- 作者:Xu D, Li X, Zhang Z 等
- 发表单位:中国科技大学、香港城市大学、腾讯、北京大学
- 发表在:AAAI 2025
核心内容
- 大语言模型(LLM)虽然具备强大的问答与知识综合能力,但其内部知识更新成本高昂,容易随时间推移产生过时信息,进而引发“机器幻觉”。为解决这一问题,研究者引入知识图谱(KG)作为外部知识源以提升回答的可靠性与可解释性。然而,现有的基于知识图谱的问答(KGQA)方法,尤其是那些依赖证据检索与上下文插入的策略,往往面临证据不完整或不相关的问题,限制了其实际效果;
- AMAR(Adaptive Multi-Aspect Retrieval)通过多角度证据抽取(实体、关系、子图)与自适应融合机制,显著提升了知识图谱证据的质量与相关性。其核心创新在于引入自对齐与相关性门控机制,能够有效识别并加权高相关性证据,减少噪声干扰。该方法兼具灵活性与可训练性,支持多角度证据互补,且在效率上优于传统的符号推理方法,尤其适合需要高精度与可解释性的问答场景;
- 在 WebQSP 和 CWQ 两个标准数据集上,AMAR 在 HR@n、Acc、F1 等五个关键指标上均取得了当前最优(SOTA)性能,显著超越了基于提示词工程和传统检索增强方法的基线模型。实验结果表明,AMAR 不仅能有效缓解知识图谱证据中的噪声问题,还能显著提升问答系统的整体准确性与鲁棒性。
背景
- 大语言模型的问答能力以及对内部知识的综合运用能力极强,但是大模型内部知识更新成本极高;随着时间推移,这些过时的知识就会对大语言模型生成答案的质量产生极大的影响,这被认为是机器幻觉的源头之一;
- 为了解决这样的问题,人们引入了知识图谱来辅助大语言模型生成可靠的答案;知识图谱的知识易于更新,从知识图谱中检索证据支持大语言模型的方法可以极大地提高 LLM 回答的可解释性;当下 KGQA 的方法大致可以分为两类:将输入问题转化为结构化查询语句(Cypher、SPARQL 等)或从 KG 中检索出一组证据插入到上下文中辅助 LLM 进行回答;后者往往面临抽取的证据不完整、不相关的问题;
- 为了解决这样的问题,作者提出了这个名为 AMAR (Adaptive Multi-Aspect Retrieval augmented over KG)的方法。AMAR 包含一个可以识别多角度证据和问题之间相关性的网络,可以有效应对 KG 中抽取的不完整、不相关证据,减轻噪音。实验表明这个 AMAR 在 2 个数据集的 5 个指标上获得了 SOTA 表现。
方法论
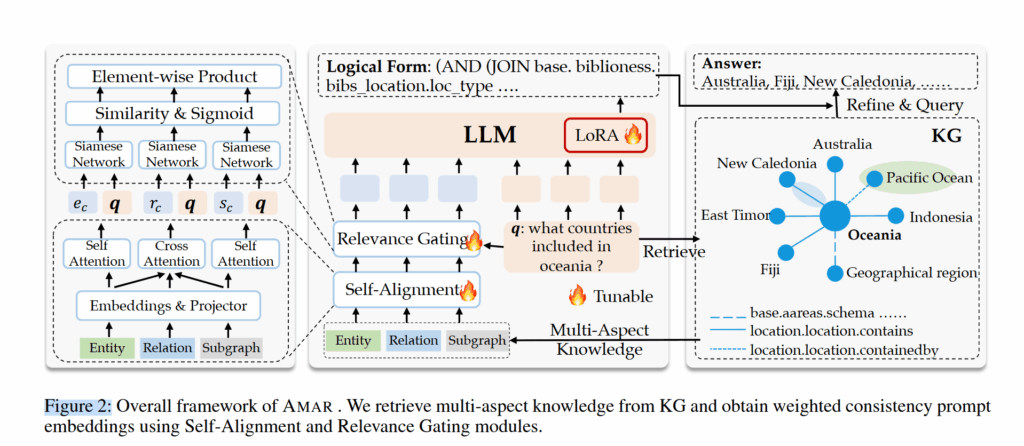
多角度知识的抽取
作者将 KG 中抽取的实体、关系和子图视作三个角度的证据,各个角度之间存在共性并且同时起到互相补充的作用。因此这里的实体、关系、子图三方面证据是分开抽取的。
- 实体检索:ELQ+FACC1 做补充
- 关系检索:训练一个 BERT 模型,学习掩盖了 mention 的 $q$ 和 relation 之间的关系,然后用这个模型进行 dense 检索以获取关系
- 子图检索:获取每个实体周围 1-hop 范围组成子图,每个子图都被转化为一个自然语言文档,这样就完成了图谱的扁平化;接着作者使用 BM25 这样的方法检索这些子图文档
这样的做法把 KG 检索的问题完全变成了向量检索的问题。
自对齐
