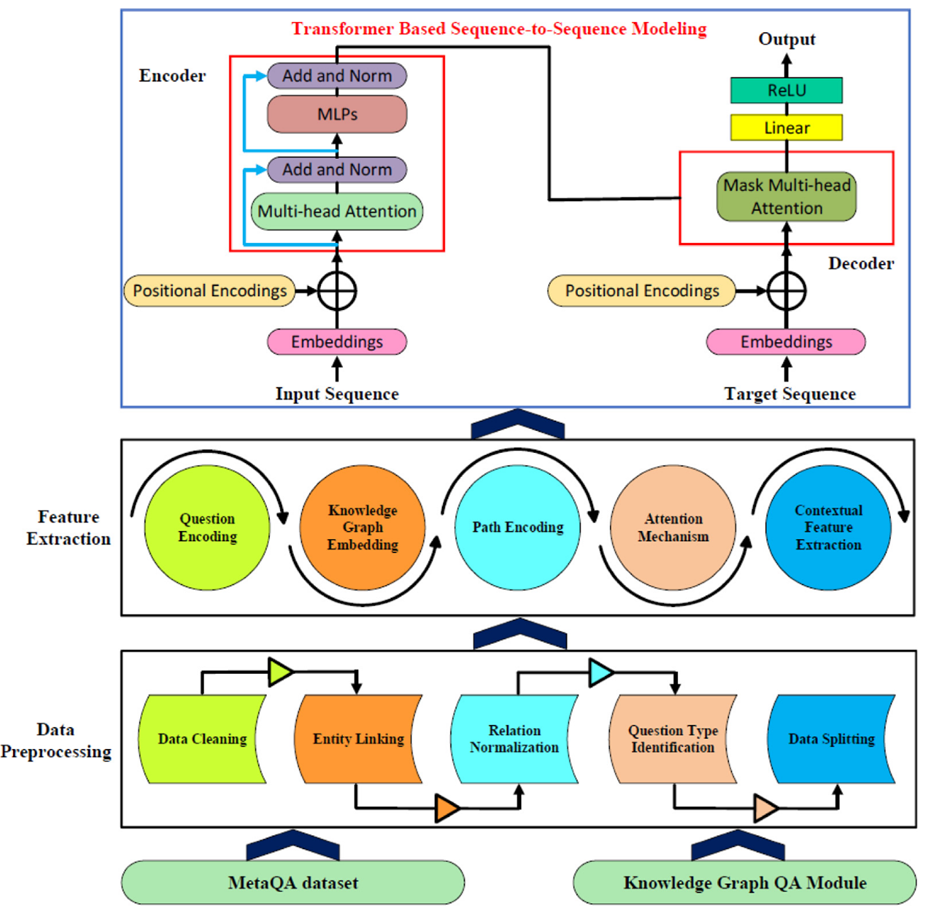
- Data Preprocessing:将原始问答数据(MetaQA 数据集)转化为模型可理解的形式,特别是去除人工标记模式、增强模型的实体识别与泛化能力。
- Feature Extraction & Encoder:特征提取的核心任务是将预处理后的文本和图结构数据,转化为富含语义信息的数值向量嵌入。让模型同时理解“问题语义”和“知识图谱结构”,为后续逻辑生成提供可计算的特征。
- Grammar-Guided Decoding + Prolog Execution:将自然语言问题转化为可解释、可执行的逻辑查询(Prolog Query),并通过逻辑推理从知识图谱中获取答案。
本文的方法创新点主要在于:
- 范式创新:将符号逻辑编程与 Transformer 相结合,属于典型的 Neuro-Symbolic QA 框架。
- 可解释性提升:输出的 Prolog 查询形式让每一步推理可追踪、可验证。
- 低样本优势:逻辑规则可迁移,不依赖大规模标注问答对,在小样本下依然有效。
- 面向专业领域:面向食品、医疗、金融、法律等需要逻辑一致性与结果可追溯性的应用场景。
二. 论文概要
本文提出了名为BERTlex-QA的创新框架,把Prolog逻辑编程融入Transformer编码–解码架构,通过集成逻辑编程语言增强大语言模型在专业领域知识图谱问答中的能力。
整个方法流程可以概括为三个核心模块:
· Data Preprocessing
· Feature Extraction & Encoder
· Grammar-Guided Decoding + Prolog Execution
三. 核心思想
注意力机制与稀疏激活(Attention Mechanism with ReLU Activation):模型使用改进的注意力机制,通过 ReLU 激活函数 替代传统的 softmax,使注意力权重稀疏化,从而增强解释性与计算效率。

