来源: arXiv 2025-06-16
作者: Han Zhu等
单位: 小米
一、论文主要工作及贡献
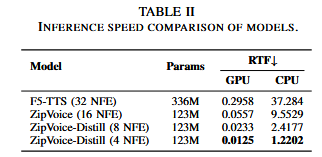
现有大规模零样本TTS模型由于大量参数导致推理速度缓慢。对此提出ZipVoice,1)使用基于Zipformer的流匹配解码器,在约束尺寸下保持足够的建模能力;2)基于平均上采样的语音文本对齐和基于Zipformer的文本编码器,提高语音清晰度;3)提出一种减少采样步骤并消除无分类器指导相关的推理开销的流蒸馏方法。在100k小时的多语言数据集上的实验表明,ZipVoice在比基于DiT的流匹配基线小3倍和快30倍小,保持相匹配的性能。
二、模型框架
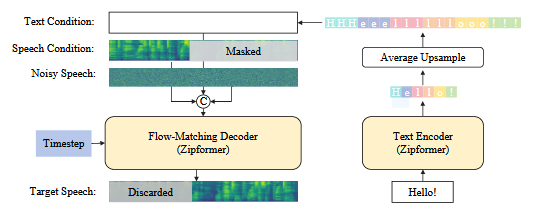
由文本编码器和流匹配解码器组成,均以Zipformer作为骨干网络。和Voicebox一样,采用语音填充任务来实现零样本的文本到语音合成能力。对语音特征采用二值掩蔽,m表示掩蔽位置。条件流匹配的优化目标可以表示为:
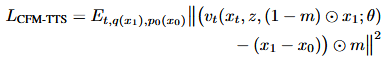
Zipformer是一种用于ASR的编码器结构,有三个关键设计:类U-Net框架,卷积模块和注意力复用机制。
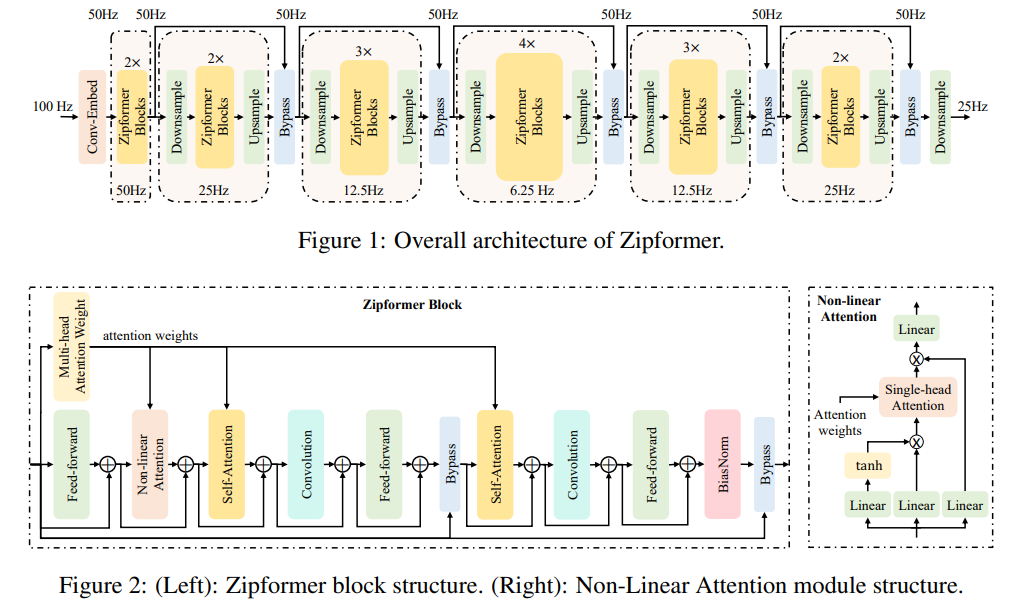
U-Net框架在不同分辨率下处理特征表示,在扩散模型中被认为是一种有效的归纳偏置。卷积神经网络可以捕获细粒度的局部特征模式,补充Transformer在建模长距离全局依赖性的强度。Zipformer通过在单层内复用两个自注意力模块和一个非线性注意力模块的权重来提高参数效率。
非自回归TTS模型的核心挑战在如何处理文本和语音特征之间的长度差异。传统方法是在训练过程中明确语音文本对齐(基于ASR的强制对齐或单调搜索对齐)以及持续时间预测模型,这使得训练复杂,并由于持续时间预测不准确导致语音自然性降低。ZipVoice采用无需参数的平均上采样策略,假设句子中所有标注的持续时间是均匀的,有N个文本标记和T帧语音特征时:
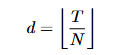
每个文本标记嵌入重复d次,得到扩展的文本特征作为流匹配的条件。
