来源:WIREs Data Mining and Knowledge Discovery
作者:Payel Santra等
单位:Indian Association for the Cultivation of Science,University of Glasgow,Jadavpur University
发表时间:2025年4月
一、研究背景
随着各类自然语言处理任务对大语言模型的依赖越来越大,对于优化标记数据和非标记数据的使用以生成有效的上下文信息至关重要,其中有上下文学习(ICL)和检索增强生成(RAG)两种较为突出的方法,但都有各自的局限。上下文学习利用来自训练集的少量标记对来生成模型,但无法更新模型的内在知识,导致了“模型不会答”;而检索增强生成利用外部知识库的原始数据生成模型,模型不知检测到的文档是否正确,导致了“模型只会答”。
二、核心内容
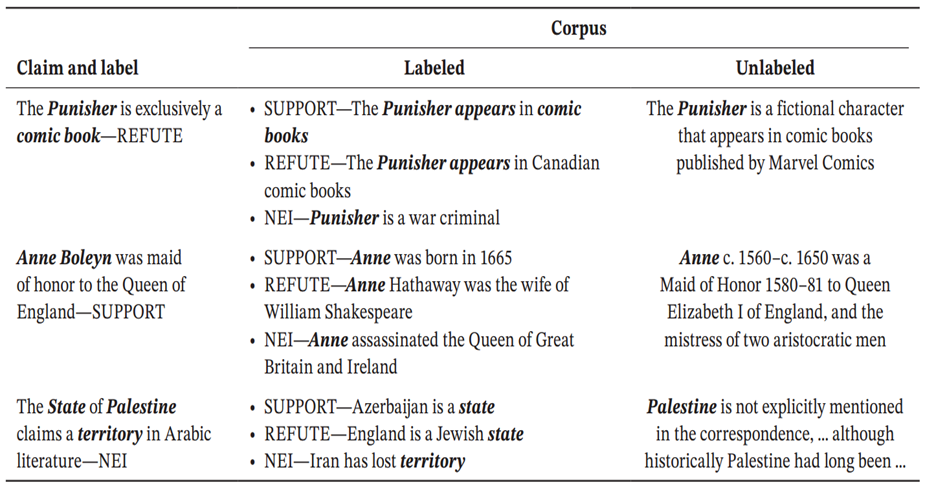
文章提出了一种新方法(LU-RAG),其动态整合已标记的数据和未标记的数据来生成有效的上下文,以提高LLMs的应用性能。
- 重新计算前k个标记实例和前m个未标记段落的得分,以改进上下文选择
- L-RAG:结合相似标记数据与问题,作为实例提示给LLMs
- U-RAG:检索出问题相关证据段落,作为上下文提示给LLMs
- LU-RAG:使用单独的超参数来控制输入到LLMs的信息量,k控制实例数量,m控制证据数量,而使用α和M控制两种方法以不同比例组合(k=(1-α)M, m=αM)
三、方法
- 从标记训练集中检索top-k个相似样本,从外部知识库中检索top-m个相关段落,使用超参数α和M来控制两类上下文比重
- 使两类上下文经过两阶段的检索,第一阶段(稀疏检索)快速从大量文本中检索出与输入有关的候选集;第二阶段(稠密重排列)采用预训练好的稠密检索模型对候选集进行语义重排序,保留最相关的部分
- 通过计算输入文本和每个上下文的密集向量嵌入之间的余弦相似度,最后根据计算得出的余弦相似度对检索到的文件排序
- 将检索到的标注实例与未标注的证据组合成一个结构化的提示(指令、标注实例、未标注证据、测试样本),输入给LLM进行训练
四、实验
数据集:
FEVER(约18.5万个声明,用于事实验证)
SST2(约11k个句子,用于情感分类)
对比实验:
