作者:Xuan Long Do 等
单位:新加坡国立大学、香港科技大学、新加坡A*STAR
来源:ACL 2024 Long Paper
时间:202408
研究背景与动机
In-Context Learning (ICL) 让 LLM 能通过示例完成任务,但对 prompt 极度敏感。
• 现有优化方法依赖监督信号,优化目标单一、无对抗性,泛化性较弱。
• 本文动机:引入 adversarial learning(对抗博弈)优化提示,提升 ICL 表现。
adv-ICL 对抗性上下文学习
三模块博弈(Generator G,Discriminator D,Prompt Modifier M):
G 生成响应;D 判断是否为“真实”数据;M 修改 G/D 的 prompt 以提升对抗目标
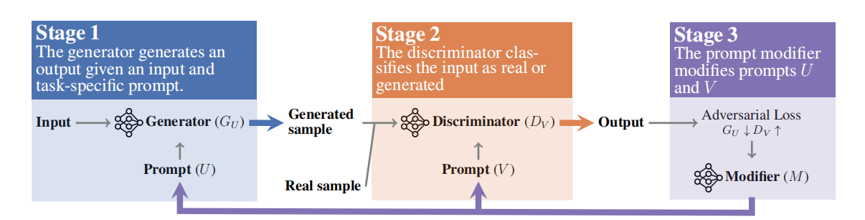
步骤 1:G 使用 prompt 生成输出
步骤 2:D 判别该输出是生成的还是人类样本
步骤 3:M 生成若干变体,选择能最优化 adversarial loss 的版本更新 G/D 的 prompt
• 全流程为最小化 G 生成的被识别概率 + 最大化 D 判别能力的对抗过程
生成器
初始 prompt U:
G 使用的 instruction + demonstrations
模型根据输入与prompt生成响应,生成器的输入输出对就是伪造样本对,将交给判别器进行判别。
目标是让判别器无法判别出这是模型生成的。
判别器
初始 prompt V:
D 使用的 instruction + (x, y, label) 示例

接收真实样本对和伪造样本对(生成器的输入与输出对)。
判别器针对这两类样本对给出二分类标签或者真假的概率。
目标是极大可能判断出伪造样本对。
修改器
并没有梯度,而是用 LLM 生成候选 prompt,通过“对抗损失”来选择哪一个更有效欺骗 D,从而间接优化 prompt。
对每个变体 prompt ,都放入 G 的 prompt → 运行 G + D ,计算 adversarial loss:
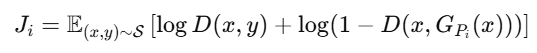
用loss排序,然后选取使Ji值最大的 prompt 作为新的 G/D prompt。
实验
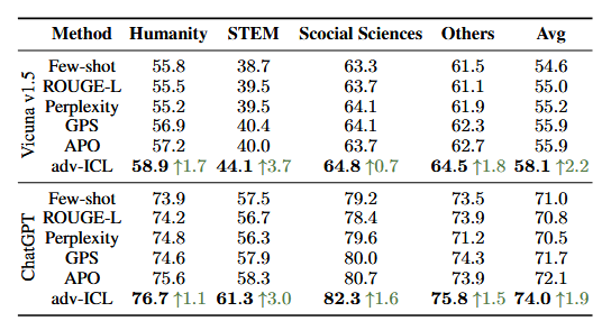
模型:ChatGPT, text-davinci-002, Vicuna-13B
• 数据集:13 个任务,含 GSM8K, MMLU, BBH, Yelp, WebNLG 等
• 提升显著:在 GSM8K 上提升 +2.4%;MMLU 提升 +3%;BBH 提升 +2.4%
• 少样本表现良好:每轮仅需 5 条样本,迭代 3 次即可优化
核心内容总结与思考
核心内容总结:
引入 adversarial loss 优化 discrete prompt 的方法。对抗机制实现无训练的 prompt 优化,适配任务广泛、效果稳定
适配开源/闭源 LLM,支持多种任务(生成、推理、分类)
方法在强泛化 prompt 生成上未验证,实际部署需要 prompt 解释控制。
思考:
依赖 M 能生成高质量 prompt 变体;D/G 需有合理模型能力匹配。
可以使用Discriminator 模块作为提示质量判别器提升 prompt 精度。