来源:arXiv
时间:2024
单位:IDEA-Research
一、背景
随着开放世界视觉任务需求的增长,如自动驾驶、机器人导航和智能安防等现实应用,系统需具备识别任意类别、处理复杂场景、支持多模态输入的能力。当前主流的三种方法分别为:
- 统一模型(Unified Models):如 UNINEXT、OFA,通过训练单个模型来应对多种任务,但存在数据分布受限、分割能力薄弱的问题;
- LLM控制器方法(LLM as Controller):如 Visual ChatGPT、HuggingGPT,通过语言大模型调度视觉模块,但推理效率低,依赖性强;
- 基础模型组装(Ensemble Foundation Models):将多个专家模型组合,模块化完成复杂任务,灵活性强。
该论文采用第三种策略,提出了一个名为 Grounded SAM 的系统,旨在解决开放词汇检测与分割等基础视觉任务,并拓展至密集标注、图像编辑和人体分析等复杂场景。
二、贡献
- 创新系统架构:提出 Grounded SAM,将 Grounding DINO(开放集检测)与 SAM(可提示分割)结合,构建可处理开放词汇分割的多模型组装管线。
- 模块化扩展能力:系统可无缝集成 RAM、BLIP、Stable Diffusion、OSX 等专家模型,支持图像标注、生成、编辑、三维人体动作分析等任务。
- 高效组合策略:避免使用 LLM 控制器,通过训练无关的模型组装完成复杂任务,具备较高推理效率与可解释性。
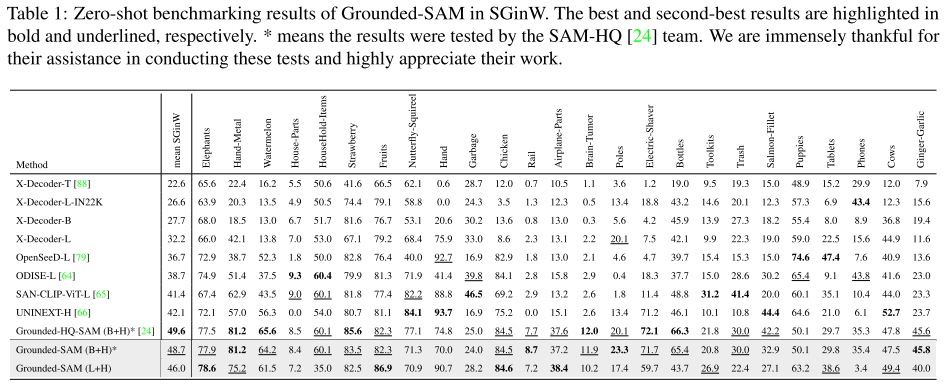
- 性能领先:在 Segmentation in the Wild (SGinW) 零样本评测中,Grounded SAM 超越了 UNINEXT、OpenSeeD 等主流方法,验证其实用性和强泛化性。

三、系统构建与场景应用
1. Grounded SAM 组成模块:
- Grounding DINO:开放词汇检测器,根据文本提示检测目标边界框。
- SAM:可提示的分割模型,接收边界框提示,输出目标掩码。
- RAM:强大的图像标签模型,识别图像中常见类别。
- BLIP:图文理解与生成模型,生成图像描述。
- Stable Diffusion:图像生成与修复模型,用于编辑、擦除等。
- OSX:全身网格恢复模型,实现精确三维人体分析。
2. 典型应用示例:
- 开放集检测与分割(Grounded SAM):将文本 → 框 → 掩码解耦,提升分割准确性与灵活性;
- 自动图像标注(RAM-Grounded-SAM):用 RAM 生成标签输入 DINO+SAM 实现图像全自动标注;
- 图像编辑(Grounded-SAM-SD):结合 Stable Diffusion 实现局部擦除、重绘、替换;
- 三维动作分析(Grounded-SAM-OSX):按文本提示定位特定人并进行网格恢复,进行实例化动作分析;
- 多模型联合拓展:与 FastSAM、HQ-SAM、LaMa、DEVA 等组合,加速推理、提升掩码质量或支持目标跟踪。
四、实验
- 评估平台:Segmentation in the Wild (SGinW),共包含 25 个零样本数据集;
- 评估任务:开放集目标检测 + 分割;
五、总结
- Grounded SAM 打破了单一模型或依赖语言模型调度的限制,以训练无关、模块化组装的方式应对开放世界视觉任务;
- 系统具备高度灵活性与可扩展性,适用于图像标注、编辑、人体分析等多个下游任务;
- 在公开基准测试中表现出领先性能,具备极强的实用价值和工程潜力。