作者从知识抽取过程中抽取出了三方面的知识 $S,E,R$,它们各自是一组文本。接着它们会被词嵌入编码为一组矩阵 $X_{s},X_{e},X_{r}\in \mathbb{R}^{t_{k}\times l\times e}$,其中 $t_{k}$ 是文本数量;$l$ 是文本最大长度;$e$ 是嵌入向量长度。在这里,每个文本都是一个 $l\times e$ 的矩阵。
然后作者希望每个文本变成一个向量,于是取了所有 token 向量的均值。这是一种平均池化的做法参见汇聚层(池化层):
$$
X=\frac{1}{l}\sum_{i=1}^lX[:,i,:]\in \mathbb{R}^{t_{k}\times e}
$$
这种做法相对于 BERT 来说略显粗糙。
接着,三个方面 $X_{s},X_{e},X_{r}$ 会经过一轮投影 $\mathcal{M}(\cdot)$ ,之后 $X_{e},X_{r}$ 计算自注意力 Self Attention。这个自注意力是各个文本之间的自注意力,不是 Decoder Only 和 Transformer 架构中同一文本各个 token 之间的自注意力。
$$
\begin{cases}
\mathbf{e}{c}=\text{self-attn}(X{e}) \
\mathbf{r}{c}=\text{self-attn}(X{r})
\end{cases}
$$
自注意力不改变矩阵尺寸和意义,所以出来之后仍然是一样的。然后作者拿它们和子图计算 Transformer 中那样的交叉注意力:
$$
\begin{cases}
\mathbf{s}{c}^e=\text{cross-attn}(X{s},X_{e},X_{e}) \
\mathbf{s}{c}^r=\text{cross-attn}(X{s},X_{r},X_{r}) \
\mathbf{s}{c}=\mathbf{s}{c}^e+\mathbf{s}_{c}^r
\end{cases}
$$
相关性门控
$q$ 被词嵌入编码之后变为矩阵 $X_{q}\in \mathbb{R}^{l\times e}$,它和 $\mathbf{e}{c},\mathbf{r}{c},\mathbf{s}{c}$ 列维度相同。将它们通过同样的 MLP 处理之后,让 $q$ 每个token 的嵌入和每条实体、关系或子图证据计算相似度。这样可以得到三个相似度矩阵: $$ \begin{cases} \mathbf{q}{m}=\mathcal{M}{share}(X{q}) \in \mathbb{R}^{l\times e}\
\mathbf{e}{m}=\mathcal{M}{share}(\mathbf{e}{c}) \in \mathbb{R}^{t{k}\times e}\
\mathbf{r}{m}=\mathcal{M}{share}(\mathbf{r}{c}) \in \mathbb{R}^{t{k}\times e}\
\mathbf{s}{m}=\mathcal{M}{share}(\mathbf{s}{c}) \in \mathbb{R}^{t{k}\times e}\
G_{sim}^j=\mathbf{j}{m}\mathbf{q}{m}^T\in \mathbb{R}^{t_{k}\times l}, & j\in { e,r,s }
\end{cases}
$$
