来源:arXiv
作者:Elahe Khatibi、Ziyu Wang、Amir M. Rahmani
单位:美国加州大学
发表时间: 2025年04月
一、论文介绍
背景:传统RAG靠语义相似检索,难以区分“相关”与“因果”,在多跳问答中常给出看似合理却缺失机制的幻觉答案。
核心:基于上述背景,论文提出了因果动态反馈的自适应检索增强生成框架CDF-RAG, 通过先构建经 GPT-4 校验的动态因果图,再用 PPO-RL 实时改写查询、沿图做多跳检索,最后用因果一致性分数触发重生成或知识重写,从而把“相关证据”升级为“可信因果链”。
二、RAG对比介绍
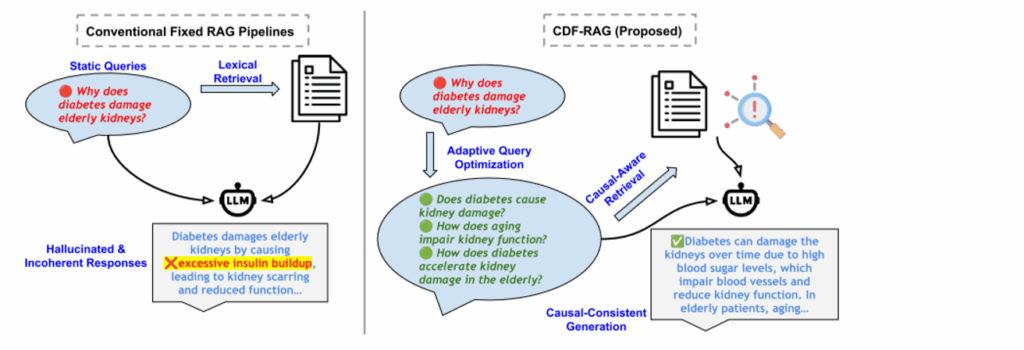
(a)传统的RAG管道依赖于静态查询和基于关键字或相似性的检索,通常检索主题相关但因果关系不相关的内容,这可能导致幻觉或不连贯的输出
(b)CDF-RAG通过基于强化学习的查询细化、结合语义向量搜索和因果图遍历的双路径检索以及因果一致性生成来解决这些限制,从而提高了真实性和推理能力。
三、CDF-RAG框架
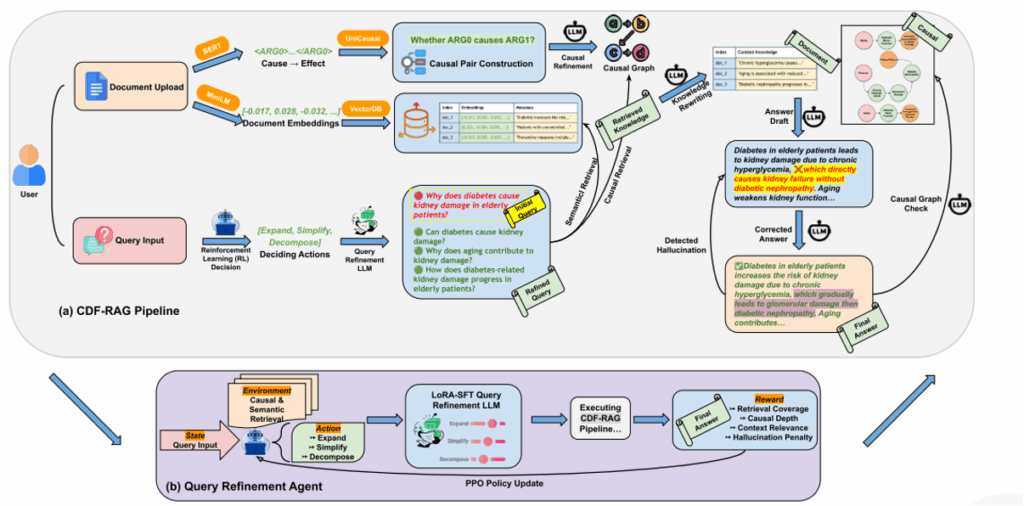
(a)CDF-RAG管道细化用户查询(LLM + RL),检索结构化因果和非结构化文本知识,应用知识重写,并通过因果验证确保事实一致性。
(b)PPO训练的查询细化代理优化检索覆盖率和因果一致性。
四、实验
准确率实验
