来源: IEEE Transactions on Intelligent Vehicles
作者: Kemou Jiang, Xuan Cai, Zhiyong Cui等
发布日期: 2024 年 11 月 6 日
链接:KoMA: Knowledge-Driven Multi-Agent Framework for Autonomous Driving With Large Language Models | IEEE Journals & Magazine | IEEE Xplore
一、背景
随着自动驾驶技术的不断进步,传统的数据驱动方法在自动驾驶中逐渐受到挑战。这些方法往往受制于数据集偏差、过拟合以及缺乏可解释性等问题。
当前研究主要集中于单一Agent简单场景(如直道、高速主路),未能解决多车交互、动态复杂环境下的问题
采用知识驱动的方法,可以模拟人类驾驶者在面临新情境时,运用丰富的经验和逻辑推理能力进行合理判断的能力。
二、论文主要工作
本论文提出KoMA框架,包含五个核心模块:环境模块、交互模块、多步规划模块、共享记忆模块和基于排名的反思模块。这些模块协同工作,提高多个智能体在复杂驾驶场景中的决策能力。
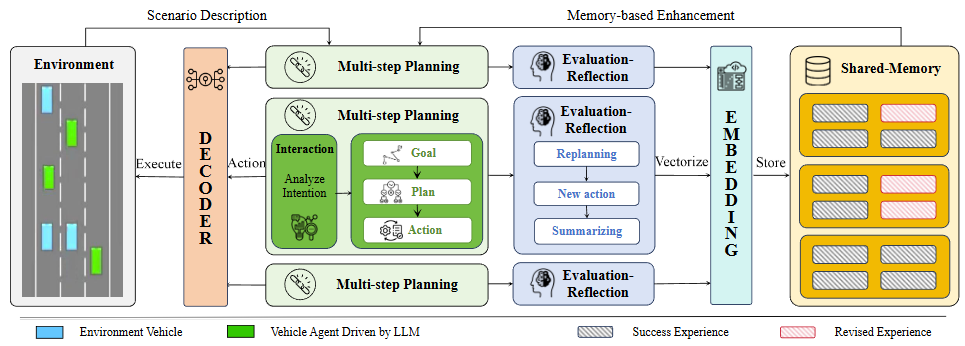
1、环境模块
为各个自主驾驶智能体提供驾驶场景的描述。这些场景描述以文本形式提供,为智能体在做决策时提供必要的上下文信息。
2、多智能体交互模块
该模块处理环境模块返回的文本信息,让智能体能够像人类一样分析其他车辆的行为并推测他们的意图。
3、多步规划模块
模块采用目标-计划-行动(Goal-Plan-Action, GPA)方法,分为三个层次:首先明确目标、制定计划并推导出具体行动决策。
4、共享记忆模块
使用向量数据库存储代理的驾驶经验。这些经验被分为四个关键要素:场景描述、计划过程、最终决策和评估分数。
5、基于排名的反思模块
根据效率和安全性评估每次行动后产生的效果,修正不理想的决策,只保留经过纠正且得分较高的经验
实验设计包括 与深度多智能体强化学习(MARL)对比、消融实验、不同场景泛化测试、不同LLM适应性测试
三、方法

收到来自环境模块的文本描述后,智能体首先使用多智能体交互模块处理信息,分析和猜测其他车辆的意图,然后再将此信息传递给多步规划模块。
多步规划过程为:根据场景和目标提出一系列计划,LLMs给予各种因素评估计划的效率和安全性,选择一个计划指导决策,行动空间中有五个行动:turn-left、IDLE(以当前速度保持在当前车道)、turn-right、acceleration和deceleration。
LLMs基于推理选择一个行动。
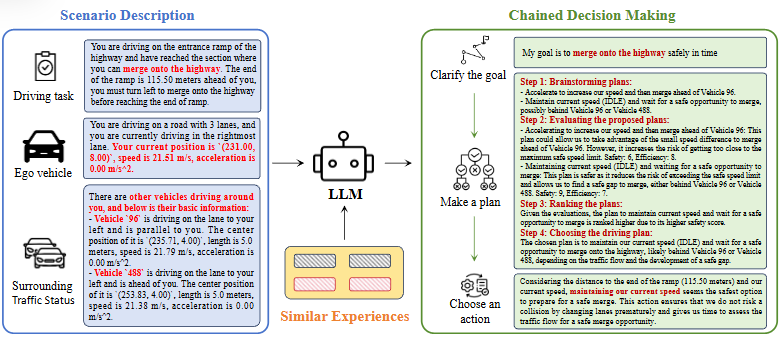
共享记忆模块:每个经验被分为四个关键要素:场景描述、规划过程、最终决策和评估分数。场景的文本描述被转换为向量,作为衡量memory module内相似性的关键。
四、实验
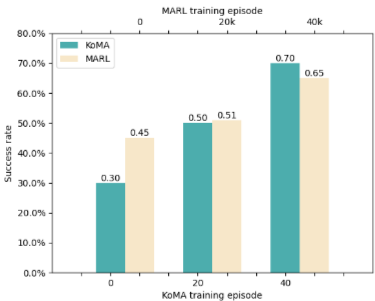
1、通过对 KoMA 和深度多智能体强化学习 (MARL) 进行比较实验来评估框架性能,结果如下:
未训练KoMA成功率30%,MARL为45%;
KoMA仅20轮训练成功率达50%,优于MARL 2万轮训练(51%);
40轮后KoMA达70%,超MARL 4万轮(65%),显示LLM知识驱动高效学习能力;
2、消融实验表明:共享记忆+多步规划提升训练效率及安全/效率评分;
3、泛化实验显示:不同车道数与环岛场景中,KoMA均表现良好(成功率提升20%以上);
4、LLM测试中GPT-4效果最佳,优于GPT-3.5、Llama系列、Qwen系列。

五、论文贡献
1、提出了一个多智能体的知识驱动框架KoMA,促进了智能体间的隐式交互。
2、设计了三层的GPA结构,确保复杂场景中的任务分析和决策连贯性。
3、创新性地引入了安全性和效率指标到反思模块中,提升了决策的精确性和改进能力。
4、通过共享记忆模块,实现了多个智能体经验的快速积累和一致性训练,提升了模型的一般化能力。
六、总结
1、KoMA框架验证了LLM在复杂多Agent自动驾驶场景中的知识推理、意图理解与协作能力;
2、相比传统MARL方法,KoMA训练效率更高、泛化能力更强、可解释性更好;
3、具备很强的迁移潜力,可扩展至其他复杂任务(如机器人群控、智能交通系统等);
4、存在不足:对LLM本身理解交通场景的能力依赖较大,适用于对LLM有良好定制能力的场合。