作者:Md Messal Monem Miah, Adrita Anika , Xi Shi, Ruihong Huang
来源:ACL 2025
单位:Texas A&M University,Amazon
发表日期:2025.8
背景
欺骗检测意义重大但本质困难,人类判别准确率仅略高于随机猜测(约 54%)。研究者试图用语言学特征、音频特征、面部微表情等自动化线索来辅助判别。
近年 LLM 在语言理解、情感/事实验证等任务上显示强大能力;LMM也在理解音/视频和文本等方面崛起。本文系统评估了不同类型模型在多模态欺骗检测任务中的性能。
论文贡献
1、首次系统性研究大语言模型与多模态大模型在欺骗检测中的表现,涵盖文本数据集(OpSpam)、实验室环境视频数据集(MU3D)、以及真实法庭审讯数据集(RLTD)。
2、比较了传统深度学习基线(如RoBERTa、CNN、LSTM)、开源LLM(LLaMA、Gemma)、商用LLM(GPT-4o)、以及多模态模型(GPT-4o多模态、LLaVA等)的性能,形成一个较为全面的评估。
3、探索了不同实验设置,包括:直接标签预测与事后推理生成、随机与相似性示例选择、few-shot 与 zero-shot 提示,以及是否使用思维链提示。
4、发现并揭示了当前模型的短板:LMM 在捕捉视频里的细粒度非语言特征时表现不佳,甚至不如传统的视觉神经网络。
实验过程
1、数据集:
| 数据集 | 类型 | 内容 | 标签 |
| RLTD | 庭审视频 | 121个视频 | 有罪/无罪 |
| MU3D | 人际对话 | 320个视频 | 喜欢/不喜欢 |
| OpSpam | 在线评论 | 1600条酒店评论 | 欺骗/真实 |
2、评估模型:
文本LLMs:LLaMA3.1-8B, Gemma2-9B, GPT-4o
多模态LMMs:
视频+文本:LLaVA-NeXT-Video, Qwen2VL
音频+文本:MERaLiON-AudioLLM, Qwen2-Audio
3、实验设置
基线模型:RoBERTa(文本)、BiLSTM+Attention、CNN、PECL(多模态)
提示策略:
· 零样本 vs 少样本(2/4/6/8/10个样本),在少样本情况下尝试不同示例选择方法(随机 vs 相似度检索)。
· 直接输出标签 vs 先生成标签再生成推理,检测模型是否有可解释性
辅助特征:
非语言手势(RLTD)
视频摘要(LLaVA生成)
音频摘要(Qwen2-Audio生成)
微调:使用LLaMA-Factory对模型进行微调
实验结果
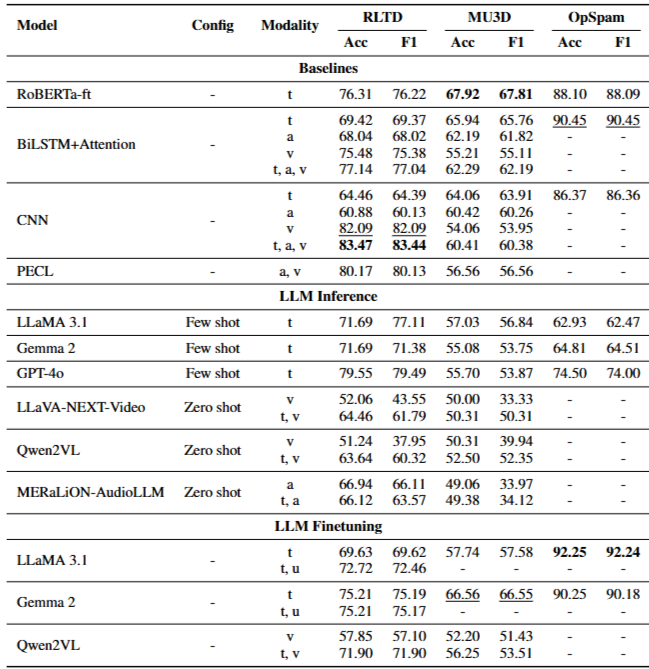
主要性能对比
文本数据集OpSpam:LLM的表现接近或超过RoBERTa,说明大模型在单文本欺骗检测上具有竞争力。
实验室视频数据集MU3D和真实法庭数据集RLTD:LLM单文本模式能部分缩小与基线的差距,但few-shot配置并未始终优于最强基线。
多模态大模型(LMM)未能展现出在视频欺骗检测中的优势,尤其在非语言细节捕捉上表现不如传统CNN或时序模型。
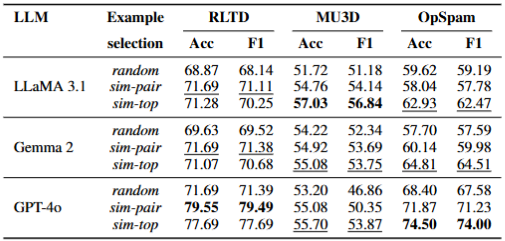
sim-top(选最相似的,不管标签)和 sim-pair(平衡选相似的真实和欺骗样本)均优于随机选择。
在OpSpam中,sim-top效果更好,因为欺骗性评论之间语义相似度高,容易检索到同类样本。
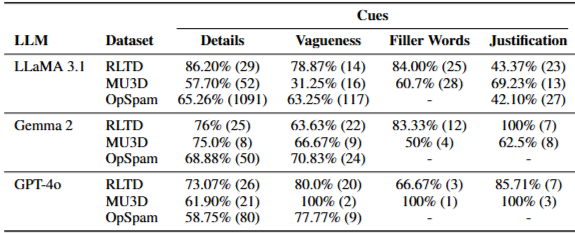
LLMs在判断欺骗时依赖以下语言线索
| 线索 | 说明 | 准确率 |
| 细节性 | 详细描述常被认为是真实 | 57%~86% |
| 模糊性 | 模糊表达常被认为是欺骗 | 31%~100% |
| 填充词 | “um”、“uh”等常被认为是欺骗 | 50%~100% |
| 合理性 | 过度解释常被认为是欺骗 | 42%~100% |
| 情绪 | 强烈情绪常被认为是真实 | 但易被夸大情绪欺骗 |
总结
1、主要结论
LLMs在文本欺骗检测上表现出色,尤其是在微调后;
当前多模态LMMs在欺骗检测中尚未能有效利用视觉和音频信息;
LLMs容易过度依赖某些语言线索(如细节、模糊性),导致误判;
少样本示例的选择策略对性能影响显著,相似性检索优于随机选择。
2、局限性
仅限英文数据,缺乏跨语言/文化评估;
未涵盖AI生成欺骗内容;
伦理和隐私问题未深入讨论。
3、未来方向
开发更高效的多模态欺骗检测模型;
提升LMMs的时序感知能力;
结合人类反馈进行可解释性优化。