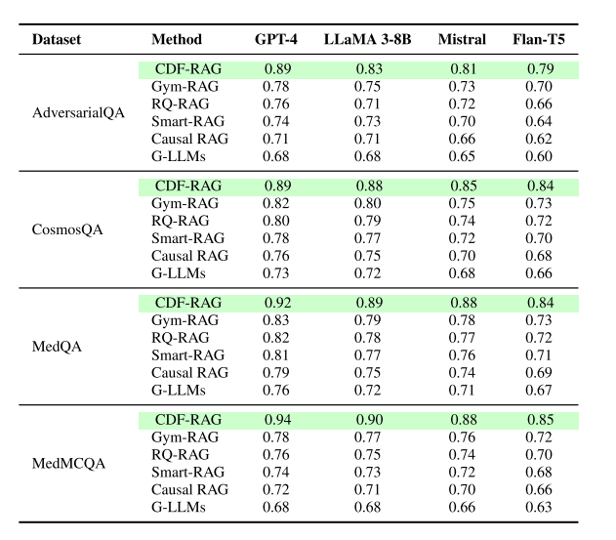
目的:验证 CDF-RAG 在常识、对抗、医学等多场景问答中是否全面优于基线。
方法:用 GPT-4/LLaMA-3-8B 等 4 种模型,在 CosmosQA、AdversarialQA、MedQA、MedMCQA 上对比标准 RAG、Gym-RAG 等 6 条基线,以 Accuracy、F1 为主指标。
检索与对齐实验
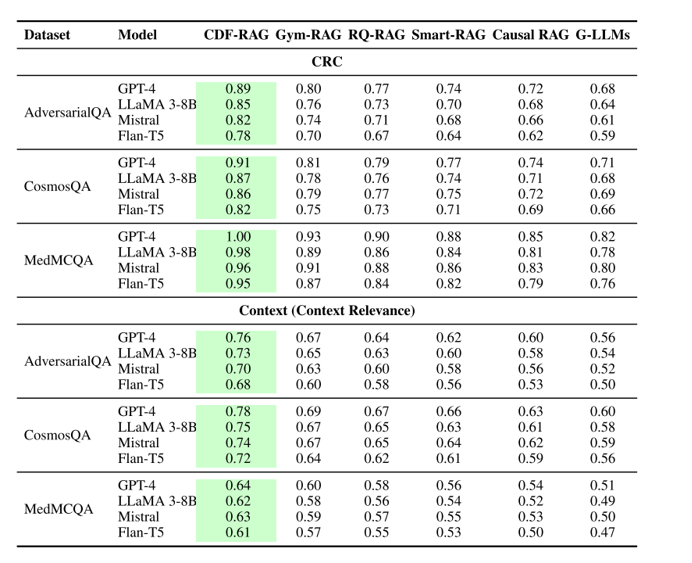
目的:评估因果检索是否真正抓到“方向性”证据而非语义相关噪音。
方法:报告 CRC(因果检索覆盖率)、Context Relevance、Groundedness,用人工黄金因果图校验检索结果。
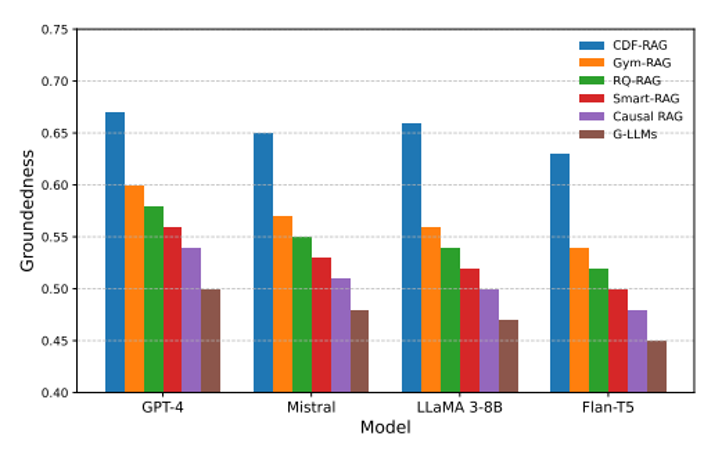
检验 CDF-RAG 能否让不同 LLM(GPT-4→Flan-T5)都生成更贴证据、更少幻觉的答案。在 MedQA 数据集 上,用 Groundedness(答案与检索片段的语义一致性)打分。对比 5 种 RAG 方法 × 4 种模型的柱状图。
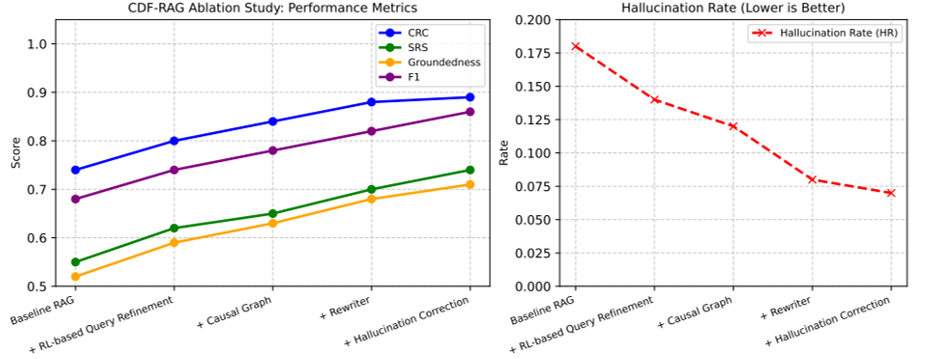
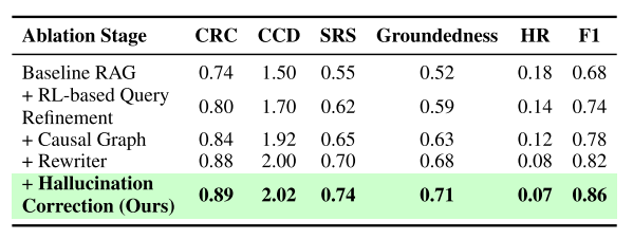
消融实验
目的:量化 RL 查询改写、因果图、知识重写、幻觉修正四模块各自贡献。
