作者:Yuxin Wen Neel Jain John Kirchenbauer等
单位:University of Maryland, New York University
来源:NeurIPS
时间:2023
研究背景与动机
硬提示(Hard Prompts):由人类手工设计的、可解释的、离散的文本词元序列(如“a photo of a cat”),优点是可读、可迁移、可复用,但发现高质量提示依赖专家经验或试错,效率低。
软提示(Soft Prompts):连续的嵌入向量(embedding),可通过梯度优化自动学习,性能强,但不可读、不可迁移、无法用于API接口。
尽管软提示在优化上更高效,但其不可解释性和不可移植性限制了其在实际应用中的广泛使用。因此,如何结合两者的优点——自动学习 + 可解释 + 可迁移——成为关键问题。
提出一种高效、自动化的方法,通过基于梯度的离散优化技术,自动生成高质量的硬提示(human-readable text prompts),用于文本到图像和文本到文本任务。
如何在离散的文本空间中进行高效的梯度优化?(传统梯度方法适用于连续空间)
如何让自动学习的提示既性能强又可解释、可迁移?
PEZ (Pronounced “easy”):一种简单高效的基于梯度的离散提示优化算法。
核心思想:
在连续空间中进行梯度优化(像软提示一样训练),
但在每次前向传播时,将连续嵌入投影到最近的真实词嵌入上(实现离散化),
最终输出的是真实的、可读的文本 token 序列。
这借鉴了量化神经网络训练中的“重投影”(re-projection)策略,避免了传统离散优化中梯度不可导的问题。

优化对象:可学习的连续嵌入 P
初始化:
从词表嵌入矩阵 E中随机选择 M 个真实词的嵌入,作为初始 P。
最终投影:
优化结束后,对最终的 P 做一次投影,得到最优的离散提示 P ∗。
将 P∗转换为对应的 token 序列,即为可读、可迁移的硬提示。

1、前向投影:将当前连续嵌入P投影到最近的真实词嵌入,得到离散提示 P ′,此时P′ 对应一个真实的、可读的 token 序列,这一步确保模型输入是真实的文本 token,而不是软嵌入。
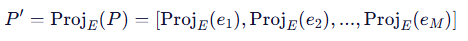
2、前向传播 & 损失计算:使用P′ 作为提示,输入到冻结模型 θ 中,计算任务损失 L。
3、反向传播 & 梯度计算:计算损失对投影后嵌入P′的梯度。虽然 P′ 是离散的,但由于它是从 P 投影而来,且投影是可微近似(通过最近邻查找),梯度可以回传到 P
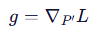
4、在连续空间更新 P:使用梯度 g 更新原始的连续嵌入 P,而不是 P′
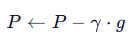
重复以上步骤直至收敛,模型逐渐学习到一个能最小化损失的嵌入序列P。
实验
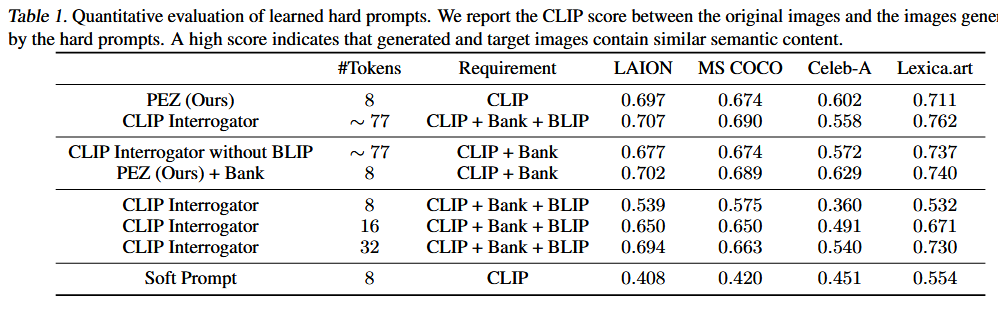
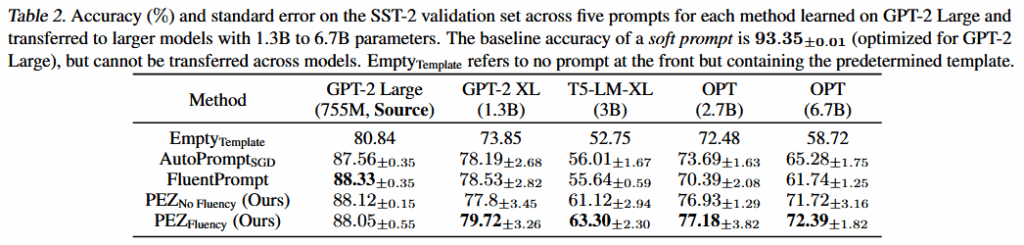
核心内容总结
核心内容总结:
1.结合硬提示和软提示优化方法各自的优点,提出连续-离散混合优化方法PEZ。维护一个连续的 soft prompt作为优化变量,但每次前向都用离散的 hard prompt计算损失和梯度。
2.设计一个投影函数(Proj_E)将每个嵌入向量映射到词表中最相似的真实词嵌入(最近邻),利用投影函数得到的自然语言提示词,增强可解释性。
3.使用的梯度回传机制中,梯度从离散的 P′P′ 计算,但更新的是连续的 PP,避免了“梯度消失”问题。
4.无需额外采样或搜索,不像 AutoPrompt 需要枚举候选 token,PEZ 只需一次前向和一次反向,效率高。