作者:George Hannah, Jacopo de Berardinis, Terry R. Payne等
来源:arXiv:2507.03829v1
单位:University of Liverpool、Unilever Plc
发表日期:2025.7
一、论文介绍
实验室自动化加速了科学实验的数据生成,但大量实验数据以 XML 形式存储,仅具结构化语法,缺乏可供推理的语义信息。
不同实验室和系统间的 数据语义不一致,使得实验结果难以共享、整合或构建统一的知识图谱
传统由领域专家手工完成的本体构建过程 耗时、昂贵且易受主观影响,限制了科学数据的语义化与自动化发展。
旨在提出一种融合规则与大语言模型(LLM)的混合框架 RELRaE,通过四阶段流程实现从 XML 模式到本体结构的自动化转换。该框架依次完成关系抽取、标签生成、标签精修与自动评估,既利用规则保持结构一致性,又借助 LLM 提升语义准确性,并引入“LLM-as-a-Judge”机制减少人工验证负担,从而实现高质量、低成本的半自动本体生成过程。
二、核心内容
关系抽取
目标:从 XML Schema 中识别候选概念对及其层级关系,为后续关系标注奠定结构基础。
主要方法:
输入:XML Schema 文件(包含元素、属性、类型定义等)。
解析层级结构,抽取候选概念对(如父子节点、属性隶属关系)。
捕捉直接关系(Parent–Child)与间接关系(祖孙、属性链)。
提取关联的文本注释(Annotation),为后续 LLM 精修提供语义上下文。
规则标注
目标:利用结构模式规则为每个关系对生成初步的语义标签,构建原始的知识三元组。
主要方法:
基于 Bohring & Auer (2005) 的 XML→OWL 映射思想,定义 结构-关系模板。
不同类型的节点组合对应不同标签形式:ComplexType → SimpleType → has<Property> ComplexType → Attribute(boolean) → is<Property> 同类型结构继承 → subClassOf
若无匹配规则,采用默认命名规则:前缀“has + Range 名称”。
模块称为 RuBREx(Rules-Based Relationship Extraction)。
标签精修
目标:利用大语言模型优化初步标签的语义准确性,使关系名称更符合领域知识与上下文。
主要方法:
使用 LLM(如 GPT-4)对规则生成的标签进行语义判断与修正。
构造“角色 + 领域 + 任务”式提示语:
示例:“你是一位分析化学专家,请判断标签‘hasComponent’是否准确描述给定关系,如不合适请改进。”
融入 few-shot 提示策略,提供领域示例提升一致性。
在部分实验中添加文档注释(documentation)增强语义上下文。
自动评估
目标:通过第二个 LLM 自动评估生成标签的合理性,减少人工验证成本。
主要方法:
采用另一模型(如 Gemini)执行 “LLM-as-a-Judge” 任务。
对每个关系标签打分(Likert 五级尺度:No→Yes)。
设置接受标准:
“Likely (4)” 或 “Yes (5)” → 标签通过;
低于标准 → 回退至规则标签。
少量真实标签用于训练验证器,平衡人工成本与效果。
三、实验评估
四、总结思考
论文总结
核心方法:提出混合式的 RELRaE 框架,将规则系统与 LLM 语义理解结合,用于从 XML Schema 自动生成关系标签与基础本体。
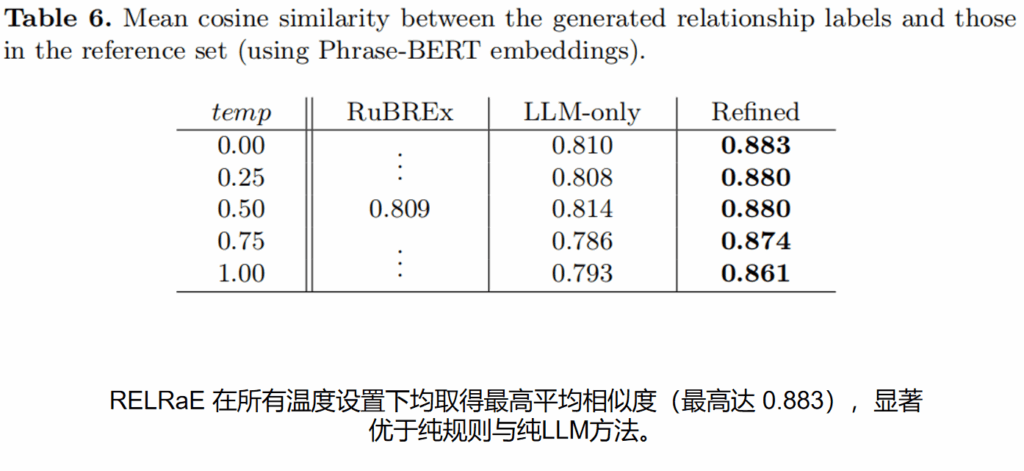
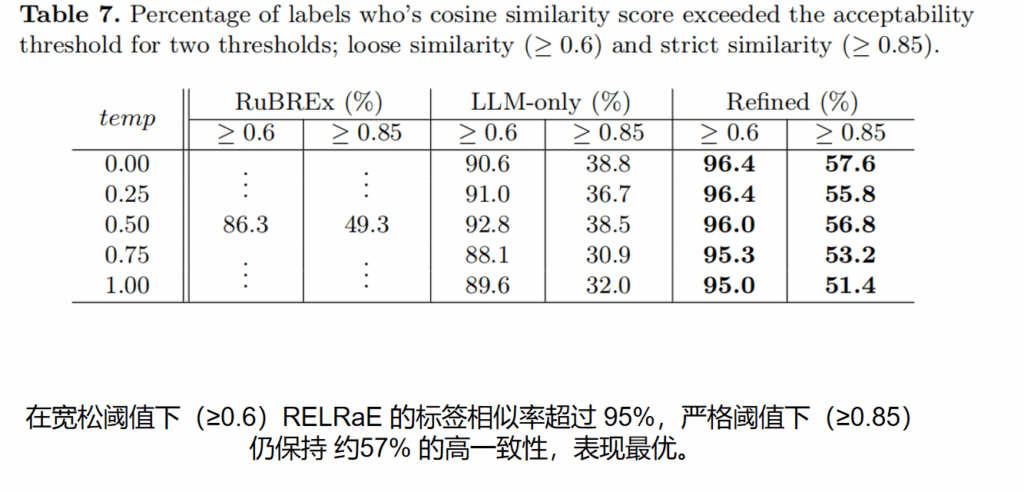
实验结果:RELRaE 在标签准确性上显著优于纯规则或纯LLM方案;LLM评审机制可替代部分专家审核工作。
优势总结:
显著降低人工参与成本
保留专家方法的结构化可控性
提高标签的语义一致性与质量
LLM-as-a-Judge 提供高效质量控制手段
启发思考
1.“LLM抽取 + LLM 精修 + LLM 评审” 的三阶段流程,可推广到 知识抽取、自动标注、RAG数据构建 等场景;
2.可借鉴其 LLM 解释性评估机制,在我方知识库建设中引入“自动预标注 + 轻量验证器 + 人工复审”的高质量管控模式;
3.后续研究可尝试让 LLM 直接参与 语义关系发现与本体扩展,实现更智能的知识结构生成。