方法:逐模块启用,观察 CRC、F1、HR 等 6 项指标变化;用 2 200 条跨域查询验证增益可叠加。
五、论文总结
论文提出了一个因果动态反馈的自适应检索增强框架CDF-RAG,基于 LLM 打造“因果-检索-验证闭环引擎”。关键模块如下:
(1)因果图提取:LLM 抽取因果对,经 GPT-4 校验后写入因果图,构建可动态更新的有向因果图。
(2)RL-查询改写:PPO 策略在 {expand, simplify, decompose} 中决策,用多目标奖励优化检索与因果深度。
(3)双路径检索:MiniLM 语义向量 + 沿图有向遍历,结果合并后经知识重写生成统一知识集 K。
(4)因果-幻觉闭环验证:计算 S_causal 与 S_hallucination,触发重生成或知识重写,确保答案因果一致且零幻觉。
六、对齐思考
(1)双标签因果抽取 :统一 prompt 让 LLM 一次性给每条“经络↔免疫→疾病”三元组同时打上“西医标签(RCT等级)”和“中医标签(证候/经络)”,随后只用一个简单的词典映射表把同名实体对齐。
(2)双链闭环引擎:为“致病链”与“干预链”分别训练 PPO-RL 查询改写器,实时在 {expand, simplify, decompose} 中决策;RAG 沿图检索时每一步都回图验证,冲突即重写;最终将“脾虚”等中医节点与“IL-6↑”等西医指标映射到同一通路,合并输出两条经临床可解释的统一因果链。