ZipVoice-Distill通过使用流蒸馏方法,蒸馏Zipvoice模型,使用教师模型的两步推理构建教师向量场,每个步骤都应用无分类器指导,学生模型预测该向量场,使得学生能够将教师模型的表现与少量的NFE匹配。
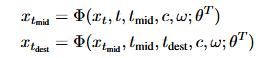
一步的ODE求解器定义为:
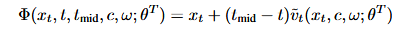
教师向量场为:
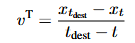
最后的流蒸馏损失为:
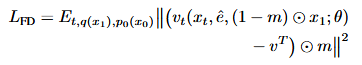
使用固定教室模型完成流蒸馏后,从最新的学生模型开始进行第二个蒸馏阶段。采用学生模型的指数移动平均版本:
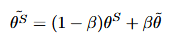
三、实验
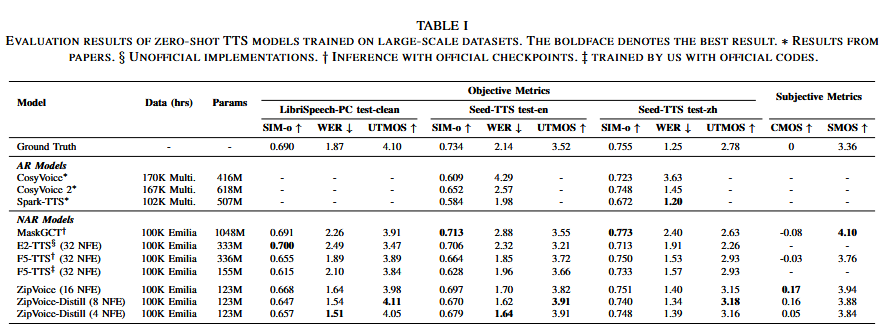
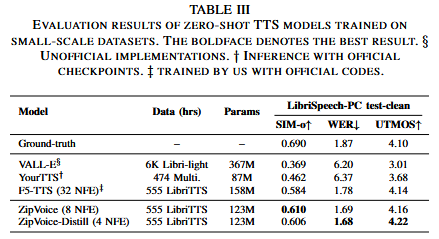
数据集:100k小时的Emilia,585小时的LibriTTS用于训练,在LibriSpeech-PC test-clean子集,Seed-TTS test-en和Seed-TTS test-zh用于验证。
客观指标:SIM-o评估说话人相似性,UTMOS评估自然度,WER评估可懂度。
主观指标:比较意见得分CMOS和相似性意见得分SMOS来评估合成语音的比较质量和说话人相似性。
基线模型:三个自回归模型(Cosyvoice,Cosyvoice2和Spark-TTS)和三个非自回归模型(MaskGCT,E2-TTS和F5-TTS)
四、实验结果
消融实验:
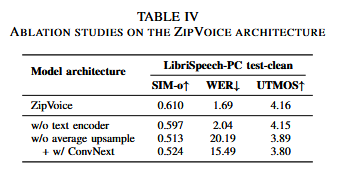
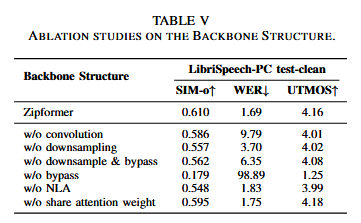
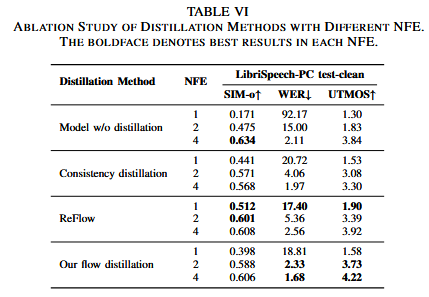
五、结论
这篇文章提出ZipVoice,快速和高质量的基于流匹配的零样本TTS模型,利用Zipformer作为主干网络,在保持强大的建模能力的同时,提高参数效率。
六、思考
- 将Zipformer框架用于L2S任务中,对于实现低复杂度L2S系统有借鉴价值。
- 流蒸馏方法在L2S系统中,可以在减小推理步数的同时保持性能。