将 q 所有 token 和每条证据之间的相似度取均值,得到 q 和每条证据之间的相似度:
$$
\mathbf{g}{j}=Sigmoid\left( \frac{1}{l}\sum{i=1}^l G_{sim}^j[:,i] \right)\in \mathbb{R}^{t_{k}},j\in { e,r,s }
$$
将注意力重新赋权到相似度这里,相似度高且注意力集中的证据会脱颖而出:
$$
\begin{cases}
\mathbf{e}{c}^w=\mathbf{g}{e}\circ \mathbf{e}{c}\ \mathbf{r}{c}^w=\mathbf{g}{r}\circ \mathbf{r}{c}\
\mathbf{s}{c}^w=\mathbf{g}{s}\circ \mathbf{s}{c}\ \end{cases} $$ 最后,这些 token 被放在 $q$ 之前拼接起来,输入给大模型: $$ \mathcal{F}=f{\theta,\phi_{1},\phi_{2}}([\mathbf{p};\mathbf{e}{c}^w;\mathbf{r}{c}^w;\mathbf{s}{c}^w;X{q}])
$$
其中 $\phi_{1},\phi_{2}$ 是 LoRA 参数。
执行查询
虽然作者前面想了很多方法搞实体和关系的匹配检索,但是因为其又用了 dense 的方法处理这些检索出来的数据,因此生成的查询 $\mathcal{F}$ 又可能有不存在的实体以及关系了。为了解决这个问题,作者又训练了一个 SimCSE 模型计算查询 $\mathcal{F}$ 和各个实体之间的相似度,然后取出最高相似度的一组实体 $\mathcal{E}{sub}$。这组实体周围 2 步范围内的关系被纳入关系匹配的范围,又用同样的做法 dense 匹配。匹配完毕之后就可以查询了: $$ a=\text{query}(\text{convert}(\mathcal{F}{new}))
$$
实验
数据集是 WebQSP、CWQ;Metric 是 HR@n、Acc、F1。这些都是 KGQA 的经典配置。
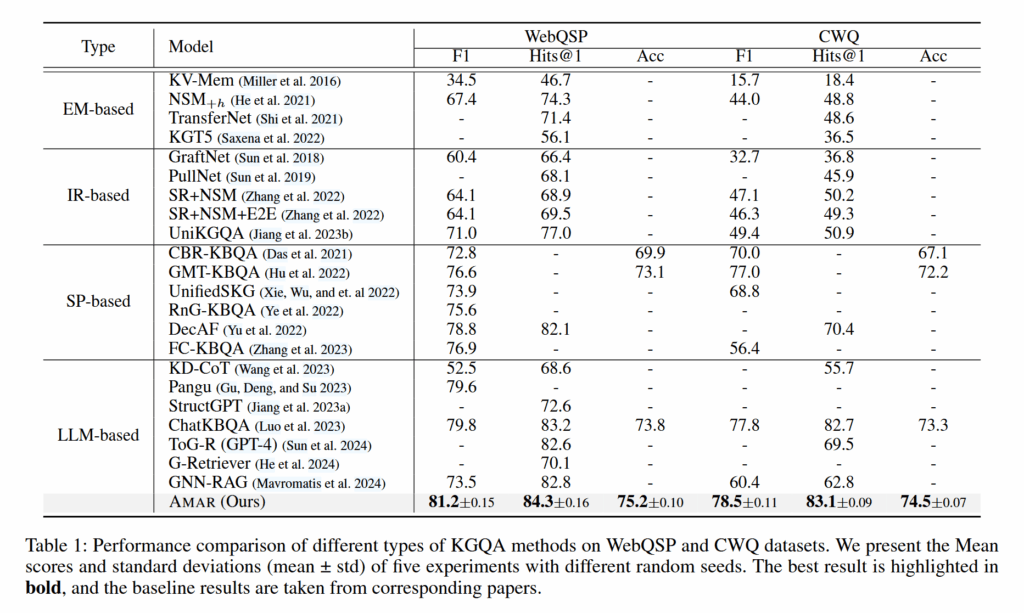

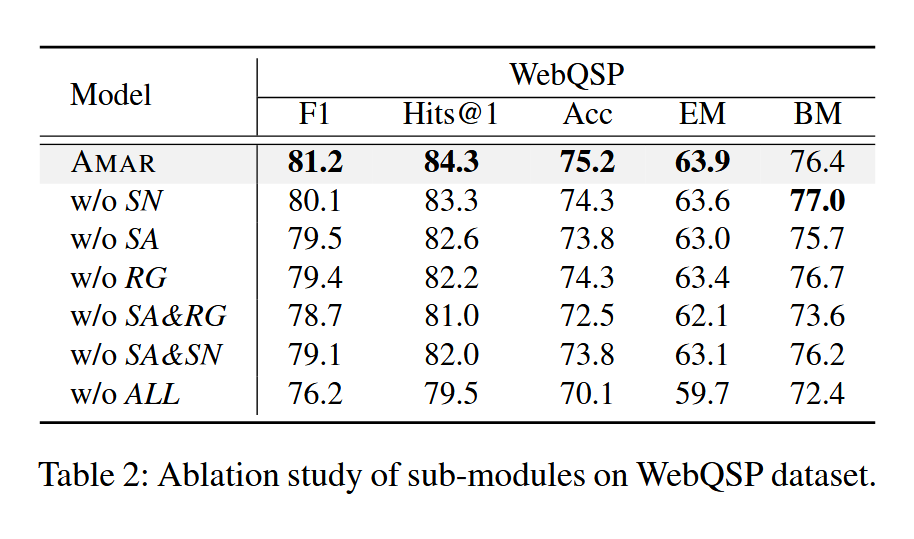
结论
- 作者提出了一个模型,将 KG 中抽取的信息转化为了向量中间表示,并且通过对齐和门控识别了有用和无用信息;
- 实验表明,这样的方法比单纯的提示词工程效果要好,在多个 benchmark 上有较大的提升;
启发与评价
- 这个方法用交叉注意力+相似度匹配有效地识别了哪些证据有用、哪些证据没用以及哪些证据相关性高、哪些证据相关性低。这是一种非常灵活多变的方法,可以根据具体的场景专门训练,获得逻辑模型往往无法获得的效果;
- 这一套结构虽然会大大增加模型的复杂性,尤其是交叉注意力的架构会使得全模型无法使用流水线并行的方式拓展;但是相比起需要多次调用大模型的符号框架,这套方法的速度会快许多;而且其大规模使用双编码器的架构也能大大节省算力;
- 不过由于这套框架将符号进行匹配、编码之后又变回符号,导致最开始 ELQ 的努力付诸东流了,最后还是要重新做实体和关系的匹配;我认为这是一个设计缺陷;
- 为了解决这一故障,我们能不能将大模型和 AMAR 解耦开来,将它单纯训练为一个证据选择模型呢?