对数据集的处理方法:Zero-shot,仅提供任务指令和带预测的输入;L-RAG,仅使用从训练集中检索到的标注示例;U-RAG,仅使用从维基百科中检索到的未标注证据;LU-RAG,融合L-RAG和U-RAG,设置α为0.5;LU-RAG-GS,在验证集上对超参数 α 进行网格搜索,找到最优值后再在测试集上评估
模型:直接使用LLaMA-2进行测试;使用RoBERTa在各自数据集上进行全量微调;使用LoRA技术对LLaMA-2进行高效微调
检索方法:S,静态选择;LEX,仅使用稀疏检索器BM25;SEM,使用BM25进行初筛,再用稠密检索器进行语义重排序
五、实验结果
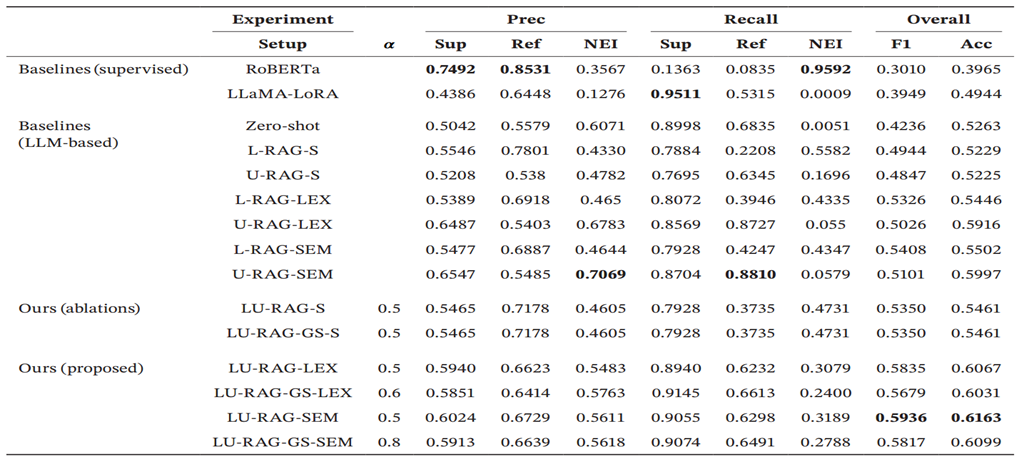
- LU-RAG能够有效地利用标记和未标记的数据,从而实现更好的检索,更强的知识基础和增强的上下文利用
- 先进行稀疏检索再进行稠密检索比单单进行稀疏检索效果好
- 监督学习方法(RoBERTa, LLaMA-LoRA)在“证据不足”类别上表现极差,而LLM-based方法(特别是LU-RAG)能更好地处理这类模糊情况
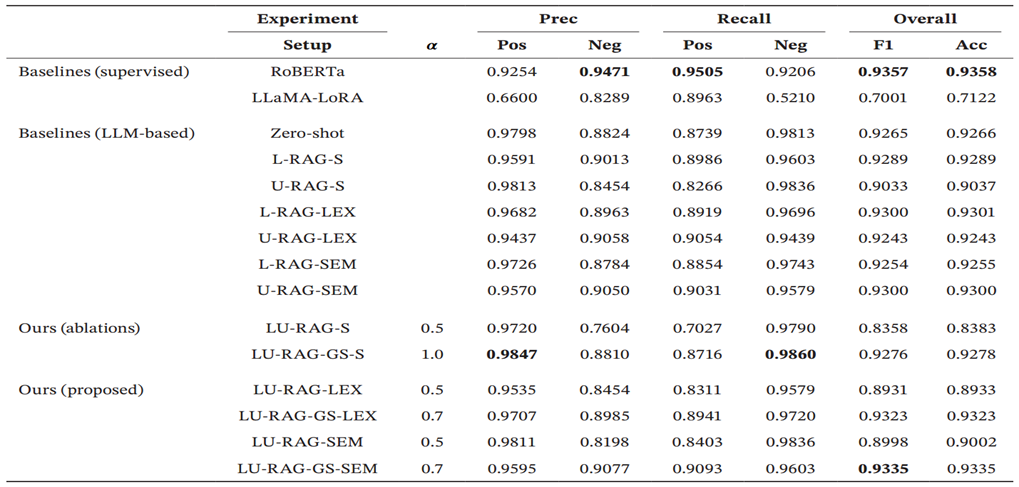
- 情感分类的这种表现表明,外部背景的结合有助于模型解释细微的情感
- 网格搜索并非总是有效,在事实验证任务上α=0.5效果最好;在情感分类里α=0.7则能带来小幅度提升
六、额外的探究
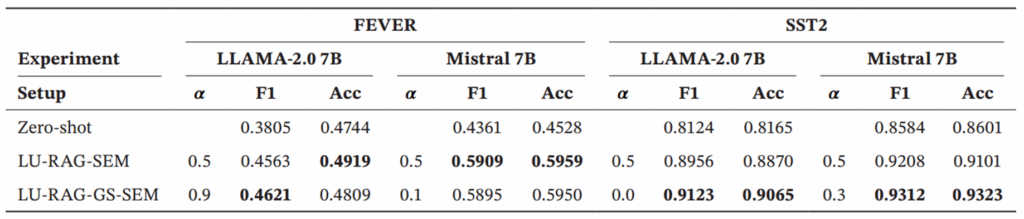
1.进行消融实验,评估不同模型架构之间改进的一致性
结果表明了LU-RAG-SEM方法始终优于Zero-shot基准线,确保了混合框架的通用性;对于不同方法在LLAMA-2.0 7B上评分高低可知,不同方法对检索到的上下文权重不一样;数据还表明LU-RAG-GS-SEM进一步优化了检索平衡
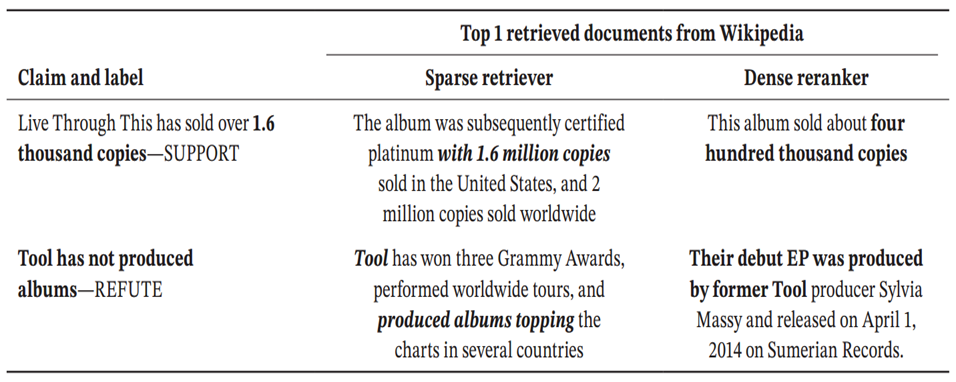
2.错误分析
错误预测主要是由检索错位和证据不足造成的,可能会检索到事实错误或误导性的证据;检索质量的提高,仍未能消除误导性证据带来的歧义,可能不同数据源之间有冲突,亦或是其中一个数据源的质量太差
七、总结
- 贡献:提出了一种新型的基于融合的方法,根据超参数α将训练集的标记实例与外部文档的未标记数据结合,同时利用多阶段排名器为LLM收集更多相关的上下文
- 局限性:虽然提高了检索质量,但仍然未能消除误导性证据的歧义
- 未来方向:希望能自适应调整标记数据和未标记数据的比例;利用图推理或强化学习,进行更深刻更高效的检索与整合进一步增强模型的性能