多头注意力机制(Multi-Head Attention):将 Q、K、V 划分为 h 个子空间(heads),实现并行注意力计算,增强模型捕获不同语义特征的能力。
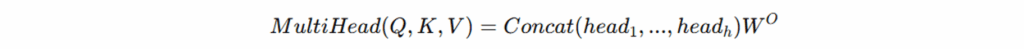
其中:
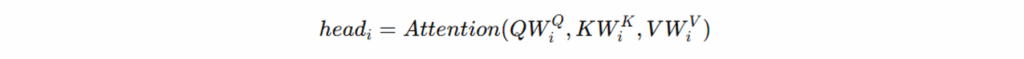
掩码多头注意力(Masked Multi-Head Attention):在解码阶段引入掩码矩阵(Mask),仅关注与当前生成相关的输入,防止信息泄漏。
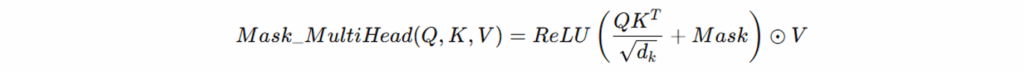
嵌入与位置编码(Embedding & Positional Encoding):输入词经过词向量与位置编码组合,使模型能捕捉顺序语义;同时加入 知识图谱特定嵌入(KG-specific embeddings),以对齐实体和关系的结构信息。
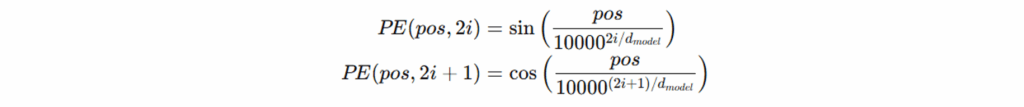
前馈神经网络(Feed-Forward Network, FFNN):每个 Transformer 层后接一个两层前馈网络:
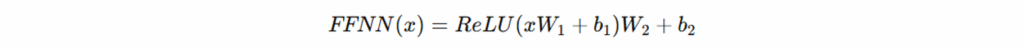
双损失函数设计(Dual Loss Optimization):
命名实体识别损失(NER Loss)用于衡量实体标签预测与真实标签之间的差异;本质为负对数似然(交叉熵损失)。
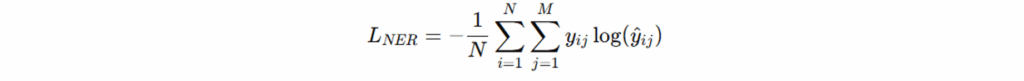
知识图谱问答损失(KGQA Loss)评估预测答案实体 𝑝𝑖 与真实答案的匹配程度;保证逻辑推理与答案生成的准确性。
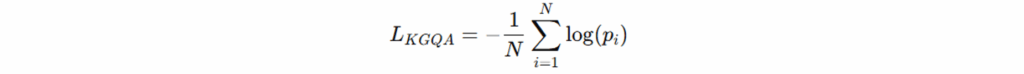
总损失为:
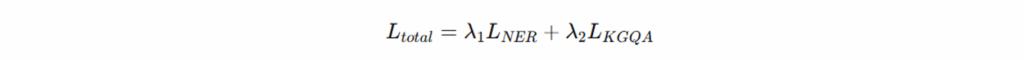
四. 实验结果
Accuracy指标使用MetaQA数据集评估了每个模型变体的性能。表7展示了所有训练数据规模的综合结果。性能下降的计算公式如下:

BERTLex-QA中模块消融在不同样本量下的性能指标准确性对比。

五. 对齐思考
- 这篇论文仍凸显了LLMs的强大,并将其定位为卓越的 “语义理解前端” 。它重新激活了Prolog的价值,将其作为严谨的 “逻辑推理后端” 。体现了AI从单一技术路线走向融合发展的新阶段。
- 具备高可解释性是当前LLM应用的最大障碍之一,尤其是在食品、医疗等风险领域。本文方法通过生成人类可读的Prolog查询,将LLM的“黑箱”推理过程完全透明化。用户不仅能得到答案,还能审查得到答案的每一步逻辑。
- 多模态融合的延伸:论文专注于文本知识图谱,但其核心思想具有极强的扩展性。未来的知识图谱必然是多模态的,包含图像、音频、视频等。可以设想一个“视觉-逻辑增强”的KGQA系统:LLM理解包含图像的问题,生成一个包含视觉操作(如“检测图像中的食品配料表”)和逻辑推理的混合查询,从而实现更强大的跨模态推理能力。